
краткий анализ эффективности GPU — i2HARD
Статьи • 24 Июня 2020 • Админ ГеннадийПервые 3D-видеокарты появились 25 лет назад, и с тех пор их мощность и сложность выросли в таком масштабе, как ни один другой чип компьютера. В те времена графические процессоры были меньше 100 мм2 размером, имели около 1 миллиона транзисторов и потребляли всего несколько ватт энергии.
Сегодня же типичная видеокарта может иметь 14 миллиардов транзисторов на кристалле размером 500 мм2 и потреблять более 200 Вт энергии. Возможности этих бегемотов будут неизмеримо больше, чем у их древних предшественников, но стали ли они эффективнее со всеми этими транзисторами и ваттами энергии?
Сказка о Двух Числах
В этой статье мы рассмотрим, насколько хорошо разработчики GPU смогли воспользоваться увеличением размеров кристалла и энергопотребления, чтобы предложить нам больше вычислительной мощности. Прежде чем идти дальше, вы можете освежить в памяти устройство видеокарты или пройтись по истории современного GPU. С этой информацией вам будет легче ориентироваться.
Чтобы понять, как менялась эффективность графического процессора, и менялась ли вообще, мы использовали отличную базу данных TechPowerUp, выбрав образцы процессоров за период последних 14 лет. Такой период обусловлен тем, что именно 14 лет назад GPU перешли на унифицированную структуру шейдеров.
Вместо того чтобы выделять отдельные вычислительные блоки процессора для обработки треугольников и пикселей, унифицированные шейдеры являются арифметическими логическими единицами, предназначенными для любых вычислений, связанных с трехмерной графикой. Благодаря этому, мы можем последовательно замерить относительную производительность каждого GPU по параметру количества его операций с плавающей точкой в секунду (FLOPS – FLoating-point Operations Per Second).
AMD использует унифицированную шейдерную архитектуру почти 12 лет
Вендоры часто стараются указывать значения FLOPS в качестве показателя максимальной производительности GPU. И хотя на самом деле это далеко не единственный показатель, определяющий скорость работы графического процессора, FLOPS дает нам цифры, с которыми мы можем работать.
То же касается и размеров кристалла, означающего рабочую площадь чипа. Однако чипы могут быть одинаковы по размеру, но сильно отличаться по количеству транзисторов.
Например, процессор Nvidia G71 (GeForce 7900 GT) 2005 года имеет размер 196 мм2 и имеет 278 миллионов транзисторов, а TU117, выпущенный в начале прошлого года (GeForce GTX 1650), всего лишь на 4 мм2 больше, но в нём 4,7 миллиарда этих маленьких переключателей.
Диаграмма основных GPU Nvidia, показывающая изменения в плотности транзисторов за последние годы
Источник изображения: techspot.com
Естественно, из этого следует, что современные транзисторы намного меньше, чем в старых чипах, и это очень важно. Так называемый технологический процесс – общая разрешающая способность при изготовлении процессора, – используемый производителями оборудования, с годами менялся и постепенно становился все меньше и меньше. Поэтому мы проанализируем эффективность с точки зрения плотности кристалла, которая является мерой того, сколько миллионов транзисторов приходится на один мм2 площади кристалла.
Пожалуй, самым спорным показателем, который мы будем использовать, является показатель энергопотребления GPU. Многие читатели отнесутся скептически, ведь мы используем значение теплопакета (TDP), заявленное производителем. На самом деле это значение отражает (или, по крайней мере, должно отражать) количество тепла, выделяемого в среднем всей видеокартой при высокой нагрузке.
Потребляемая кремниевыми чипами энергия действительно в основном превращается в тепло, но проблема использования TDP не в этом. Дело в том, что разные вендоры указывают это число при разных условиях, не обязательно во время пиковых FLOPS. Кроме того, это значение мощности для всей видеокарты в целом, включая встроенную память, а не только для основного её потребителя – собственно GPU. Можно измерить энергопотребление видеокарты напрямую, как это делали, например, TechPowerUp для своих обзоров GPU. Когда они тестировали GeForce RTX 2080 Super с заявленным производителем TDP 250 Вт, они обнаружили, что энергопотребление в среднем составило 243 Вт, и достигло максимума в 275 Вт во время тестирования.
Но всё-же мы решили учитывать показатель TDP в нашем анализе ради простоты и удобства, условившись весьма осторожно делать любые выводы касаемо производительности, основанные исключительно на её зависимости от номинальной тепловой мощности.
Сейчас мы проведем прямое сравнение по двум показателям: GFLOPS и плотность кристалла. Один GFLOPS равен 1000 миллионам операций с плавающей точкой в секунду, и мы имеем дело со значением для вычислений одинарной точности (FP32), выполняемых исключительно унифицированными шейдерами. Наше сравнение примет форму графика:
Источник изображения: techspot.com
Ось X отображает GFLOPS на единицу TDP – чем больше, тем лучше. Чем меньше, тем нерациональней используется энергопотребление. То же справедливо для оси Y, где у нас GFLOPS на единицу плотности кристалла. Чем больше транзисторов удастся поместить на один квадратный мм, тем выше получится производительность. Таким образом, общая эффективность работы GPU (учитывая количество транзисторов, размер кристалла и TDP) возрастает по мере приближения к правому верхнему углу графика.
Все значения в районе верхнего левого угла в основном говорят о том, что «благодаря вычислительной мощности кристалла, этот GPU обеспечивает хорошую производительность, но за
счет использования от
Как узнать характеристики видеокарты?
Windows, Windows 10, Windows 7, Windows 8, Windows Server, Windows Vista, Windows XP, Железо- Reboot
- 28.02.2019
- 6 712
- 0
- 23.04.2020
- 7
- 7
- 0

Всем привет! Сегодня продолжение предыдущей статьи. Напомню, там шла речь о том, как просто и быстро узнать конфигурацию компьютера. Некоторые не согласятся, почему в названии статьи шла речь о конфигурации всего компьютера, а не процессора. В принципе в CPU-Z дана исчерпывающая информация о характеристиках процессора, но также можно узнать кое-что о памяти, материнской плате и видеокарте. Характеристики жесткого диска можно легко узнать с помощью программы HD Tune Pro, которую мы уже рассматривали. В отличии от параметров остальных комплектующих компьютера они могут несколько отличаться от данных, которые указаны на сайте производителя.
Утилита GPU-Z
В этой статье мы будем рассматривать утилиту, которая предоставляет такие же исчерпывающие характеристики видеокарты, как и CPU-Z – характеристики процессора. Это чудо-программка – GPU-Z. По названию можно предположить, что CPU-Z и GPU-Z разрабатывались одной и той же компанией. Однако это не так. Фирмы не имеют ничего общего, но дизайн интерфейса выполнен в едином ключе.
Скачать GPU-Z с официального сайта
Предупреждение! Эта программа постоянно обновляется для добавления в базу данных нового железа. Т.е. в случае использования старой версии утилиты на новом железе большинство его характеристик вероятнее всего не определится (если комплектующие были выпущены после даты выхода утилиты).
GPU-Z содержит всего две вкладки, несущие максимум полезной информации. Рассматривать программу я буду на примере видеокарты ATI Radeon HD 4650.
Вкладка Graphics Card
Эта вкладка открывается по умолчанию при запуске программы.

Здесь находится куча параметров, которые мы и будем рассматривать по порядку. Приготовьтесь к небольшому мозговому штурму.
- Name – название серии видеокарты. К примеру, в серию HD 4600 входят две видеокарты – 4650 и 4670.
- GPU – кодовое имя чипа (RV730). У разных чипов разная компоновка блоков ALU, TMU, ROP и т.п. Соответственно, и производительность видеокарт с одинаковыми характеристиками на разных чипах будет отличаться.
- Revision
- Technology – техпроцесс, по которому изготовлен видеочип. Измеряется в нанометрах. Чем меньше он будет, тем больше транзисторов можно будет уместить на единицу площади. Соответственно, видеокарту можно сделать производительнее либо уменьшить энергопотребление.
- Die Size – площадь ядра видеокарты.
- Release Date – дата выхода видеокарты.
- Transistors – количество транзисторов в видеочипе. Исчисляется в миллионах или миллиардах. Буква «М» возле числа 514 обозначает 514 миллионов. В современных видеокартах количество транзисторов может доходить до 4.5 миллиардов. Соответственно, число будет четырехзначным.
- BIOS Version – версия BIOS видеокарты. При нажатии на чип с зеленой стрелочкой можно сохранить BIOS (Save to file…). Файл сохранится в формате «имя чипа.rom». Открыть его можно, например, с помощью программы TechPowerUp Radeon Bios Editor. Там можно изменить, к примеру, частоты по умолчанию и загрузить обратно. Сам такое не практиковал и вам не советую, если нет опыта. При пропадании питания во время перепрошивки видеокарта может прийти в негодность (то же касается и BIOS материнской платы). В современных топовых видеокартах AMD имеется встроенный BIOS без возможности перепрошивки и еще один с таковой. В случае чего видеокарта всегда сможет заработать с заводскими настройками. Это такой реверанс в сторону оверклокеров.
- Device ID – идентификатор ядра видеокарты, используемый программистами для обращения к устройству.
- Subvendor – название фирмы-производителя. Nvidia и AMD создают только референсные видеокарты, которые потом передаются многочисленным производителям (Asus, Gigabyte, MSI, Palit…). Те в свою очередь разрабатывают свою систему питания, охлаждения, устанавливают свои частоты, тип и количество памяти и поставляют на рынки в виде готового продукта.
- ROPs/TMUs – количество блоков растеризации и текстурирования. ROP – это блоки растеризации, записывающие посчитанные на видеокарте пиксели в буферы. TMU – блоки, выбирающие текстурные данные, необходимые для построения текущей картинки. Чем больше будет этих блоков, тем лучше. Косвенно оценивать производительность видеокарт по количеству этих блоков можно только в пределах одного производителя (AMD или Nvidia). Собственно, как и все остальные параметры.
- Bus Interface – отображается интерфейс, который поддерживается видеокартой. В моем случае PCI-express 2.0 x16. За знаком «@» указывается, какое подключение используется сейчас. Т.е. видно, что у меня используется только 8 линий PCI-e из 16 доступных. На производительных видеокартах будет х16 подключение. Если материнская карта поддерживает менее 32 линий PCI-e, то в режиме SLI/CrossFire (одновременной работы двух видеокарт) может быть небольшое снижение производительности графической подсистемы. При нажатии на знак «?» рядом с типом интерфейса откроется окно, в котором можно будет нагрузить видеокарту на 100%, что послужит отличным стресс-тестом.
- Shaders – шейдеры (процессоры) – основные части видеочипа. Именно в этих процессорах производятся все расчеты. Их количество напрямую влияет на графическую производительность и при прочих равных условиях зависимость производительности от количества процессоров будет линейной.
- DirectX Support – версия DirectX (набора интерфейсов программирования приложений, в частности, компьютерных игр). Чем выше будет версия, тем более реалистичной будет картинка в игре и тем требовательнее будет игра к ресурсам видеокарты. То бишь, если в игре не хватает производительности и в настройках выбирается версия DirectX, то можно убрать красивости (не много), выбрав предыдущую версию.
- Pixel Fillrate – пиксельная скорость заполнения. С этой скоростью видеочип отрисовывает пиксели. Измеряется в GPixel/s (гигапикселях в секунду). Вычисляется по формуле: Pixel Fillrate = ROPs*GPU Clock.
- Texture Flillrate – с этой скоростью выбираются текстуры для отрисовки картинки. Измеряется в GTexel/s (гигатекселях в секунду). Соответственно, формула: Texture Fillrate = TMUs*GPU Clock.
- Memory Type – тип видеопамяти. Определяет быстроту видеопамяти. Самый производительный тип – GDDR5. Огромные вычислительные мощности будут простаивать при медленной видеопамяти. При компромиссном выборе между количеством памяти и ее типом в приоритете должен быть тип.
- Bus Width – ширина канала передачи данных между графическим процессором и видеопамятью.
- Memory Size – объем видеопамяти.
- Bandwidth – максимальная пропускная способность, которая обеспечивается при передаче данных между процессором и памятью и наоборот. Зависит от типа памяти и ширины канала.
- Driver Version – версия установленного видеодрайвера. Чем новее, тем лучше. Достаточно часто с обновлением драйверов производительность может вырасти на 5-15%.
- GPU Clock – текущая частота графического процессора.
- Memory – текущая частота видеопамяти.
- Default Clock – частота графического процессора, установленная в BIOS по умолчанию.
- Memory — частота видеопамяти, установленная в BIOS по умолчанию.
- ATI CrossFire (Nvidia SLI) – включенный или отключенный режим CrossFire/SLI при одновременном подключении 2/3/4 видеокарт.
