
Speech-to-text (Распознавание речи) — документация Staffcop Enterprise 5.1
В Staffcop Enterprise начиная с версии 5.X — была добавлена функция — Speech To Text (преобразование записанного звука в текст).
Описание модуля
Модуль распознавания звука в текст работает через Tinkoff Speech Kit.
Модуль распознавания звука в текст требует доступа в интернет по адресу — voicekit.tinkoff.ru и api.tinkoff.ai (Адреса находятся в России).
Модуль распознавания голоса от tinkoff разработан компанией Tinkoff (наработки не используют зарубежные технологии и не передают данные дальше дата-центра по обработке голоса Tinkoff).
Модуль поддерживает работу в многопоточном режиме, для одновременной обработки большого количества одновременно распознаваемых аудиоданных.
Оплата за облачный модуль распознавания речи в текст — осуществляется через личный кабинет на сайте — voicekit.tinkoff.ru
Стартовый ознакомительный баланс на счету от Tinkoff Speech Kit — составляет — 1000р.


Включение модуля
Для активации модуля распознавания звука в текст, нужно проделать несколько действий:
Открыть веб-интерфейс Staffcop и перейти на страницу «Панель управления — Параметра сервера — Распознавание голоса». Поставить галочку «Разрешить конфигурацию по-умолчанию», внести параметры и выбрать движок — «Tinkoff VoiceKit», после сохранить изменения в параметрах сервера.
Работа модуля
Для распознавания речи в текст служат два механизма:
Первый способ распознавания: через иконку под записями звука.
Нужен для демонстрации технологии и проверки работы. После клика на значок, будет распознан указанный фрагмент звуковой записи в текст (если таковой будет обнаружен в отрезке записи).
Второй способ распознавания: через политику «распознавание речи» — более общий.
Позволяет распознавать голос в текст на общем основании и накапливать текстовую базу преобразования голоса в текст и анализировать данные с помощью встроенных политик распознавания по словарям, регулярным выражениям и встроенным политикам безопасности, т. е. после отработки политики «Распознавание речи», будут отработаны стандартные политики обработки текста в Staffcop. Добавить политику можно нажав в web-интерфейсе «
е. после отработки политики «Распознавание речи», будут отработаны стандартные политики обработки текста в Staffcop. Добавить политику можно нажав в web-интерфейсе «
Пример такой работы:
Особенности работы и примечания
Модуль Speech To Text спроектирован для будущего развития и возможности подключить встроенный в Staffcop — модуль распознавания на основе моделей определения голоса и для подключения других сторонних технологий распознавания.
Файлы конвертируются в моно mp3, размер при этом изменяется не существенно.
Наибольшая замеченная скорость распознавания равна x15 (время распознавания равно 1/15 от продолжительности записи), например, за сутки записано 470 часов, тогда 470/15=31 час, т.е. требуется 31 час, чтобы распознать записи сделанные за 24 часа (значит распознавание, в данном примере, всегда будет отставать от записи, придётся настраивать фильтрацию, например, по устройствам или по пользователям).
Для примера выше — 470 часов записей, по самому низкому тарифу Tinkoff-а, обойдутся в 5076р.
«Обычно» количество «мусора» колеблется от очень много до очень-очень много. Под «мусором» подразумеваются записанные системные звуки, работающий телевизор, разговоры в комнате (удалёнка) и пр.
В процессе работы собирается статистическая информация, например, продолжительность аудио и время его обработки (конвертирование + распознавание).
Временные файлы хранятся в /var/lib/staffcop/upload/speech_recognition/…
Все результаты работы подсистемы сохраняются в дополнительных таблицах speechrecognition_result (модель speech_processing.models.SpeechRecognitionResult) и speechrecognition_failure (модель speech_processing.models.SpeechRecognitionFailure) и на данный момент их чистка не предусмотрена.
Наличие таблицы «speechrecognition_result» облегчает повторные проходы, например, если результаты работы успешные, то обрабатываться будут только записи с ошибками, пропущенные или не обработанные ранее.