- Computing – поддержка различных технологий, используемых для ускорения отдельных игровых эффектов или в общецелевых приложениях. Как пример можно привести программу кодирования видео vReveal, использующая технологию CUDA для ускорения.
Вкладка Sensors
На этой вкладке регистрируются изменения параметров в виде графиков в режиме реального времени.

- GPU Core Clock – частота ядра (Shader) видеокарты.
- GPU Memory Clock – частота видеопамяти.
- GPU Temperature – температура видеочипа.
- Fan Speed (%) – скорость вращения кулера видеокарты в % от максимального.
- Fan speed (rpm) — скорость вращения кулера видеокарты в оборотах/минуту.
- GPU Load – нагрузка на видеокарту (в %). В предыдущей вкладке при нажатии на «?» и запуске теста GPU Load поднимается до 100% и держится постоянно. Это стрессовый (максимальный) режим. Даже в тяжелых играх этот параметр опускается ниже 100%.
- GPU Temp. #1/2 – температуры в разных частях видеочипа.</li?
- Memory Usage (Dedicated) – использование памяти, выделяемой из системной для нужд видеокарты.
- Memory Usage (Dynamic) – использование видеопамяти.
- VDDC – напряжение графического ядра видеокарты. При повышении этого напряжения можно обеспечить более стабильную работу при повышенных частотах (разгоне) или спалить видеокарту.
Внизу можно поставить галочку напротив «Log to file«. Я, например, запустил простенькую игрушку Fallout 2. После выхода из игры у меня был файл под названием «GPU-Z Sensor Log«, где были записаны все параметры видеокарты с шагом в одну секунду.
Галочку напротив «Continue refreshing this screen while GPU-Z is in the background» также можно поставить. При сворачивании утилиты в трей графики будут продолжать формироваться на основе информации с датчиков.
В правом верхнем углу есть значок фотоаппарата. Это встроенное средство создания скриншотов. Два скриншота в этой статье были созданы с помощью этой функции.
Вывод
GPU-Z наряду с CPU-Z является незаменимым быстрым инструментом системного мониторинга. С помощью этих двух утилит можно посмотреть, что происходит с компьютером при разных условиях.
Проблемы метрики «количество транзисторов на чипе» / Хабр
В техноиндустрии количество транзисторов и плотность транзисторов часто используют для демонстрации технического достижения и некой вехи в развитии. После выхода нового процессора или системы на чипе многие производители начинают хвастать сложностью своей схемы, измеряя количество транзисторов в ней. Недавний пример: когда компания Apple выпустила iPhone 11 с A13 Bionic внутри, она похвалялась тем, что процессор содержит 8,5 млрд транзисторов. В 2006 Intel сходным образом хвасталась Montecito, первым процессором с миллиардом транзисторов.
По большей части это постоянно увеличивающееся количество транзисторов является следствием закона Мура и мотивацией к дальнейшей миниатюризации. Индустрия переходит на новые техпроцессы, и количество транзисторов на единицу площади продолжает расти. Поэтому количество транзисторов часто считается показателем здоровья закона Мура, хотя это на самом деле и не совсем корректно. Закон Мура в оригинальном виде – это наблюдение, согласно которому количество транзисторов экономически оптимального дизайна (т.е. с минимальной стоимостью одного транзистора) удваивается каждые два года. С точки зрения потребителя, закон Мура – это на самом деле обещание того, что завтрашние процессоры будут лучше и ценнее сегодняшних.
В реальности плотность транзисторов значительно колеблется в зависимости от типа чипа, и особенно от способа компоновки самого чипа. Что ещё хуже, не существует стандартного способа подсчёта транзисторов, из-за чего для одной и той же схемы эти цифры могут отличаться на 33-37%. В итоге количество транзисторов и плотность транзисторов – это лишь приблизительные метрики, и если замкнуться только на них, можно потерять из виду общую картину.
На компоновку продукта влияет его предназначение
Плотность транзисторов тесно связана с предназначением и стилем разработки продукта. Будет, по меньшей мере, некорректно сравнивать такие сильно отличающиеся друг от друга компоновки, как ASIC с фиксированным быстродействием (к примеру, Broadcom Tomahawk 4 25.6Tb/s или Cisco Silicon One 10.8Tb/s) и высокоскоростной процессор для дата-центров (к примеру, Intel Cascade Lake или Google TPU3).
От ASIC требуется поддержка определенной пропускной способности, а увеличение частоты не приносит ему пользы. К примеру, чип Cisco Silicon One предназначен для высокоскоростных сетей, использующих 400Gbps Ethernet, и от увеличения частоты на 10% он ничего не выиграет. 400Gbps – это стандарт IEEE, а следующая ступень скоростей – уже 800Gbps. В итоге большинство команд разработки ASIC оптимизируют чипы по минимуму стоимости, автоматизации инструментов разработки, уменьшению количества специальных схем и плотности транзисторов.
И наоборот, чем быстрее серверный чип, тем больше он стоит, и поэтому он всегда будет получать преимущество от увеличения частоты. К примеру, Xeon 8268 и 8260 – 24-ядерные процессоры, и отличаются в основном базовой частотой (2,9 ГГц и 2,4 ГГц), в результате чего их стоимость отличается на $1600. Поэтому команда разработки серверов будет стремиться к оптимизации по частоте. Высокоскоростные процессоры обычно используют больше специальных схем и более крупные транзисторы. В современных схемах на базе FinFET это даёт увеличение количества транзисторов с 2, 3 плавниками, и даже больше. И наоборот, низкоскоростная логика, типа параллельных GPU или ASIC чаще использует более плотную компоновку транзисторов всего с одним плавником, принося в жертву тактовую частоту для увеличения плотности. Транзисторы с низкой утечкой также обычно имеют больший размер.
Плотность и количество транзисторов определяются балансом разработки
Ещё больше влияет на количество транзисторов и плотность транзисторов реальная компоновка чипа. Каждый современный чип состоит из какой-то комбинации логики для вычислений, памяти (обычно SRAM) для хранения и I/O для передачи данных. Однако по плотности три этих компонента значительно разнятся – см. таблицу 1. У Poulson и Tukwila одна платформа, одинаковые цели, связанные с высокой скоростью работы, и высочайший уровень надёжности.
Таблица 1: количество транзисторов и плотность транзисторов основных участков поколений Poulson и Tukwila процессора Itanium
Процессоры состоят из четырёх основных участков: ядра CPU, кэш L3, системный интерфейс и I/O. Судя по раскрытой производителем информации, у Poulson на кристалле есть ещё 18 мм2 для других функций. Участок ядер CPU содержит ядра и оптимизированные по быстродействию кэши L1 и L2, и основное место там занимает высокоскоростная логика для операций свыше 1,7 ГГц для Tukwila и 2,5 ГГц для Poulson. Крупные кэши L3 (24 Мб для Tukwila и 32 Мб для Poulson) разработаны для максимальной ёмкости и используют самые плотные ячейки 6T SRAM из возможных. В системном регионе находится большой ассортимент функций – матричный переключатель для передачи данных I/O и памяти по кристаллу, QPI и контроллеры памяти, протокол когерентности с использованием справочника и кэши справочника, модули управления питанием. Системный участок обычно не такой плотный, поскольку логика там работает на фиксированной частоте, и во многих из более крупных компонентов высокоскоростные шины, пересекающие кристалл, занимают больше места, чем транзисторы. И, наконец, регион I/O содержит физические интерфейсы для внешних коммуникаций, реализованных через высокоскоростные последовательные связи (QPI links). Связи по-разному передают сигналы, и в сумме у них набирается порядка 600 контактов.
В количественном плане два этих процессора иллюстрируют критически важные тренды, которых придерживаются практически все крупные разработчики чипов. Во-первых, в различных частях чипа плотность транзисторов может отличаться в разы – более, чем в 20 раз, что во много раз больше, чем упоминаемое в законе Мура удвоение плотности, связанное с улучшением процессоров на одно поколение. Естественно, самым плотным участком является регион кэша, состоящий из сверхплотной SRAM – он и содержит большинство транзисторов. Кэш примерно в 3-5 раз плотнее, чем вычислительная логика в ядрах, что опять-таки больше, чем удвоение. Наименее плотная часть – это I/O, поскольку там содержатся деликатные аналоговые схемы типа PLL и DLL, цифровые фильтры, и крупные I/O транзисторы высокого напряжения, которые используются для отправки данных с чипа и получения им данных. Кроме того, многие участки I/O должны занимать достаточно места по краям чипа, чтобы их можно было соединить со всеми контактами, и занимаемая ими площадь определяется количеством контактов, а не плотностью схем.
Данные выше демонстрируют, что плотность транзисторов современных чипов является в основном функцией их предназначения и компоновкой самого чипа. Для экстремального примера представьте себе 32 нм схему, основанную на Poulson, но не имеющую кэша L3 – плотность транзисторов такого чипа равнялась бы примерно 2,57 млн/мм2, или менее половины реальной плотности Poulson. И в другую сторону – гипотетический вариант Poulson, содержащий только вычислительную логику и кэш, без системы I/O, имел бы плотность транзисторов порядка 9 млн/мм2.
Таблица 2: количество транзисторов и плотность транзисторов для некоторых чипов на 7 нм и 12 нм, по сообщению производителей
В таблице 2 содержатся подробности о нескольких чипах, произведённых по техпроцессам 7 нм и 12 нм от TSMC, подчёркивающие влияние компоновки чипа на плотность транзисторов. Radeon VII и RX 5700 от AMD похожи по компоновке, используют один техпроцесс, и их плотность транзисторов почти одинаковая. Плотность транзисторов у AMD Renoir и Nvidia A100 в 1,5 раза больше – возможно, поскольку это было целью разработчиков, или, возможно, благодаря более современным инструментам разработки. Ещё одно полезное сравнение — Nvidia V100 GPU и NVSwitch, 18-портовый коммутатор от NVLink. Техпроцесс у них один, однако последний в основном ориентирован на I/O, и в результате плотность транзисторов у V100 в 1,37 раза больше, чем у NVSwitch.
Наконец, SoC от двух смартфонов в 1,35 – 2,29 раз плотнее, чем остальные процессоры на 7 нм. Эта впечатляющая плотность достигнута благодаря разным целям оптимизации. SoC смартфонов делают так, чтобы они были подешевле, а их плотность была повыше. Процессоры AMD стремятся к высокой производительности. Кроме того, компании Apple и HiSilicon крупнее и богаче, они могут позволить себе большие команды разработчиков и большие траты на оптимизацию. Однако возможно также, что количество транзисторов и плотность транзисторов у мобильных SoC отличаются потому, что для них транзисторы считают по-другому. Последний столбец таблицы 2 показывает, как именно производитель подсчитывает количество транзисторов – мы подробнее обсудим это чуть позже.
Не все транзисторы созданы равными
Ещё одна проблема использования подсчёта количество транзисторов или плотность транзисторов в качестве метрики состоит в том, что эти цифры неоднозначны и могут ввести в заблуждение. Обычно мы представляем себе транзисторы в виде физической реализации логических блоков и схем. При вычислениях этим можно обозначить всё что угодно – от ядра процессора или модуля работы с плавающей запятой до инвертера. Для хранения это может быть кэш, регистровый файл, ассоциативное запоминающее устройство (content-addressable-memory, CAM) или битовая ячейка SRAM. Для аналоговых компонентов или I/O это может быть PLL, или передатчик/приёмник, расположенные вне чипа. Транзисторы, физические реализующие эти блоки, называют активными транзисторами (в отличие от схематических транзисторов). Однако в реальности не все транзисторы созданы равными, и современные процессоры производятся со множеством неактивных транзисторов. Транзисторы, формирующиеся в процессе изготовления называют макетными. Макетные транзисторы – это описанные выше активные транзисторы, но также среди них есть и фиктивные транзисторы, а также транзисторы, используемые в качестве развязывающих конденсаторов.
Фиктивные транзисторы вставляют в схему для повышения эффективности производственного процесса. К примеру, определённые шаги отжига и травления в процессе производства лучше работают на относительно однородной поверхности, и если вставить дополнительные транзисторы в пустые места, это увеличит однородность. Для многих аналоговых схем такие транзисторы нужны для достижения желаемой эффективности. Ещё пример – эффективность современных FinFET зависит от нагрузки на транзисторы, являющейся функцией транзисторов, находящихся поблизости. Для достижения нужной эффективности иногда приходится разместить несколько транзисторов поблизости, чтобы получить нужную нагрузку.
Хотя фиктивные транзисторы повсеместно применяются, их используют не так уж много. А вот развязывающие конденсаторы на основе MOSFET используются повсеместно. В целом логика современного чипа никогда не достигает 100% пространственной эффективности. При всех чудесах современных средств разработки всё равно останутся пустые места между отдельными логическими ячейками (к примеру, между вентилями NAND), между функциональными модулями (кэш L1D), и даже между целыми блоками (например, ядрами CPU). Пустое пространство возникает вследствие того, что инструменты разработки пытаются удовлетворить правилам, гарантирующим эффективное производство и частоту, использовать доступные ресурсы (например, маршрутные слои) и собрать электромеханическую головоломку из логических клеток, функциональных модулей и блоков. Пустое пространство может занять до 10-25% чипа. Для увеличения выхода годных изделий кристаллы должны быть относительно однородными, и пустое пространство не может оставаться реально пустым. Многие схемы заполняют эти места развязывающими конденсаторами, чтобы улучшить обеспечение питанием. Кроме того, в некоторых схемах развязывающие конденсаторы располагают внутри стандартных библиотек ячеек. Транзисторы в роли развязывающих конденсаторов – основной источник неактивных макетных транзисторов, однако точные данные по их количеству сложно найти.
Наши друзья из TechInsights провели технический анализ процессора на уровне схемы, в который входил и подсчёт макетных транзисторов на небольшом участке кристалла. Они поделились своими открытиями для небольшого списка SoC на 7 нм. Данные основаны на небольшом количестве избранных мест с каждого из SoC, обычно с GPU, где плотность транзисторов должна быть наибольшей. Они обнаружили, что в изученных ими местах порядка 70-80% транзисторов были активными, а оставшиеся 20-30% — развязывающими конденсаторами или фиктивными. Однако эти цифры основаны на небольшом количестве выборок, поскольку подобный анализ требует большого количества денег и времени. Чтобы подтвердить эти цифры и развить тему, мы собрали данные по нескольким современным схемам, и обнаружили, что обычно процент активных транзисторов составляет 63-66 от общего количества, а 33-37% транзисторов – развязывающие конденсаторы. Числа у TechInsights получились ниже, вероятно, потому, что они изучали наиболее плотные логические участки SoC, и не учитывали пустое пространство, где могло оказаться больше развязывающих конденсаторов.
Таблица 2: количество транзисторов и плотность транзисторов для некоторых чипов на 7 нм и 12 нм, по сообщению производителей
Из этих данных совершенно ясно следует, что между количеством активных и макетных транзисторов в чипе часто есть большая разница. К сожалению, многие компании обычно не указывают, число каких транзисторов они учитывают. Данные по процессорам от AMD и Nvidia из Таблицы 2 взяты из технических документаций. На основе неформального обсуждения этого вопроса с двумя этими производителями, мы привели число активных транзисторов в последнем столбце. Судя по всему, число транзисторов, указанное для HiSilicon Kirin 990 5G, может означать макетные транзисторы, что может объяснить несоответствие между этими схемами. Непонятно, реализован ли чип Apple A13 с использованием 8,5 млд активных или макетных транзисторов. В первом случае их достижение по плотности было бы впечатляющим.
Кажется неразумным учитывать эти фиктивные транзисторы и развязывающие конденсаторы наравне с активными транзисторами. Активные транзисторы реализуют функции и особенности, ценимые пользователями – будь то ядра CPU, выборочное отключение питания для улучшения энергопотребления в режиме простоя, ускорители нейросетей или кэш. Однако фиктивные транзисторы и развязывающие конденсаторы – это просто лишние компоненты, не добавляющие прямой ценности, а в некоторых случаях даже проигрывающие более сложным технологиям. К примеру, траншейные конденсаторы от IBM гораздо эффективнее развязывающих конденсаторов, и позволяют создавать плотные чипы eDRAM, уменьшая стоимость системы. Intel FIVR увеличивает эффективность платформы и полагается на MIM-конденсаторы, практически устраняя необходимость в развязывающих конденсаторах, а также, вероятно, уменьшает количество развязывающих конденсаторов, необходимых на кристалле. В обоих случаях уменьшение количества развязывающих конденсаторов приносит пользу. Суть закона Мура состоит в том, чтобы создавать ценность для потребителей, продуктивно используя дополнительные активные транзисторы, а фиктивные транзисторы и развязывающие конденсаторы этой ценности не добавляют.
Дело не в том, сколько там транзисторов, а в том, как вы их используете
Подводя итоги, Становится видно, что количество транзисторов и плотность транзисторов – метрики весьма проблемные. На них сильно влияет общая компоновка чипа и объёмы критически важных блоков – вычислительной логики, SRAM, I/O. SRAM наиболее плотная из всех трёх, поэтому небольшое изменение размера кэша сильно изменит количество транзисторов, при этом практически не повлияв на быстродействие и ценность. Более того, не все макетные транзисторы созданы равными. Активные транзисторы – это фундаментальные строительные блоки таких ценных компонентов, как CPU и GPU. С другой стороны, фиктивные транзисторы и развязывающие конденсаторы больше похожи на лишний груз. Надеюсь, что большинство компаний не будут объединять активные и макетные транзисторы, но важно отличать два этих типа при сравнении схем.
Несмотря на все проблемы с количеством транзисторов, эта метрика потенциально полезна в очень редких случаях. Почти всегда процессор с 100 млрд транзисторов будет сложнее и ценнее процессора с 100 млн транзисторов. Вероятно, анализ всё ещё остаётся верным для двукратной разницы в количестве транзисторов – особенно для чипов, обрабатывающих задачи параллельно, типа GPU, или для двух очень похожих процессоров (к примеру, двух SoC для смартфонов или двух серверных процессоров). Но сложно поверить, что небольшое различие в количестве транзисторов обязательно приведёт к наличию разницы в ценности. На самом деле отличным примером могут служить Radeon VII и RX 5700 от AMD. У Radeon VII на 28% больше транзисторов, однако быстродействие у него почти такое же, в частности из-за того, что в линейке RX 5700 используется более современная архитектура. Кроме того, RX 5700 оказывается гораздо дешевле, поскольку использует GDDR6 вместо HBM2. Реальная ценность для потребителей заключается не в количестве транзисторов, а в том, как они используются. Небольшие различия в количестве транзисторов не имеют значения по сравнению с хорошей архитектурой, выбором функций и другими факторами.
Многие из этих критических утверждений верны и для плотности транзисторов, и для техпроцессов. Если небольшое увеличение в количестве транзисторов не обязательно влияет на пользовательскую ценность, то вряд ли на это повлияет соответствующее небольшое увеличение в плотности. С другой стороны, такие факторы, как эффективность транзисторов, динамическое питание, энергопотребление в простое, инструменты разработки, доступность подложек и передовые свойства могут придать большую ценность. Плотность – всего лишь один из множества аспектов процесса, и если зацикливаться на нём, то можно за деревьями не заметить леса.
См. также:
Техпроцесс видеокарты что это такое и на что он влияет?
Опубликовано 1.10.2018 автор Андрей Андреев — 0 комментариев
Привет, друзья! Возможно, погружаясь в тематику компьютерного железа, вы встречали такое понятие как техпроцесс видеокарты, что это такое, на что влияет и какой из них лучший, расскажу в сегодняшней публикации. Все готово, поехали.)

Где там транзисторы
Любой процессор состоит из огромного количества микроскопических транзисторов – что ЦП, что графический чип. Однако транзисторы здесь не совсем привычные – например, не такие, как в радиоприемнике. Реализованы они на куске кремния, из которого состоит процессор.
Сегодня размеры этих компонентов измеряются уже в нанометрах – одной миллиардной части метра – например, 40 нм, 22 нм или 16 нм. Чем меньше цифра, тем тоньше техпроцесс и тем больше транзисторов умещается на той же площади кристалла.
Вообще, техпроцессом называется совокупность действий оборудования по изготовления какой-либо детали, в нашем случае микросхемы. Однако применительно к процессорам и графическим чипам такое обозначение – разрешение печатного оборудования, которое создает компоненты на поверхности кристалла.
Как узнать техпроцесс конкретной детали? Он всегда указан в сопроводительной документации.
Однако учитывайте, что во многих интернет-магазинах, в характеристиках товара этого параметра нет, поэтому при заказе комплектующих, необходимо уточнять детали у консультанта. Как вариант, можно узнать эту информацию на официальном сайте производителя.
Влияние техпроцесса
Технологии делаются все совершеннее, позволяя уменьшить техпроцесс, увеличив тем самым количество транзисторов на одной и той же площади. Что значит это в практическом плане? Увеличение количества транзисторов позволяет увеличить количество логических блоков и тем самым производительность процессора при тех же физических размерах. Как вариант, можно не изменять количество транзисторов, но уменьшить размеры компонента.
Увеличение количества транзисторов позволяет увеличить количество логических блоков и тем самым производительность процессора при тех же физических размерах. Как вариант, можно не изменять количество транзисторов, но уменьшить размеры компонента.
При уменьшении размеров транзисторов, снижается тепловыделение и энергопотребление. Благодаря этому, можно увеличить количество ядер процессора без риска перегрева, что негативно сказывается на производительности. Особенно это актуально для лэптопов и планшетов – да, в крутых моделях тоже установлены видеокарты, созданные по тому же принципу.
Переход на новый, более совершенный техпроцесс, требует от производителя железа проведения фундаментальных исследований, разработки нового оборудования, его создания и обкатки.
По этой причине новые модели центральных и графических процессоров стоят чрезвычайно дорого. Но за то, чтобы быть на гребне волны прогресса, никаких денег не жалко, не правда ли?
Также хочу акцентировать внимание на том, что обкатка нового техпроцесса происходит не сразу, и поэтому первые партии новых комплектующих могут получиться откровенно неудачными.
При увеличении площади кристалла, сложность только возрастает. Увы, лепить многоядерные процессоры по новой технологии вот так «с лету», не получится – никто не хочет работать себе в убыток и разбираться потом с возмущенными покупателями.
Дальнейшие перспективы
Некоторые из вас, вероятно, подумали, что развитие технологий – дело времени, и техпроцесс можно уменьшать до бесконечности. Увы, это не совсем верно. Физические свойства материи имеют определенные рамки, и со временем настанет тот предел, меньше которого создавать транзисторы, попросту не получится. Вот только каким будет их размер и когда это будет – пока не совсем понятно. Вполне вероятно, что к тому времени изобретут какую-нибудь принципиально иную технологию, а процессоры на основе кремниевого кристалла канут в Лету, как это случилось с ламповой электроникой.
Вот только каким будет их размер и когда это будет – пока не совсем понятно. Вполне вероятно, что к тому времени изобретут какую-нибудь принципиально иную технологию, а процессоры на основе кремниевого кристалла канут в Лету, как это случилось с ламповой электроникой.
Надеюсь, исходя из вышеизложенного, вам уже понятен ответ на вопрос: 14 нм или 28 нм – что лучше. Если я не вполне понятно излагал свои мысли, то лучше 14 нм, однако стоят, созданные по такому техпроцессу компоненты, дороже.
А вообще, чтобы разобраться, какой девайс вам лучше купить при сборке или апгрейде компа, советую ознакомиться с публикациями «Из чего состоит современная видеокарта для ПК» и «Правильный выбор видеокарты по параметрам для компьютера». О том, где лучше покупать комплектующие для системного блока, вы можете почитать здесь.
В качестве возможного варианта, советую обратить внимание на видеокарты серии 1060 – например, ASUS GeForce GTX 1060 DUAL OC [DUAL-GTX1060-O3G]. За приемлемую цену вы сможете с комфортом обрабатывать видеоролики и запускать новые игры (правда, некоторые из них не на максимальных, а на средних настройках качества графики). На ближайшие несколько лет такого девайса, вам хватит с головой, я это гарантирую.
На этом я с вами прощаюсь. Не забудьте поставить лайк репосту этой статьи в социальных сетях. Также подпишитесь на новостную рассылку, чтобы быть в курсе последних обновлений моего чрезвычайно полезного блога.
С уважением, Андрей Андреев
Закон количества транзисторов в процессорах (закон Мура) в цифрах и графиках
Закон Мура — наблюдение (изначально сформулированное Гордоном Муром), согласно которому количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые 24 месяца.
Отметим, что часто цитируемый интервал в 18 месяцев связан с прогнозом Давида Хауса из Intel, по мнению которого, производительность процессоров должна удваиваться каждые 18 месяцев из-за сочетания роста количества транзисторов и увеличения тактовых частот процессоров.
Посмотрим, как выполняется правило:
| Год | Количество транзисторов в процессоре |
| 1971 | 2 300 |
| 1974 | 5 000 |
| 1978 | 29 000 |
| 1982 | 134 000 |
| 1985 | 275 000 |
| 1989 | 1 180 000 |
| 1993 | 3 100 000 |
| 1997 | 8 800 000 |
| 2001 | 45 000 000 |
| 2005 | 228 000 000 |
| 2009 | 904 000 000 |
| 2013 | 4 200 000 000 |
| 2017 | 19 200 000 000 |
Фактически, данные подчиняются следующей формуле:
- P(n) = P(o) * 2^n
- P(n) = количество транзисторов в текущем периоде
- P(o) = количество транзисторов в начальном периоде,
- n = количество прошедших лет, деленное на 2
например,
- P(2017) = P(1971) * 2^(46/2)
- P(2017) = 2300 * 2^(23)
P(2017) = 19293798400, что примерно соответствует актуальному значению на 2017 год = 19200000000 транзисторов на кристалл.