Количество попыток распознания ограничено, оно сейчас никак не конфигурируется (см. speech_processing.config:Config.attempts_limit) и равно 5.
При большом количестве ошибок (например, неправильный ключ доступа к сервису распознавания, ошибка сети и т.д.), политика будет отключена.
После удачного распознавания нормализованные аудио удаляются, в противном случае — нет. Чистка ФС от нормализованных аудио не реализована.
Cуществует «костыль» от коротких файлов в виде предварительной проверки размера файла, файл не должен быть меньше 30kB (ориентировочная продолжительность такой записи до 2 сек).
Существует «костыль» и для защиты от больших файлов (сделано из-за Tinkoff, см. выше, но применяется ко всем «движкам»), файл не должен быть больше 30MB.
Распознавание on-demand (руками) и через политики происходит разными методами: ручной вариант имеет больший приоритет и стоит дороже (по текущему тарифу, этот механизм называется — «Онлайн-обработка файла» и стоит 0.
48руб/мин) для политик применяется более дешёвый механизм — «Отложенная обработка» (по текущему тарифу это стоит 0.18руб/мин).Файлы размером более 32MB должны загружаться через собственный API S3 и такой функционал в данной подсистеме не реализован (для ориентира: 10 минут записи весит около 5MB).


 48руб/мин) для политик применяется более дешёвый механизм — «Отложенная обработка» (по текущему тарифу это стоит 0.18руб/мин).
48руб/мин) для политик применяется более дешёвый механизм — «Отложенная обработка» (по текущему тарифу это стоит 0.18руб/мин).Чит-коды и работа из консоли сервера
В linux-консоли севера Staffcop — существуют несколько команд служащих для оценки количества данных и для запуска политики распознавания вручную.
Команда «sr_estimate»
Предназначена для оценки объёмов записей (количество и размер файлов, продолжительность аудио).
Для работы команды требуется, что бы предварительно была создана политика SpeechRecognitionPolicy (см. sr_mule ниже). Задать политику нельзя, будет выбрана одна из доступных произвольным образом.
Пример использования:
$ time staffcop sr_estimate --force --from-event=2021-12-01 Thread pool size: 3 2021-12-01: (745+41/786) duration:8.
 2h size:227m
2021-12-02: (0+49/49) duration:0m size:0m
2021-12-03: (0+37/37) duration:0m size:0m
2021-12-04: (0+1/1) duration:0m size:0m
2021-12-06: (0+24/24) duration:0m size:0m
2021-12-07: (0+23/23) duration:0m size:0m
2021-12-08: (0+17/17) duration:0m size:0m
2021-12-09: (0+74/74) duration:0m size:0m
2021-12-10: (53+0/53) duration:3m size:1m
real 1m4.300s
user 0m43.485s
sys 0m16.063s
2h size:227m
2021-12-02: (0+49/49) duration:0m size:0m
2021-12-03: (0+37/37) duration:0m size:0m
2021-12-04: (0+1/1) duration:0m size:0m
2021-12-06: (0+24/24) duration:0m size:0m
2021-12-07: (0+23/23) duration:0m size:0m
2021-12-08: (0+17/17) duration:0m size:0m
2021-12-09: (0+74/74) duration:0m size:0m
2021-12-10: (53+0/53) duration:3m size:1m
real 1m4.300s
user 0m43.485s
sys 0m16.063s
Параметры:
–force – обрабатывать все события политики включая те, которые были успешно «распакованы» ранее, например при использовании команды sr_mule
–threads – число потоков
–from-event – идентификатор или дата (в формате YYYY-MM-DD) события, начиная с которого будет происходить обработка
–to-event – идентификатор или дата события, до которого (но не включая его) будет происходить обработка
Команда «sr_mule»
Предназначена для запуска mule в консольном режиме с предварительной настройкой некоторых параметров.
При первом запуске будет создана политика SpeechRecognitionPolicy, если в базе нет ни одной такой политики. Если политик несколько, по аналогии с sr_estimate, будет выбрана произвольная.