Исполнение закона Мура в 1971-2018 годах
В 1965 году (через шесть лет после изобретения интегральной схемы) один из основателей Intel Гордон Мур в процессе подготовки выступления нашел закономерность: появление новых моделей микросхем наблюдалось спустя примерно год после предшественников, при этом количество транзисторов в них возрастало каждый раз приблизительно вдвое.
Он предсказал, что к 1975 году количество элементов в чипе вырастет до 216 (65536) с 26 (64) в 1965 году. Мур пришел к выводу, что при сохранении этой тенденции мощность вычислительных устройств за относительно короткий промежуток времени может вырасти экспоненциально.Это наблюдение получило название — закон Мура.
В 1975 году Гордон Мур внёс в свой закон коррективы, согласно которым удвоение числа транзисторов будет происходить каждые два года (24 месяца).
Существует масса схожих утверждений, которые характеризуют процессы экспоненциального роста, также именуемых «законами Мура». К примеру, менее известный «второй закон Мура», введённый в 1998 году Юджином Мейераном, который гласит, что стоимость фабрик по производству микросхем экспоненциально возрастает с усложнением производимых микросхем.
Стоимость фабрики, на которой корпорация Intel производила микросхемы динамической памяти ёмкостью 1 Кбит, составляла $4 млн, а оборудование по производству микропроцессора Pentium по 0,6-микрометровой технологии с 5,5 млн транзисторов обошлось в $2 млрд. Стоимость же Fab32, завода по производству процессоров на базе 45-нм техпроцесса, составила $3 млрд.
По поводу эффектов, обусловленных законом Мура, в журнале «В мире науки» как-то было приведено такое интересное сравнение: «Если бы авиапромышленность в последние 25 лет развивалась столь же стремительно, как промышленность средств вычислительной техники, то сейчас самолёт Boeing 767 стоил бы 500 долл. и совершал облёт земного шара за 20 минут, затрачивая при этом 20 литров топлива. Приведенные цифры весьма точно отражают снижение стоимости, рост быстродействия и повышение экономичности ЭВМ».
Рост числа транзисторов на кристалле микропроцессора (1970-2016). Точки соответствуют наблюдаемым данным, а прямая — периоду удвоения в 24 месяца.
На графике отображены данные о количестве транзисторов в процессорах, производительности, потреблению энергии, количеству логических ядер.
Вместе с тем на прошедшей в рамках выставки CES 2019 пресс-конференции, глава компании NVIDIA Дженсен Хуанг (Jensen Huang) объявил закон Мура более невозможным. Об этом сообщило издание CNET. Дженсен Хуанг заявил, следующее: «Закон Мура более невозможен».
Как теперь отметил топ-менеджер NVIDIA на сессии вопросов и ответов перед небольшим количеством журналистов, прямо сейчас закон Мура выражается в росте на несколько процентов каждый год и удвоение можно ожидать только каждые десять лет.
Интересно, что ещё в 2010 году вице-президент NVIDIA Билл Дэлли (Bill Dally) в своей колонке для журнала Forbes объявил о смерти так называемого закона Мура и отметил, что будущее за параллельными вычислениями.
Закон масштабирования Деннарда и его исполнение
Закон сформулировал в 1974 году разработчик динамической памяти DRAM Роберт Деннард (Robert Dennard) совместно с коллегами из IBM:
«Известно, что уменьшая размеры транзистора и повышая тактовую частоту процессора, мы повышаем повышать его производительность».
Правило закрепило уменьшение ширины проводника (по сути — миниатюризацию техпроцесса) в качестве главного показателя прогресса в микропроцессорной технике. Однако, закон масштабирования Деннарда стал буксовать еще в 2006 году. Количество транзисторов в чипах продолжает увеличиваться, но этот рост не дает существенного прироста к производительности устройств. Представители TSMC (производитель полупроводников) утверждают, что переход с 7-нм техпроцесса на 5-нм увеличит тактовую частоту процессора на 15%.
Известно, что основной причиной замедления роста частоты являются утечки токов, которые Деннард и не учитывал в своих разработках. Даже нынешние студенты первых курсов знают, что при уменьшении размеров транзистора и повышении частоты ток начинает сильнее нагревать микросхему, что при достижении критической температуры выведет ее из строя. В итоге производителям приходится балансировать между выделяемой процессором мощностью и производительностью. Как результат — уже с 2006 года частота массовых чипов установилась на отметке в 4–5 ГГц.
Да, сегодня инженеры работают над новыми технологиями, которые позволят в обозримом будущем решить проблему и увеличить производительность микросхем. К примеру, специалисты из Австралии разрабатывают металл-воздушный транзистор, который работает на частоте в несколько сотен гигагерц. Элемент состоит из двух металлических электродов, выполняющих роли стока и истока. Главное в этой схеме — их расположение (расстояние 35 нм). Они обмениваются электронами друг с другом благодаря явлению автоэлектронной эмиссии. Устройство позволит перестать добиваться уменьшения техпроцессов и сконцентрироваться на построении высокопроизводительных 3D-структур с большим числом транзисторов на кристалле.
Закон Куми и его исполнение
Закон сформулировал в 2011 году профессор Стэнфорда Джонатан Куми (Jonathan Koomey). Совместно с сотрудниками Microsoft, Intel и университета Карнеги-Меллона он сделал следующий вывод исходя из информации об энергопотреблении вычислительных систем начиная с ЭВМ ENIAC (1946):
«Можно утверждать, что объем вычислений на киловатт энергии при статической нагрузке удваивается каждые полтора года». Утверждение, в частности уточняло, что и энергопотребление компьютеров за прошедшие годы также выросло.
Спустя десятилетие после формулировки этого закона выяснилось, что средняя производительность чипа на киловатт энергии теперь удваивается каждые три года. Ситуация поменялась из-за трудностей, связанных с охлаждением чипов (как и было описано выше, с уменьшением размеров транзисторов становится труднее отводить тепло)
Будущее не за горами?
Да, вовсю разрабатываются технологии охлаждения чипов. Однако об их массовом внедрении пока говорить не приходится. К примеру, разработчики из университета в Нью-Йорке предложили использовать лазерную 3D-печать для нанесения на кристалл тонкого теплопроводящего слоя, в который входит титан, олово и серебро. Теплопроводность такого материала аж в 7 раз лучше, чем у иных термоинтерфейсов.
Надо отметить, что в своем исследовании физик Ричарда Фейнмана (Richard Feynman) еще в 1985 году отметил, что показатель энергоэффективности процессоров способен вырасти в 100 млрд раз. Однако по состоянию на 2019 год это значение не увеличилось и в 100 тысяч раз. Мы привыкли к высоким темпам роста вычислительных мощностей, инженеры ищут способы продлить действие закона Мура и преодолеть трудности, продиктованные законами Куми и Деннарда. Решением могут стать замена основных конструктивных элементов на кардинально новые.
Поделиться:
Оставьте свой комментарий!
Добавить комментарий
| < Предыдущая | Следующая > |
|---|
Развитие видеокарт в 2000-х годах / Блог компании ua-hosting.company / Хабр
Продолжая историю развития видеокарт из предыдущей — статьи, видеоадаптеры 2000-х годов.VSA-100 и новое поколение Voodoo
Чипсет VSA-100 (Voodoo Scalable Architecture — масштабируемая архитектура Voodoo) был выпущен компанией 3dfx в июне 2000 года. Первой видеокартой, использовавшей данный чип (VSA-100х2) стала Voodoo5 5500. Изготовленная по 250-нм техпроцессу, с 14 миллионами транзисторов. Объем памяти SDRAM доходил до 64 Мб, с 128-битной шиной. Частота графического процессора и памяти составляла 166 МГц. Впервые в видеокартах Voodoo поддерживался 32-битный цвет в 3D, а также текстуры с высоким разрешением 2048×2048 точек. Для сжатия применялись алгоритмы FXT1 и DXTC. Особенностью Voodoo5 5500 была высокая производительность при использовании сглаживания.
Видеокарта выпускалась с разными интерфейсами, такими, как AGP, PCI и т.д. Также была доступна версия под Macintosh, имеющая два разъема (DVI и VGA).
Осенью того же года 3dfx выпустила Voodoo4 4500 с объемом памяти 32 Мб, использовавшей один чип VSA-100. Модель оказалась довольно медленной и значительно уступала GeForce 2 MX и Radeon SDR.
Компания 3Dfx анонсировала выход производительной видеокарты Voodoo5 6000 на 4-х чипах VSA-100 и с 128 Мб памяти. Но окончательно реализовать проект так и не удалось — серьезные финансовые трудности обанкротили 3Dfx.
GeForce 2
В 2000-2001 годах компания NVIDIA выпустила серию видеокарт GeForce 2 (GTS, Ultra, Pro, MX и т. д.). У этих видеоадаптеров было 256-битное ядро — одно из самых производительных ядер того времени.
Базовой моделью стала GeForce 2 GTS (GigaTexel Shading), кодовое имя NV15. Данная видеокарта была изготовлена по 180-нм техпроцессу и содержала 25 миллионов транзисторов. Объем памяти DDR SGRAM составлял 32 Мб или 64 Мб с частотой 200 МГц и 128-битной шиной. У адаптера имелось 4 пиксельных конвейера. NV15 включала в себя полную поддержку DirectX 7, OpenGL 1.2, как и аппаратную обработку геометрии и освещения (T&L).
Radeon DDR и SDR
Компания ATI не отставала от прогресса и в 2000 году выпустила процессор Radeon R100 (изначально назывался Rage 6). Он изготавливался по 180-нм техпроцессу и поддерживал технологию ATI HyperZ.
На основе R100 вышли видеокарты Radeon DDR и SDR.
Radeon DDR выпускался с объемом видеопамяти 32 Мб или 64 Мб. Частоты ядра и памяти составляли 183 МГц, использовалась 128-битная шина. В роли интерфейса выступал AGP 4x. У видеокарты было 2 пиксельных конвейера.
Упрощенная версия SDR отличалась от Radeon DDR типом используемой памяти и пониженными частотами (166 МГц). Объем памяти у Radeon SDR предоставлялся только на 32 Мб.
Radeon 8500 и Radeon 7500
В 2001 году на базе RV200 вышли два чипа Radeon 8500 и Radeon 7500.
В Radeon 8500 были собраны новейшие наработки ATI, он оказался очень быстрым. Изготавливался по 150-нм техпроцессу, содержал 60 миллионов транзисторов. Частоты ядра и памяти составляли 275 МГц. Использовалась 128-битная шина. Объем памяти DDR SDRAM предлагался в двух вариантах: 64 Мб и 128 Мб. Пиксельных конвейеров было 4.
Radeon 7500 изготавливался по тому же 150-нм техпроцессу, но с 30 миллионами транзисторов. Ядро работало на частоте 290 МГц, а память на 230 МГц. Пиксельных конвейеров было 2.
GeForce 3
В 2001 году вышли графические процессоры GeForce 3 с кодовым названием NV20. Процессор выпускался по 150-нм техпроцессу. Объем памяти предлагался на 64 Мб и на 128 Мб. Шина была 128-битной и состояла из четырех 32-битных контроллеров. Ядро работало на частоте 200 МГц, а память на частоте 230 МГц. Пиксельных конвейеров насчитывалось 4. Производительность составляла 800 миллиардов операций/сек. Пропускная способность памяти была 7,36 Гб/с
Устройство поддерживало nFinite FX Engine, позволяющие создавать огромное количество различных спецэффектов. Была улучшенная архитектура памяти LMA (Lightspeed Memory Architecture).
Линейка видеокарт состояла из модификаций GeForce 3, GeForce 3 Ti 200 и Ti 500. Они отличались по тактовой частоте, производительности и пропускной способности памяти.
У GeForce 3 Ti 200: 175 МГц ядро, 200 МГц память; 700 миллиардов операций/сек; 6,4 Гб/с пропускная способность.
У GeForce 3 Ti 500: 240 МГц ядро и 250 МГц память; 960 миллиардов операций/сек; 8,0 Гб/с пропускная способность.
GeForce 4
Следующей видеокартой компании NVIDIA стала GeForce 4, которая вышла в 2002 году. C таким названием выпускались два типа графических карт: высокопроизводительные Ti (Titanium) и бюджетные MX.
Линейка GeForce 4 Ti была представлена моделями Ti 4400, Ti 4600, и Ti 4200. Видеокарты отличались тактовыми частотами ядра и памяти. Объем видеопамяти составлял 128 Мб (у Ti 4200 предлагался вариант и на 64 Мб). В Titanium использовался 128-битный 4-канальный контроллер памяти с LightSpeed Memory Architecture II, насчитывалось 4 блока рендеринга, 8 текстурных блоков, 2 T&L, имелась подсистема сглаживания Accuview и шейдерный движок nFiniteFX II, обеспечивающий полную поддержку DirectX 8.1 и OpenGL 1.3. Модель GeForce 4 Ti 4200 была самой распространенной за счет высокой производительности по приемлемой цене.
GeForce 4 MX наследовали архитектуру GeForce 2 (с повышенным быстродействием). Они базировались на чипе NV17, изготовленного по 150-нм техпроцессу и состоящего из 27 миллионов транзисторов. Объем видеопамяти составлял 64 Мб. У графического процессора было 2 блока рендеринга, 4 текстурных, 1 блок T&L, 128-битный 2-канальный контроллер памяти с LightSpeed Memory Architecture II. Чип также обладал подсистемой сглаживания Accuview.
Radeon 9700 Pro
Летом 2002 года ATI выпустила чип R300, который изготавливался по 150-нм техпроцессу и содержал около 110 миллионов транзисторов. У него было 8 пиксельных конвейеров. Также чип поддерживал улучшенные методы сглаживания.
На базе R300 вышла видеокарта Radeon 9700 с тактовыми частотами ядра 325 МГц и памяти 310 МГц. Объем памяти составлял 128 Мб. Шина памяти была 256-битная DDR.
В начале 2003 года Radeon 9700 сменила видеокарта Radeon 9800. Новые решения были построены на чипе R350, с увеличением тактовых частот и доработкой шейдерных блоков, контроллера памяти.
GeForce FX
GeForce FX — пятое поколение графических процессоров, разработанных и выпущенных компанией NVIDIA с конца 2002 до 2004 годов. Одна из первых видеокарт серии GeForce FX обладала улучшенными методами сглаживания и анизотропной фильтрации. Она поддерживала вершинные и пиксельные шейдеры версии 2.0. Благодаря 64-битному и 128-битному представлению цвета, повысилось качество ярких изображений. Чип NV30 был изготовлен по 130-нм техпроцессу и работал с шиной на 128-бит AGP 8x, поддерживая память DDR2.
GeForce FX была представлена в разных модификациях: еntry-level (5200, 5300, 5500), mid-range (5600, 5700, 5750), high-end (5800, 5900, 5950), еnthusiast (5800 Ultra, 5900 Ultra, 5950 Ultra). Использовалась шина на 126-бит и на 256-бит.
На базе NV30 было создано топовое устройство нового поколения — видеокарта GeForce FX 5800. Объем видеопамяти достигал 256 Мб, частота ядра — 400 МГц, а памяти — 800 МГц. В 5800 Ultra частота ядра повысилась до 500 МГц, а памяти — до 1000 МГц. Первые карты на основе NV30 оснащались инновационной системой охлаждения.
GeForce 6 Series
Развитие видеокарт активно продолжалось и в 2004 году вышел следующий продукт компании — GeForce 6 Series (кодовое название NV40).
Чип NV40 производился также по 130-нм техпроцессу, что не помешало ему стать более экономичным. Модификация пиксельных конвейеров дала возможность обрабатывать до 16 пикселей за такт. Всего было 16 пиксельных конвейеров. Видеокарты поддерживали пиксельные и вершинные шейдеры версии 3.0, технологию UltraShadow (прорисовка теней). Кроме этого, GeForce 6 Series с помощью технологии PureVideo декодировали видео форматов H.264, VC-1 и MPEG-2. NV40 работал через 256-битную шину, при этом использовались очень быстрые модули памяти типа GDDR3.
Одна из первых моделей, видеокарта GeForce 6800 была весьма производительной и тянула самые новые игры того времени. Она работала как через интерфейс AGP, так и через шину PCI Express. Частота ядра составляла 325 МГц, а частота памяти была 700 МГц. Объем памяти доходил 256 Мб или 512 Мб.
Radeon X800 XT
Компания ATI находилась в более выгодном положении. В 2004 году компания представила 130-нм чип R420 (усовершенствованная версия R300). Пиксельные конвейеры были разделены на четыре блока по четыре конвейера в каждом (в сумме 16 пиксельных конвейеров). Увеличилось до 6 количество вершинных конвейеров. Поскольку R420 не поддерживал работу шейдеров третьего поколения, он работал с обновленной технологией HyperZ HD.
Самая мощная и производительная видеокарта новой линейки Radeon была X800 XT. Карта оснащалась памятью типа GDDR3 объёмом 256 Mб и разрядностью шины 256-бит. Частота работы достигала 520 МГц по ядру и 560 МГц по памяти. Radeon X800 XT продавались в двух исполнениях: AGP и PCI Express. Помимо обычной версии существовал Radeon X800 XT Platinum Edition, обладающий более высокими частотами чипа и памяти.
GeForce 7800 GTX
В 2005 году вышел чип G70, который лег в основу видеокарт серии GeForce 7800. Количество транзисторов увеличилось до 302 миллионов.
Вдвое увеличилось количество пиксельных конвейеров — до 24 штук. В каждый конвейер были добавлены дополнительные блоки ALU, отвечающие за обработку наиболее популярных пиксельных шейдеров. Таким образом возросла производительность чипа в играх, делающих упор на производительность пиксельных процессоров.
GeForce 7800 GTX стала первой видеокартой на базе G70. Частота ядра составляла 430 МГц, памяти — 600 МГц. Использовалась быстрая GDDR3, а также 256-битная шина. Объем памяти составлял 256 Мб или 512 Мб. GeForce 7800 GTX работала исключительно через интерфейс PCI Express х16, который окончательно начал вытеснять устаревающий AGP.
GeForce 7950 GX2
Событием 2006 года для компании NVIDIA стал выпуск первой двухчиповой видеокарты GeForce 7950, созданной по 90-нм техпроцессу.Nvidia 7950 GX2 имела по одному чипу G71 на каждой из плат. Ядра видеокарты работали на частоте 500 МГц, память — на частоте 600 МГц. Объем видеопамяти типа GDDR3 составлял 1 Гб (по 512 Мб на каждый чип), шина 256-бит.
В новой карте было оптимизировано энергопотребление и доработана система охлаждения. Выпуск 7950 GX2 стал началом развития технологии Quad SLI, позволяющей одновременно использовать мощности нескольких видеокарт для обработки трёхмерного изображения.
Radeon X1800 XT, X1900
На базе R520 была разработана видеокарта Radeon X1800 XT. Карта оснащалась памятью типа GDDR3 объемом 256 Мб или 512 Mб, работающей на частоте 750 МГц. Использовалась 256-битная шина.
Видеокарты Radeon X1800 XT недолго пробыли на рынке. Вскоре им на смену пришли адаптеры серии Radeon X1900 XTХ на базе чипа R580. Процессором полностью поддерживались на аппаратном уровне спецификации SM 3.0 (DirectX 9.0c) и HDR-блендинг в формате FP16 с возможностью совместного использования MSAA. В новом чипе было увеличено количество пиксельных конвейеров — до 48. Частоты ядра составляла 650 МГц, а памяти — 775 МГц.
Еще через полгода вышел чип R580+ с новым контроллером памяти, работающий со стандартом GDDR4. Частота памяти была увеличена до 2000 МГц, при этом шина оставалась 256-битной. Основные характеристики чипа остались прежними: 48 пиксельных конвейеров, 16 текстурных и 8 вершинных конвейеров. Частота ядра составляла 625 МГц, памяти было больше — 900 МГц.
GeForce 8800 GTX
В 2006 году на базе процессора G80 было выпущено несколько видеокарт, самой мощной из которых являлась GeForce 8800 GTX. G80 был одним из самых сложных существующих чипом того времени. Он выпускался по 90-нм техпроцессу и содержал 681 миллион транзисторов. Ядро работало на частоте 575 МГц, память — на частоте 900 МГц. Частота унифицированных шейдерных блоков составляла 1350 МГц. У GeForce 8800 GTX было 768 Мб видеопамяти GDDR3, а ширина шины составляла 384-бит. Поддерживались новые методы сглаживания, которые позволили блокам ROP работать с HDR-светом в режиме MSAA (Multisample anti-aliasing). Получила развитие технология PureVideo.
Архитектура GeForce 8800 GTX оказалась особенно эффективной и на протяжении нескольких лет являлась одной из самых быстрых видеокарт.
Radeon HD2900 XT, HD 3870 и HD 3850
В 2007 года была представлена флагманская видеокарта Radeon HD2900 XT на базе чипа R600. Частота ядра видеокарты составляла 740 МГц, памяти GDDR4 — 825 МГц. Использовалась 512-битная шина памяти. Объем видеопамяти достигал 512 Мб и 1 Гб.
Более успешной разработкой вышел процессор RV670, выпущенный в том же году. Архитектурой он почти не отличался от предшественника, но изготавливался по 55-нм техпроцессу и с шиной памяти 256-бит. Появилась поддержка DirectX 10.1 и Shader Model 4.1. На базе процессора производились видеокарты Radeon HD 3870 (частота ядра 775 МГц, памяти 1125 МГц) и Radeon HD 3850 (частота ядра 670 МГц, памяти 828 МГц) с объемом видеопамяти 256 Мб и 512 Мб и шиной 256-бит.
GeForce 9800
Чип G92 лег в основу GeForce 9800 GTX — одной из самых быстрых и доступных видеокарт. Он изготавливался по 65-нм техпроцессу. Частота ядра составляла 675 МГц, частота памяти — 1100 МГц, а шина — 256-бит. Объем памяти предлагался в двух вариантах: на 512 Мб и на 1 Гб. Чуть позже появилась модель GTX+, которая отличалась 55-нм техпроцессом и частотой ядра — 738 МГц.
В данной линейке также появилась очередная двухчиповая видеокарта GeForce 9800 GX2. Каждый из процессоров имел спецификации, как у GeForce 8800 GTS 512 Мб, только с разными частотами.
GeForce GTX 280 и GTX 260
В 2008 году компания NVIDIA выпустила чип GT200, который использовался в видеокартах GeForce GTX 280 и GTX 260. Чип производился по 65-нм техпроцессу и содержал 1,4 миллиарда транзисторов, обладал 32 ROP и 80 текстурными блоками. Шина памяти увеличилась до 512-бит. Также была добавлена поддержка физического движка PhysX и платформы CUDA. Частота ядра видеокарты составляла 602 МГц, а памяти типа GDDR3 — 1107 МГц.
В видеокарте GeForce GTX 260 использовалась шина GDDR3 448-бит. Частота ядра достигала 576 МГц, а памяти — 999 МГц.
Radeon HD 4870
Старшая видеокарта новой линейки получила название Radeon HD 4870. Частота ядра составляла 750 МГц, а память работала на эффективной частоте 3600 МГц. С новой линейкой видеокарт компания продолжила свою новую политику выпуска устройств, которые могли успешно конкурировать в Middle-End-сегменте. Так, Radeon HD 4870 стал достойным конкурентом видеокарты GeForce GTX 260. А место лидера линейки HD 4000 вскоре заняло очередное двухчиповое решение Radeon HD 4870X2. Сама архитектура видеокарты соответствовала таковой у Radeon HD 3870X2, не считая наличия интерфейса Sideport, напрямую связывающего два ядра для наиболее быстрого обмена информацией.
GeForce GTX 480
В 2010 году NVIDIA представила GF100 с архитектурой Fermi, который лег в основу видеокарты GeForce GTX 480. GF100 производился по 40-нм техпроцессу и получил 512 потоковых процессоров. Частота ядра была 700 МГц, а памяти — 1848 МГц. Ширина шины составила 384-бит. Объем видеопамяти GDDR5 достигал 1,5 Гб.
Чипом GF100 поддерживались DirectX 11 и Shader Model 5.0, а также новая технология NVIDIA Surround, позволяющая развернуть приложения на три экрана, создавая тем самым эффект полного погружения.
Чипы Cypress и Cayman
Компания AMD выпустила 40-нм чип Cypress. Разработчики компании решили поменять подход и не использовать исключительно буквенно-цифровые значения. Поколению чипов начали присваивать собственные имена. Сам принцип архитектуры Cypress продолжал идеи RV770, но дизайн был переработан. Вдвое увеличилось количество потоковых процессоров, текстурных модулей и блоков ROP. Появилась поддержка DirectX 11 и Shader Model 5.0. В Cypress появились новые методы сжатия текстур, которые позволили разработчикам использовать большие по объему текстуры. Также AMD представила новую технологию Eyefinity, полным аналогом которой позже стала технология NVIDIA Surround.
Чип Cypress был реализован в серии видеокарт Radeon HD 5000. Вскоре AMD выпустила и двухчиповое решение Radeon HD 5970. В целом Cypress оказался очень успешным.