Пример первого запуска для создания политики:
$ staffcop sr_mule --to-event=0 Process #13448 has unsafe gevent patches, try to reexec [Errno 9] fd:11 Server exit after 0.1s of work
Параметры:
–debug – вывод отладочной информации (без этого ключа будет очень скучно, рекомендую к использованию всегда)
–force – обрабатывать все события политики включая те, которые были успешно «распакованы» ранее, например при использовании команды sr_mule
–simulate – не отправляет аудио на сервер Tinkoff-а, вместо этого в результаты подставляется случайный текст (используется для отладки)
–keep-normal-audio – сохраняет перекодированное аудио после распознавания, оно будет использовано при повторных запусках (опять же, нужно в первую для отладки), это аудио так же сохраняется в случае ошибок в процессе распознавания
–threads – число потоков, которые будут использоваться для кодирования и отправки аудио на внешний сервер (по-умолчанию 10)
–watch-threads – число потоков, которые будут использоваться для получения результатов (по-умолчанию 3)
–bucket-size – размер пакета (число событий) для параллельной обработки (по-умолчанию 50)
–from-event – идентификатор или дата (в формате YYYY-MM-DD) события, начиная с которого будет происходить обработка
–to-event – идентификатор или дата события, до которого (но не включая его) будет происходить обработка
Ещё один пример:
$ staffcop sr_mule --force --debug --simulate --keep-normal-audio --from-event=2021-12-10 Process #14011 has unsafe gevent patches, try to reexec [Errno 9] fd:11 Starting <TinkoffRecognitionEngine at 0x7fa12880ddd0>.
 ..
Loop step (tasks:0 threads:0+0)
Recognize speech for #3602820
Recognize speech for #3603717
Recognize simulation #3602820 (0.8s)
[...]
Loop step (tasks:1 threads:1+0 RECOGNITION:1)
Recognition result #3606172: (6.0s) "Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
Save result for #3606172 (74.4s)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Server exit after 7.6s of work
Shutdown <TinkoffRecognitionEngine at 0x7fa12880ddd0>...
..
Loop step (tasks:0 threads:0+0)
Recognize speech for #3602820
Recognize speech for #3603717
Recognize simulation #3602820 (0.8s)
[...]
Loop step (tasks:1 threads:1+0 RECOGNITION:1)
Recognition result #3606172: (6.0s) "Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
Save result for #3606172 (74.4s)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Server exit after 7.6s of work
Shutdown <TinkoffRecognitionEngine at 0x7fa12880ddd0>...
Конфигурирование модуля из файла конфигурации сервера
В локальной конфигурации сервера /etc/staffcop/config — возможно задать ключи для работы сервера распознавания Tinkoff вручную:
TINKOFF_API_KEY = „…“ — ключи полученные из Tinkoff SpeechKit.
TINKOFF_SECRET_KEY = „…“ — ключи полученные из Tinkoff SpeechKit.
SPEECH_RECOGNITION_DEBUG — добавляет отладочной информации в логи.
SPEECH_RECOGNITION_AUDIO_DURATION_MIN — нижний порог продолжительности исходного аудио в сек. (по-умолчанию 3), записи меньшей продолжительностью будут пропущены с ошибкой [AudioDurationError].
TINKOFF_JWT_EXPIRATION — время устаревания JWT-токена используемого в API Tinkoff в сек. (по-умолчанию 600).
SPEECH_RECOGNITION_ATTEMPTS_LIMIT — максимальное количество попыток распознавания (по-умолчанию 5).
SPEECH_RECOGNITION_NORMAL_CMDLINE (по умолчанию — «ffmpeg -y -v 16 -i $source_file -map_metadata -1 -map 0:a:0 -ac 1 -aq 3 $normal_file») — Запись с одного устройства — одна дорожка в исходном аудио. В результате конвертации будет моно.
SPEECH_RECOGNITION_NORMAL2_CMDLINE (по умолчанию — «ffmpeg -y -v 16 -i $source_file -map_metadata -1 -filter_complex «[0:a]amerge=inputs=2,pan=stereo|FL<c0+c1|FR<c2+c3» -aq 3 $normal_file») — Запись с двух устройств — две дорожки в исходном аудио.