Серия видеокарт Radeon HD 6000, выпущенная в конце 2010 года, была призвана конкурировать с акселераторами GeForce GTX 500. В основе графических адаптеров лежал чип Cayman. В нем применялась немного другая архитектура VLIW4. Количество потоковых процессоров составляло 1536 штук. Возросло количество текстурных модулей — их стало 96. Также Cayman умел работать с новым алгоритмом сглаживания Enhanced Quality AA. Ширина шины памяти чипа составляла 256-бит. Видеокарты использовали GDDR5-память.
GeForce GTX 680
Начиная с 2011 года NVIDIA выпустила поколение графических ускорителей. Одной из примечательных моделей была видеокарта GeForce GTX 680, основанная на чипе GK104, производившемуся по 28-нм техпроцессу. Частота работы ядра 1006 МГц, частота работы памяти 6008 МГц, шина 256-бит GDDR5.
В 2013 года компания представила чип GK110, на котором основываются флагманские видеокарты GeForce GTX 780 и GeForce GTX Titan. Использовалась шина 384-бит GDDR5, а объем памяти повысился до 6 Гб.
Чем отличаются поколения видеопамяти | Видеокарты | Блог
Память, будь то оперативная память или видеопамять, является неотъемлемой частью современного компьютера. Сегодня вкратце узнаем, как все начиналось, как работает, почему диагностические программы показывают неверные частоты, в чем измеряется производительность памяти, как рассчитывается пропускная способность памяти и почему «МГц» для памяти — некорректное выражение.
DDR
До 2000-ых годов использовалась оперативная память стандарта SDR.
Потом ей на смену пришел новый стандарт памяти — DDR, который имел удвоенную пропускную способность памяти за счет передачи данных как по восходящим, так и по нисходящим фронтам тактового сигнала. Первоначально память такого типа, как и SDR, применялась в видеоплатах, но позднее появилась поддержка со стороны чипсетов.
DDR (Double Data Rate) расшифровывается как «удвоенная скорость передачи данных».
Таким образом, за один такт передается вдвое больше информации. Увеличилось количество передаваемой информации, реальная частота памяти осталась неизменной. Вместе с этим появилось такие понятия как эффективная частота, которая стала в два раза больше реальной.
Именно с приходом стандарта DDR появилась путаница с реальной и эффективной частотой работы памяти.
Реальная частота — частота шины модуля памяти. Эффективная частота — удвоенная частота шины модуля.
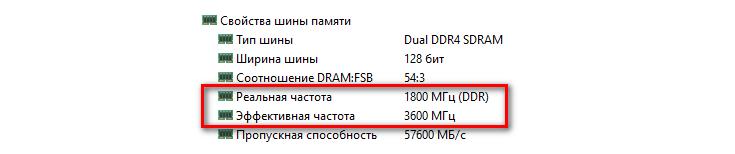
Как можно видеть, реальная частота памяти составляет 1900 МГц, в то время как эффективная в 2 раза больше — 3800 МГц, потому что за один такт теперь поступает вдвое больше данных.
Для того чтобы информация передавалась с удвоенной скоростью, она должна поступать из массива памяти вдвое быстрее. Реализовали это с помощью удвоения внутренней ширины модуля памяти. Благодаря чему за одну команду чтения мы стали получать сразу 2n единицы данных. Для стандарта DDR n = 1. Такая архитектура была названа n-prefetch (предвыборка). У памяти стандарта DDR, одной командой, при чтении, передается от ядра к буферу ввода-вывода две единицы данных.
Вместе с ростом производительности уменьшилось рабочее напряжение с 3.3V у SDR до 2.5V у DDR. Это позволило снизить энергопотребление и температуру, что дало возможность повысить рабочие частоты. На самом деле, потребление и, как следствие, нагрев, — это одна из самых больших проблем оперативной памяти того времени. При полном чтении всего модуля объемом 2 Гбайта память потребляет до 25 Ватт.
DDR2
Оперативная память стандарта DDR2 пришла на смену стандарту DDR в 2003 году, правда, поддерживающие ее чипсеты появились годом позже. Основное отличие DDR2 от DDR заключается в увеличенной вдвое частоте работы внутренней шины, по которой данные поступают в буфер «ввод-вывод». Передача на внутреннюю шину теперь осуществляется по технологии (4n-Prefetch), одной командой из массива памяти к буферу поступает 4 единицы данных.

Таким способом удалось поднять пропускную способность в два раза, не увеличивая частоту работы чипов памяти. Это выгодно с точки зрения энергоэффективности, да и количество годных чипов, способных работать на меньшей частоте, всегда больше. Однако у данного способа увеличения производительности есть и минусы: при одинаковой частоте работы DDR2 и DDR временные задержки у DDR2 будут значительно выше, компенсировать которые можно только на более высоких частотах работы.
Рабочее напряжение понизилось почти на 30% до 1.8V.
GDDR
На основе стандарта DDR для видеокарт в 2000 году был разработан новый стандарт памяти GDDR.
Технически GDDR и DDR похожи, только GDDR разработан для видеокарт и предназначен для передачи очень больших объемов данных.
GDDR (Graphics Double Data Rate) расшифровывается как двойная скорость передачи графических данных.
Несмотря на то, что они используются в разных устройствах, принципы работы и технологии для них очень похожи.
Главным отличием GDDR от DDR является более высокая пропускная способность, а также другие требования к рабочему напряжению.
Разработкой стандарта видеопамяти GDDR2 занималась компания NVIDIA. Впервые она была опробована на видеокарте GeForce FX 5800 Ultra.
GDDR2 это что-то среднее между DDR и DDR2. Память GDDR2 работает при напряжении 2.5V, как и DDR, однако обладает более высокими частотами, что вызывает достаточно сильный нагрев. Это и стало настоящей проблемой GDDR2. Долго данный стандарт на рынке не задержался.
Буквально чуть позже компания ATI представила GDDR3, в которой использовались все наработки DDR2. В GDDR3, как и DDR2, реализована технология 4n-Prefetch при операции записи данных. Память работала при напряжении 2V, что позволило решить проблему перегрева, и обладала примерно на 50% большей пропускной способностью, чем GDDR2. Несмотря на то, что разработкой стандарта занималась ATI, впервые его применила NVIDIA на обновленной видеокарте GeForce FX 5700 Ultra. Это дало возможность уменьшить общее энергопотребление видеокарты примерно на 15% по сравнению с GeForce FX 5700 Ultra с использованием памяти GDDR2.
Современные типы видеопамяти
На сегодняшний день наиболее распространенными типами видеопамяти являются GDDR5 и GDDR6, однако до сих пор в бюджетных решениях можно встретить память типа GDDR3-GDDR4 и даже DDR3.
Стандарт GDDR5 появился в 2008 году и пришел на смену стандарту GDDR4, который просуществовал совсем недолго, так и не получив широкое распространение вследствие не лучшего соотношения цена/производительность.
GDDR5 спроектирована с использованием наработок памяти DDR3, в ней используется 8-битовый Prefetch. Учитывая архитектурные особенности (используются две тактовые частоты CK и WCK), эффективная частота теперь в четыре раза выше реальной, а не в два, как было раньше. Таким способом удалось повысить эффективную частоту до 8 ГГц, а вместе с ней и пропускную способность в два раза. Рабочее напряжение составило 1.5V.
GDDR5X — улучшенная версия GDDR5, которая обеспечивает на 50% большую скорость передачи данных. Это было достигнуто за счет использования более высокой предварительной выборки. В отличие от GDDR5, GDDR5X использует архитектуру 16n Prefetch.
GDDR5X способна функционировать на эффективной частоте до 11 ГГц. Данная память использовалась только для топовых решений NVIDIA 10 серии GTX1080 и GTX1080Ti.

Память стандарт GDDR6 появился в 2018 году. GDDR6, как и GDDR5X, имеет архитектуру 16n Prefetch, но она разделена на два канала. Хотя это не улучшает скорость передачи данных по сравнению GDDR5X, оно позволяет обеспечить большую универсальность.
Сейчас данная память активно используется обоими производителями видеокарт в новой линейке NVIDIA серий GeForce 20 и 16 (кроме некоторых решений: GTX 1660 и GTX 1650, так как в них используется память GDDR5). При покупке нужно внимательно изучить характеристики видеокарты, потому как разница в производительности от типа памяти в данном случаи достигает от 5 до 15%. В то время как разница в цене совершенно несущественна.
Также тип памяти GDDR6 активно используется компанией AMD в видеокартах RX 5000 серии.
На начальном этапе GDDR6 способна функционировать с эффективной частотой 14 ГГц. Это позволяет удвоить пропускную способность относительно GDDR5. В дальнейшем эффективная частота будет увеличена, как это происходило с другими типами памяти.
Memory Technology | Memory Speed | Memory Bus | Memory Bandwidth |
GDDR6 | 14 Gbps | 384-bit | 672 GB/s |
GDDR5X | 11 Gbps | 384-bit | 528 GB/s |
GDDR5 | 7 Gbps | 384-bit | 336 GB/s |
GDDR6 | 14 Gbps | 256-bit | 448 GB/s |
GDDR5X | 11 Gbps | 256-bit | 352 GB/s |
GDDR5 | 7 Gbps | 256-bit | 224 GB/s |
GDDR6 | 14 Gbps | 192-bit | 336 GB/s |
GDDR5X | 11 Gbps | 192-bit | 264 GB/s |
GDDR5 | 7 Gbps | 192-bit | 168 GB/s |
- Шину памяти (Memory Bus) можно рассматривать как дорожные полосы
— Чем больше полос выделено для движения, тем живее поток.
С приходом нового типа памяти ее реальные частоты могут быть даже меньше, чем у предыдущего поколения. Однако в последующем производители отлаживают процесс и выжимают максимум возможного.
Например, сейчас такое происходит с оперативной памятью DDR4. На старте продаж ее частоты были как и у DDR3, но сейчас мы видим, что в продаже есть модули, способные функционировать на частоте 5000 МГц, а уже в следующем году наc ждет новый тип оперативной памяти DDR5.
Кратко о типе памяти HBM
HBM — это совершенно новый стандарт памяти, он обладает низкой рабочей частотой, но имеет очень широкую шину, благодаря чему обладает существенно более высокой пропускной способностью и значительно меньшими задержками по сравнению с GDDR5, одновременно потребляя значительно меньше электроэнергии. Память стандарта HBM достаточно дорогая для использования в геймерских видеокартах, поэтому чаще всего используется в профессиональных решениях.
HBM имеет отличия и в компоновке по сравнению с традиционной видеопамятью. В случае GDDR чипы памяти распаиваются на плате рядом с графическим процессором, а сами чипы занимают много места. Но кристаллы HBM оснащены сквозными контактами, благодаря чему память можно собирать в вертикальные стэки, когда один кристалл лепят к другому сверху.
Чипы памяти взаимодействуют с GPU через дополнительную кремниевую подложку. Получается этакий бутерброд из кристаллов. Это позволяет экономить место на плате, значительно упрощает и удешевляет саму печатную плату (у GDDR сотни контактов на один чип) и позволяет более эффективно охлаждать память.
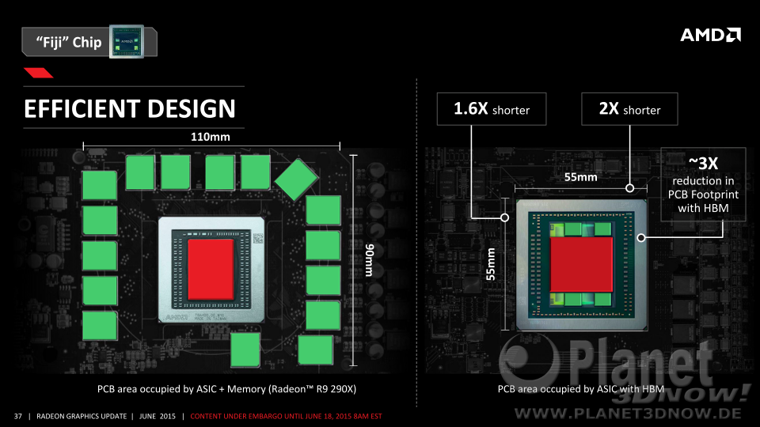
Плюсы HBM:
- высокая пропускная способность
- высокая битовая плотность на модуль
- низкое энергопотребление
- маленькая задержка
- значительное уменьшение размеров видеокарты
Минусы по сравнению с GDDR:
- высокие производственные затраты, следовательно, высокая конечная цена
- высокие затраты на интеграцию из-за повышенной сложности конструкции
Частота памяти — некорректное понятие
Что за цифры в характеристиках памяти и чем измеряются?
В спецификации стандарта JEDEC есть замечание, что применение термина «МГц» в DDR некорректно, правильно указывать скорость «миллионов передач в секунду через один вывод данных» MT/S.