В результате конвертации будет стерео, а результат распознавания будет интерпретироваться как диалог.
 В результате конвертации будет стерео, а результат распознавания будет интерпретироваться как диалог.
В результате конвертации будет стерео, а результат распознавания будет интерпретироваться как диалог.Обработка ошибок
После обработки группы событий из выборки размерностью POLICY_BATCH (см. settings.py, по-умолчанию 10000, выборка происходит по Event.id, так что считать нужно все события, а не только отфильтрованные «звуковые», это стандартный механизм мулов) в данных политики сохраняется информация о необходимости выполнить повторную обработку (см. SpeechRecognition.data_dict[„restore_attempts“], _schedule_restore_attempts и _restore_attempt)
Эта повторная обработка выполняется перед следующей итерацией политики, т.е. при обработке следующей выборки размерностью POLICY_BATCH,
Важное замечание: если этой итерации нет (все события обработались на предыдущем шаге и новых событий в БД нет), то и попытки восстановления не будет (до тех пор, пока не появятся новые данные)
При выборе в настройках политики «Apply to all events (can take long time)» (применить ко всем событиям), «restore_attempts» — сбрасывается.
При большом количестве ошибок (~ >= 66% на 150 отфильтрованных событий) — политика будет отключена, но что бы увидеть это в интерфейсе, веб-страницу придётся обновить, если она была открыта ранее (речь об основном одностраничном интерфейсе).

Модуль распознавания голоса | Сделай сам своими руками
Приветствую вас, дорогие друзья. Наконец-то я добрался до записи урока по работе с голосовым модулем. Вижу вам понравилась моя самоделка с голосовым управлением и многие уже начали интересоваться, когда же выйдет практический урок по работе с модулем голосового управления.
О плюсах данного модуля распознавания:
— Модуль автономный и может работать без внешнего управляющего контроллера, что очень важно для радиолюбителей не знакомых с программированием.
— На ряду с другими моделями данный модуль выгодно отличается функциональностью, ценой и относительной простотой в управлении и подключении.
— Имеет высокую распознавающую способность.
— Никакого смартфона не требуется.
И так поехали! Данное видео будет направлено в первую очередь на новичков, тех, кто не знаком с программирование и интерфейсами, в общем для обычных радио любителей. В видео я покажу всё от «А» до «Я»: начнем с установки программ и подключения и закончим конкретным результатом автономной работы модуля.
Начнем же мы все равно с теоретических знаний, дабы понимать, как же все-таки работает это чудо инженерной мысли. Перво-наперво вам нужно знать некоторые характеристики данного модуля распознавания голоса:
Потребляемый ток: не более 40 мА, ток не критичный, так что просто учтите. Напряжение питания – 5 В, мы будем питать модуль USB порта компьютера при программировании, а дальше при работе вы сами решите от чего запитывать. Точность распознавания голосовой команды – 99% при идеальных условиях. Модуль распознавания голоса версии V3.1 способен запомнить 80 голосовых команд! Что на мой взгляд вполне достаточно для любых целей. Но опять же это «НО». Но модуль в единицу времени может распознавать только семь любых команд, а каких сень команд – выбирать вам.
Но модуль в единицу времени может распознавать только семь любых команд, а каких сень команд – выбирать вам.
То есть, вы можете записать в базу все 80 команд, но для распознавания выбрать только семь, любых семь из восьмидесяти. Это как с компьютером: на жестки диск можно записать 80 команд, а в оперативной памяти работать только с 7-ю командами. Если вам трудно это сейчас понять, то чуть позже на практике, я думаю, вам станет ясно о чём идет речь. Длинна голосовой команды – 1,5 секунды (1500мс) максимальное значение. Управлять платой модуля можно по интерфейсу UART, а вот снимать информацию можно как UART, так с портов GPIO, расположенных на плате. Собственно говоря, чем мы и займемся: будем снимать сигнал с выхода порта.
Переходим к практической части.
Что же нам понадобиться для работы?