Именно поэтому запись DDR4 3600 МГц лишена смысла — поскольку шина памяти работает на реальной частоте 1800 МГц и лишь передает данные два раза за такт. А поскольку с виду все это кажется как 1800*2 = 3600, то маркетологи тут же принялись писать 3600 МГц.
Как говорят маркетологи из компании Intel, «пользователь покупает ГГц», и неважно, соответствует ли фраза истине.
Со временем у производителей памяти сложилось стойкое ощущение, что нужно использовать термин Мегагерц «МГц», для покупателя короче и выглядит внушительнее. Вот и прижились всем МГц несмотря на то, что звучит некорректно.
Как вычислить пропускную способность памяти?
Пропускная способность памяти напрямую зависит от эффективной частоты и разрядности шины памяти.
Разрядность оперативной памяти характеризуется количеством бит, с которыми операция чтения из памяти или запись может быть выполнена одновременно. Современные модули памяти имеют разрядность 8 байт или 64 бита. В большинстве компьютеров сейчас используется либо двухканальный режим работы памяти (при использовании двух модулей памяти) — это 128 бит, либо одноканальный (один модуль памяти) — 64 бит. Есть еще 256-битный режим работы оперативной памяти, но он чаще встречается в HEDT-платформах (High-End Desktop — высокопроизводительная рабочая станция).
Чтобы рассчитать теоретическую пропускную способность, воспользуемся формулой:
ПСП = Эффективная частота * шину памяти (64 для одноканального режима и 128 для двухканального) и / 8.
Для примера, мои модули DDR4 G.Skill SNIPER X [F4-3600C19D-32GSXWB] 32 ГБ с эффективной частотой 3600 МГц. Чтобы узнать эффективную частоту нужно реальную частоту умножить на 2: 1800*2 = 3600.
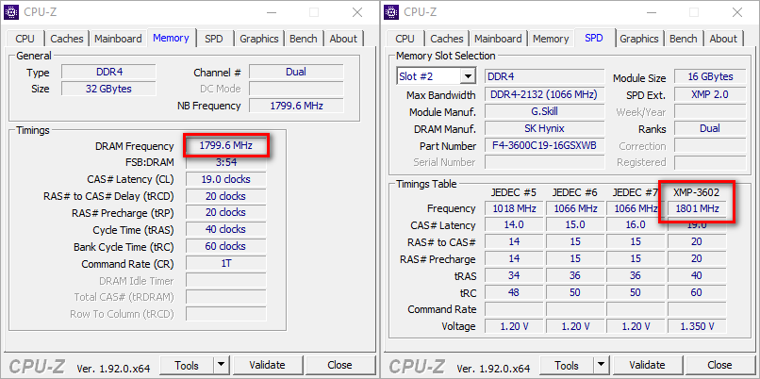
Для двухканального режима работы 3600*128/8 = 57600 Мбайт/с.
Для одноканального режима работы 3600*64/8 = 28800 Мбайт/с.
Именно это число указывается при маркировке модуля «PC4-28800».
Чтобы узнать эффективную частоту видеопамяти, нужно реальную умножить на 4, это касается видеокарт с памятью GDDR5, в то время как для GDDR5X и GDDR6 реальную частоту нужно умножить на 8.
Пример расчета пропускной способности памяти для видеокарт:
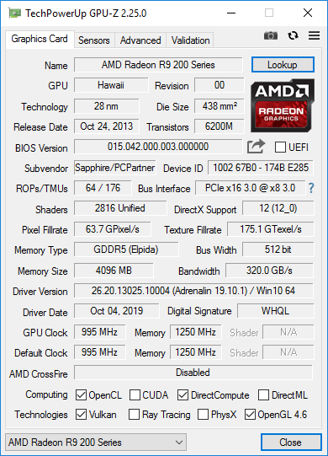
Для нашей видеокарты R290X реальная частота памяти равна 1250 МГц. Так как за такт в памяти GDDR5 передается в 4 раза больше данных, нужно умножить на 4, чтобы получить эффективную частоту. Так как шина памяти у видеокарты составляет 512 бит, умножаем на 512. 1250 МГц*4*512 = 2560000 Мегабит/с.
Для того, чтобы получить байты, нужно полученное число разделить на 8 так как 1 байт = 8 бит, 2560000/8/1000 = 320,0 Гб/с. Получается, пропускная способность памяти у данной видеокарты равна 320,0 Гб/с.
Поскольку базовая скорость памяти не изменяется существенно от поколения к поколению, именно увеличивающаяся предварительная выборка и шина с каждым поколением DDR помогает обеспечить рост пропускной способности.
Тип памяти | Базовая частота | Шина памяти | Предвыборка | МТ/s | Пропусная прособность | Напряжение |
SDRAM | 100–166 | 100–166 | 1 | 100–166 | 0,8–1,3 | 3,3 |
DDR | 100–200 | 100–200 | 2 | 200–400 | 1,6–3,2 | 2,5/2,8 |
DDR2 | 100–266 | 200–533 | 4 | 400–1066 | 3,2–8,5 | 1,8 |
DDR3 | 100–266 | 400–1066 | 8 | 800–2133 | 6,4–17,1 | 1,35/1,5 |
DDR4 | 100–266 | 1066–2133 | 8 | 2133–4266 | 17,1–34,1 | 1,2 |
Как можно видеть, с каждым приходом нового стандарта оперативной памяти наблюдается двухкратный рост пропускной способности. Вместе с тем постоянно снижается рабочее напряжение и, как следствие, энергопотрбление. Так как оно напрямую связано с энергоэффективностью, его важность лишь продолжит усиливаться в дальнейшем.
Как работают микропроцессоры | HowStuffWorks
Даже невероятно простой микропроцессор, показанный в предыдущем примере, будет иметь довольно большой набор инструкций, которые он может выполнять. Набор инструкций реализован в виде битовых комбинаций, каждая из которых имеет различное значение при загрузке в регистр инструкций. Люди не особенно хорошо запоминают битовые шаблоны, поэтому для представления различных битовых шаблонов определяется набор коротких слов. Этот набор слов называется языком ассемблера процессора.Ассемблер может очень легко преобразовать слова в их битовые комбинации, а затем выходные данные ассемблера помещаются в память для выполнения микропроцессором.
Вот набор инструкций на языке ассемблера, которые разработчик может создать для простого микропроцессора в нашем примере:
- LOADA mem — Загрузить регистр A из адреса памяти
- LOADB mem — Загрузить регистр B из адреса памяти
- CONB con — Загрузить постоянное значение в регистр B
- SAVEB mem — Сохранить регистр B по адресу памяти
- SAVEC mem — Сохранить регистр C по адресу памяти
- ADD — Сложить A и B и сохранить результат в C
- SUB — Вычесть A и B и сохранить результат в C
- MUL — Умножить A и B и сохранить результат в C
- DIV — Разделить A и B и сохранить результат в C
- COM — Сравнить A и B и сохранить результат в тесте
- JUMP addr — Перейти к адресу
- JEQ addr — Перейти, если он равен, по адресу
- JNEQ addr — Перейти, если не равен, по адресу
- JG addr — Перейти, если больше, по адресу
- JGE addr — Перейти, если больше или равно, по адресу
- JL addr — Перейти, если меньше, по адресу
- JLE addr — Перейти, если меньше или равно адрес
- STOP — Остановить выполнение
Если вы прочитали Как работает программирование на C, то вы знаете, что этот простой фрагмент кода C вычислит факториал 5 (где факториал 5 = 5! = 5 * 4 * 3 * 2 * 1 = 120):
a = 1; f = 1; в то время как (a <= 5) {f = f * a; а = а + 1;}
В конце выполнения программы переменная f содержит факториал 5.
Язык ассемблера
Компилятор C переводит этот код C на язык ассемблера. Если предположить, что ОЗУ начинается с адреса 128 в этом процессоре, а ПЗУ (которое содержит программу на языке ассемблера) начинается с адреса 0, тогда для нашего простого микропроцессора язык ассемблера может выглядеть так:
// Предположим, что a находится по адресу 128 // Предположим, что F находится по адресу 1290 CONB 1 // a = 1; 1 SAVEB 1282 CONB 1 // f = 1; 3 SAVEB 1294 LOADA 128 // если a> 5, переход к 175 CONB 56 COM7 JG 178 LOADA 129 // f = f * a; 9 LOADB 12810 MUL11 SAVEC 12912 LOADA 128 // a = a + 1; 13 CONB 114 ADD15 SAVEC 12816 JUMP 4 // возврат к if17 STOP
ROM
Итак, теперь вопрос: «Как все эти инструкции выглядят в ПЗУ?» Каждая из этих инструкций на языке ассемблера должна быть представлена двоичным числом.Для простоты предположим, что каждой инструкции на языке ассемблера присвоен уникальный номер, например:
- LOADA — 1
- LOADB — 2
- CONB — 3
- SAVEB — 4
- SAVEC mem — 5
- ADD — 6
- SUB — 7
- MUL — 8
- DIV — 9
- COM — 10
- Адрес JUMP — 11
- Адрес JEQ — 12
- Адрес JNEQ — 13
- Адрес JG — 14
- Адрес JGE — 15
- Адрес JL — 16
- Адрес JLE — 17
- STOP — 18
Эти числа известны как коды операций .В ПЗУ наша маленькая программа будет выглядеть так:
// Предположим, что a находится по адресу 128 // Предположим, что F находится по адресу 129Addr opcode / value0 3 // CONB 11 12 4 // SAVEB 1283 1284 3 // CONB 15 16 4 // SAVEB 1297 1298 1 // LOADA 1289 12810 3 // CONB 511 512 10 // COM13 14 // JG 1714 3115 1 // LOADA 12916 12917 2 // LOADB 12818 12819 8 // MUL20 5 // SAVEC 12921 12922 1 // LOADA 12823 12824 3 // CONB 125 126 6 // ADD27 5 // SAVEC 12828 12829 11 // JUMP 430831 18 // STOP
Вы можете видеть, что семь строк кода C превратились в 18 строк ассемблера, а это превратилось в 32 байта в ПЗУ.
Расшифровка
Декодер команд должен превратить каждый из кодов операции в набор сигналов, которые управляют различными компонентами внутри микропроцессора. Возьмем в качестве примера инструкцию ADD и посмотрим, что ей нужно делать:
- Во время первого такта нам нужно фактически загрузить инструкцию. Следовательно, декодеру команд необходимо: активировать буфер с тремя состояниями для программного счетчика; активировать строку RD; активировать буфер с тремя состояниями ввода данных; защелкнуть команду в регистре команд
- . Во время второго тактового цикла
транзисторов вчера и сегодня | HowStuffWorks
В 1960-х и 1970-х годах в транзисторных изделиях в основном использовалась конструкция транзисторов с основным переходом, разработанная Bell Labs. Успехи в разработке кремния в 1970-х годах привели к созданию металлооксидных полупроводниковых полевых транзисторов (, MOSFET) . В полевых МОП-транзисторах используются те же принципы, что и в других транзисторах, но кремний N- и P-типов менее дорог, устроен по-другому и легирован другими типами металлов и оксидов, в зависимости от предполагаемого использования.
Также существует много других типов транзисторов. Инженеры классифицируют транзисторы по полупроводниковому материалу, применению, структуре, номинальной мощности, рабочим частотам и другим параметрам. По мере развития технологий инженеры узнали, что они могут производить множество транзисторов одновременно из одного и того же полупроводникового материала вместе с другими компонентами, такими как конденсаторы и резисторы.
В результате получается так называемая интегральная схема .Эти схемы, обычно называемые просто «микросхемами», содержат миллиарды бесконечно малых транзисторов. С 1960-х годов количество транзисторов на единицу площади удваивается каждые 1,5 года, что означает, что инженеры могут втиснуть их в все меньшие и меньшие изделия.
Современные кремниевые коммерческие транзисторы могут быть меньше 45 нанометров. Они настолько малы, что новая графическая карта NVDIA (кодовое название GF100) имеет более 3 миллиардов транзисторов, что является самым большим числом в одном чипе.И эти транзисторы — чудовища по сравнению с тем, что нас ждет в будущем.
Ученые из Йельского университета и Южной Кореи недавно создали первый в мире молекулярный транзистор, состоящий из единственной молекулы бензола. Хотя крошечный размер удивителен, инженеры подчеркивают, что их не столько заботит объем, сколько эффективность. Современные микросхемы создают много ненужного тепла, потому что их транзисторы не передают энергию так эффективно, как хотелось бы производителям продукции; Молекулярные транзисторы могут стать ключом к значительному повышению эффективности.
Материалы транзисторов тоже меняются благодаря недавним достижениям в материале, называемом графен. Графен передает электроны намного быстрее, чем кремний, и может привести к появлению компьютерных процессоров, которые будут в 1000 раз быстрее, чем продукты на основе кремния.
Независимо от того, где будет развиваться разработка, транзисторы будут продолжать стимулировать исследования продуктов и технологические достижения, которые мы даже не можем себе представить. Компьютеры станут быстрее, дешевле и надежнее.Сотовые телефоны и музыкальные плееры уменьшатся до крошечных размеров и все равно будут стоить меньше, чем предыдущие модели.
В этом сила транзисторов в изменении ландшафта технологий и, в конечном итоге, всего нашего общества в целом. Неплохой пробег для простого устройства, изобретенного более 60 лет назад.
Статьи по теме HowStuffWorks
Больше замечательных ссылок
Источники
- Американское физическое общество.«Этот месяц в истории физики: изобретение первого транзистора». Физика. (26 января 2010 г.) http://www.aps.org/publications/apsnews/200011/history.cfm
- BBC News. «Создание цифровой эпохи». (26 января 2010 г.) http://news.bbc.co.uk/2/hi/technology/7091190.stm
- Белл, Брэндон. «Графическая архитектура NVIDIA GF100». Firingsquad.com. 17 января 2010 г. (26 января 2010 г.) http://news.firingsquad.com/hardware/nvidia_gf100_architecture_overview/
- Блэнд, Эрик. «Создан первый молекулярный транзистор.»Discovery News. 12 января 2010 г. (26 января 2010 г.) http://news.discovery.com/tech/molecular-transistor-benzene.html
- Choi, Charles Q.» Transistor Flow Control. «Scientific Американский. 17 октября 2005 г. (26 января 2010 г.) http://www.scientificamerican.com/article.cfm?id=transistor-flow-control
- Музей истории компьютеров. «Запатентованные концепции полевых полупроводниковых устройств. «(26 января 2010 г.) http://www.computerhistory.org/semiconductor/timeline/1926-field.html
- Музей истории компьютеров.«Изобретение точечного транзистора». (26 января 2010 г.) http://www.computerhistory.org/semiconductor/timeline/1947-invention.html
- Грей, Теодор. «Изготовление кремния из песка». Popsci.com. 17 октября 2005 г. (26 января 2010 г.) http://www.popsci.com/diy/article/2005-10/making-silicon-sand
- IEEE Global History Network. «Транзистор и портативная электроника». 2 сентября 2008 г. (26 января 2010 г.) http://www.ieeeghn.org/wiki/index.php/The_Transistor_and_Portable_Electronics
- Нобелевская премия.орг. «Нобелевская премия по физике 1956 г.» (26 января 2010 г.) http://nobelprize.org/nobel_prizes/physics/laureates/1956/index.html
- Nobelprize.org. «Транзистор». (26 января 2010 г.) http://nobelprize.org/educational_games/physics/transistor/function/semiconductor.html
- Nobelprize.org. «Транзистор в век электроники». (26 января 2010 г.) http://nobelprize.org/educational_games/physics/transistor/history/
- PBS. «Кремниевый P-N переход». (26 января 2010 г.) http: //www.pbs.org / transistor / science / events / pnjunc.html
- PBS. «Изобретен транзистор». (26 января 2010 г.) http://www.pbs.org/wgbh/aso/databank/entries/dt47tr.html
- PBS. «Транзисторный!» (26 января 2010 г.) http://www.pbs.org/transistor/
- Риордан, Майкл. «Как Европа упустила транзистор». IEEE Spectrum. Ноябрь 2005 г. (26 января 2010 г.) http://spectrum.ieee.org/semiconductors/devices/how-europe-missed-the-transistor
- Риордан, Майкл. «Утраченная история транзистора». IEEE Spectrum.Май 2004 г. (26 января 2010 г.) http://spectrum.ieee.org/biomedical/devices/the-lost-history-of-the-transistor
- Симко, Роберт Дж. «Революция в твоем кармане». AmericanHeritage.com. Осень 2004 г. (26 января 2010 г.) http://www.americanheritage.com/articles/magazine/it/2004/2/2004_2_12.shtml
- Texas Instruments. «Дебют радио Regency, первый коммерческий транзисторный продукт массового производства». (26 января 2010 г.) http://www.ti.com/corp/docs/company/history/timeline/semicon/1950/docs/54regency.htm
- Исторический пресс-релиз Texas Instruments.»Первое коммерческое радио. TI поставляет транзисторы для первого» карманного «радио». (26 января 2010 г.) http://people.msoe.edu/~reyer/regency/TI-1.pdf
- Виртуальная лаборатория Университета Вирджинии. «Как работают полупроводники и транзисторы». (26 января 2010 г.) http://virlab.virginia.edu/VL/MOS_kit.htm
- UPI.com. «Создан одномолекулярный транзистор». 28 декабря 2009 г. (26 января 2010 г.) http://www.upi.com/Science_News/2009/12/28/Single-molecule-transistor-created/UPI-22521262032655/
Как работают видеокарты | HowStuffWorks
Как и материнская плата, видеокарта представляет собой печатную плату, на которой размещены процессор и оперативная память. Он также имеет микросхему системы ввода / вывода (BIOS), которая хранит настройки карты и выполняет диагностику памяти, ввода и вывода при запуске. Процессор видеокарты, называемый графическим процессором (GPU), аналогичен процессору компьютера. Однако графический процессор разработан специально для выполнения сложных математических и геометрических вычислений, необходимых для рендеринга графики.Некоторые из самых быстрых графических процессоров имеют больше транзисторов, чем средний процессор. Графический процессор выделяет много тепла, поэтому обычно располагается под радиатором или вентилятором.
Помимо вычислительной мощности, графический процессор использует специальные программы, помогающие анализировать и использовать данные. ATI и nVidia производят подавляющее большинство графических процессоров на рынке, и обе компании разработали собственные усовершенствования для повышения производительности графических процессоров. Для улучшения качества изображения в процессорах используются:
- Полное сглаживание сцены (FSAA), которое сглаживает края трехмерных объектов
- Анизотропная фильтрация (AF), которая делает изображения более четкими
Каждая компания также разработала определенные методы, помогающие графическому процессору применять цвета, тени, текстуры и узоры.
Поскольку графический процессор создает изображения, ему нужно где-то хранить информацию и готовые изображения. Для этого он использует оперативную память карты, храня данные о каждом пикселе, его цвете и его расположении на экране. Часть ОЗУ может также действовать как буфер кадров , что означает, что он хранит завершенные изображения до тех пор, пока не придет время их отображать. Обычно видеопамять работает на очень высоких скоростях и имеет двухпортовый , что означает, что система может читать из нее и записывать в нее одновременно.
ОЗУ подключается непосредственно к цифро-аналоговому преобразователю , называемому ЦАП. Этот преобразователь, также называемый RAMDAC, преобразует изображение в аналоговый сигнал, который может использовать монитор. Некоторые карты имеют несколько RAMDAC, что может повысить производительность и поддерживать более одного монитора. Вы можете узнать больше об этом процессе в Как работает аналоговая и цифровая запись.
RAMDAC отправляет окончательное изображение на монитор через кабель.Мы рассмотрим это соединение и другие интерфейсы в следующем разделе.
,Как мне узнать, какая у меня видеокарта компьютера?
Обновлено: 30.06.2020 компанией Computer Hope
Независимо от того, хотите ли вы обновить свой компьютер или хотите узнать его технические характеристики, многие люди хотят знать, какая видеокарта или графический процессор установлен на их компьютере. Некоторые ПК имеют встроенную графику, а некоторые — видеокарту. В любом случае приведенные ниже инструкции помогут вам определить графическое устройство, питающее видеовыход вашего компьютера. Чтобы продолжить, выберите предпочтительный метод из списка ниже или прочтите все разделы и продолжайте оттуда.
Диспетчер устройств
Один из самых быстрых способов узнать, какой тип графического процессора установлен на вашем компьютере с Windows, — использовать диспетчер устройств Windows.
- Нажмите клавишу Windows, введите Диспетчер устройств , а затем нажмите Введите .
- В появившемся окне разверните раздел Видеоадаптеры .
- Графический процессор указан в разделе «Видеоадаптеры». Например, на картинке выше в компьютер установлена видеокарта Radeon RX 580 Series .
Сторонняя программа
Есть много сторонних программ, которые обнаруживают видеокарту в вашем компьютере. Мы рекомендуем установить и использовать программу CAM, выполнив следующие действия.
- Откройте Интернет-браузер и перейдите на страницу CAM.
- В центре экрана нажмите кнопку.
- После завершения загрузки установите его из браузера и откройте программу.
- Вы увидите открытое окно, похожее на изображение ниже.
- Отсюда вы можете увидеть, какой графический процессор установлен на вашем компьютере, в средней части главного экрана. Например, на рисунке выше показана видеокарта Radeon RX 580 Series или графический процессор, установленный в компьютере.
OEM поиск
Если у вас есть компьютер OEM (например, Dell, Hewlett Packard и т. Д.), Найдите серийный номер или номер сервисной метки, а затем найдите его на веб-сайте производителя.
При загрузке или POST
Некоторые компьютеры могут отображать видеокарту или набор микросхем во время POST.Попробуйте перезагрузить компьютер и, пока он загружается, нажмите клавишу «Пауза / Перерыв», чтобы временно остановить процесс загрузки компьютера и прочитать текст на экране. Если вы не знакомы с производителями видеокарт или наборами микросхем, запишите названия некоторых компаний, которые вы видите, и выполните поиск в нашем разделе драйверов видеокарт для этой компании.
Откройте компьютер
Отсоедините все от задней части компьютера, откройте корпус и найдите визуальную идентификацию, напечатанную на видеокарте или материнской плате.Часто вы можете найти название производителя, номер модели, серийный номер или другую уникальную информацию, которая идентифицирует вашу видеокарту или видеочипсет. На картинке ниже показан пример старой видеокарты AGP.
НаконечникЕсли ваша видеокарта находится на материнской плате, вы можете найти набор микросхем видеочипа материнской платы, указав производителя и модель материнской платы и прочитав документацию к материнской плате.
Идентификационный номер FCC
Если вы не можете найти производителя или номер модели видеокарты, но видите идентификационный номер FCC, мы рекомендуем вам выполнить поиск, используя его.Дополнительная информация о номерах FCC и о том, как искать информацию о них, содержится в нашем определении FCC.
Процедура отладки (старые компьютеры)
ЗаметкаНовые версии Windows больше не включают команду отладки. Если вы используете Windows Vista, 7, 8 или 10, эта рекомендация не сработает.
- Откройте командную строку.
- В командной строке C: \> введите следующую команду.
отладка
- В командной строке — введите следующую команду:
d c000: 0040
- После ввода приведенной выше команды появится несколько строк текста, аналогичных приведенному ниже.
C000: 0040 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
C000: 0050 E9 63 7B 00 B4 10 49 27 - E9 FE 2B E9 F7 2B 50 4D .c {... I '.. + .. + PM
C000: 0060 49 44 58 00 5B 00 00 00-00 A0 00 B0 00 B8 00 C0 IDX. [... ........
C000: 0070 00 5B 53 54 42 20 6E 56 - 49 44 49 41 20 54 4E 54. [STB nVIDIA TNT
C000: 0080 20 76 65 72 2E 20 31 2E - 31 30 20 0D 0A 00 1B 43 вер. 1.10 .... C
C000: 0090 6F 70 79 72 69 67 68 74-28 43 29 31 39 39 38 20 авторское право (C) 1998
C000: 00A0 53 54 42 20 53 79 73 74-65 6D 73 20 49 6E 63 0D STB Systems Inc.
C000: 00B0 0A 00 22 6C 2C 0A 01 00 - C3 50 24 7F E8 60 36 58 .. "1, .... P $ .. '6
Пример дампа выше дает вам достаточно информации, чтобы определить марку и год выпуска видеокарты. В четвертой строке приведенного выше дампа вы можете увидеть марку этой видеокарты — nVIDIA TNT. Если бы вы поискали в Интернете, вы бы обнаружили, что nVIDIA TNT — это набор микросхем для видеокарт Riva TNT. В нашем примере строка пять — это версия видеокарты, а строка шесть — это авторские права, то есть год выпуска видеокарты.
- Если вы не можете записать какую-либо информацию, которая звучит как видеокарта, вы также можете ввести следующее:
-d c000: 0090
Эта команда дает вам дамп, аналогичный приведенному выше примеру. Однако в нем может быть дополнительная информация о видеокарте.
ЗаметкаЕсли видеокарта встроена, вы можете узнать название материнской платы или набора микросхем. Если у вас есть встроенная видеокарта, получите видеодрайверы для производителя вашего чипсета. Драйверы для набора микросхем доступны у производителя материнской платы.
- Когда вы будете готовы выйти из командной строки отладки, введите quit и нажмите Enter, чтобы вернуться в командную строку MS-DOS. Если вы хотите закрыть окно MS-DOS, введите , выход и нажмите Enter.