— Сам модуль распознавания голоса версии V3 (V3.1) Версия не так важна – принцип работы у всех одинаков. Модуль идет с микрофоном.
— Руководство по модулю, то есть дата шит.
— Программу терминала.
— Преобразователь интерфейсам USB-UART.
Все ссылки на покупку и скачивание софта под видео, в конце статьи.
Вот и всё. Как говорил Гагарин – «Поехали».
Скачиваем руководство и терминал. Терминал устанавливаем. Подключаем модуль к преобразователю интерфейса.
Будьте очень внимательны при подключении. Не страшно, если вы перепутаете TXD и RXD, ничего страшного не произойдёт. А вот если вы перепутаете плюс питания с общим проводом – это будет катастрофа! Как случилось у меня – сразу сгорел модуль и порт компьютера! Будьте очень внимательны и не повторяйте моих ошибок. Не суетитесь, не спешите, проверьте цепь несколько раз перед включением, и только после этого подключайте к USB.
После подключения к USB ваша система начнет поиск драйверов к преобразователю, в 90% случаев система сама находит драйвер и устанавливает его, но если этого по каким-то причинам не произошло, то вам буден нужно самим найти драйвер в сети и установить его. Для этого в поисковой строке напишите «CP2102 драйвер скачать» или типа того, модуль распространенный, вариантов драйверов полно.
Для этого в поисковой строке напишите «CP2102 драйвер скачать» или типа того, модуль распространенный, вариантов драйверов полно.
Далее, после успешной установки оборудования идем в диспетчер устройств и смотрим порты. Нас интересует присвоенный номер нашего преобразователя. Когда узнали номер порта запускаем терминал. Идем в настройки и устанавливаем значения как у меня на рисунке.
Пишем в окне терминала команду – «AA 02 00 0A» (из даташита | AA | 02 | 00 | 0A |). Во всех командах всегда буквы заглавные и латинские.
Поле отправки вам должен последовать ответ, типа: «AA 08 00 STA BR IOM IOPW AL GRP 0A» (или из даташита | AA | 08 | 00 | STA | BR | IOM | IOPW | AL | GRP | 0A |). Если ответ пришел, то все отлично, пол дела сделано. Если нет, играемся с настройками настройками скорости передачи в терминале, просто возможно модуль настроен на другую скорость.
Я не буду останавливаться на том что означает данный ответ модуля, это вы сами сможете посмотреть в инструкции. А команда — это запрос установленных настроек.
А команда — это запрос установленных настроек.
Теперь необходимо подключить нагрузку к модулю. В роле нагрузки я буду использовать светодиоды с резисторами. Ну в дальнейшем, при эксплуатации эти светодиоды будут заменены на реле управления нагрузкой с транзисторными ключами, думаю это понятно.
Поясню саму команду «AA 02 00 0A» — это пакет состоящий из 4 байт, байты — это попарные символы в шестнадцатеричной системе – AA,02,00,0A. Во всех командах пакет будет начинаться байтом AA и заканчиваться байтом 0A (Ноль и A) – это обязательное условие. Ответы модуля будут так же начинаться и заканчиваться этими символами.
«AA 02 00 0A» — второй байт этой команды означает количество байт между байтами начала и конца, короче кроме AA и 0A. А все что между ними считаем и пишем во второй байт. Как видим в этом примере, что между AA и 0A стоят два байта — 02 00, следовательно – 02, то есть число считает само себя. Еще пример, «AA 03 20 01 0A» то есть между AA и 0A стоят три байта — «03 20 01», следовательно, второй байт – 03. Думаю, Вам будет понятно.
Еще пример, «AA 03 20 01 0A» то есть между AA и 0A стоят три байта — «03 20 01», следовательно, второй байт – 03. Думаю, Вам будет понятно.
Команда «12» — настройка портов модуля.
На плате модуля расположены порты, с которых мы будем снимать сигнал, прежде чем это делать, необходимо настроить эти порты. Настроить порты можно это командой
«AA 03 12 01 0A» — третий байт — это команда, а четвертый значение команды. Четвертый байт может принимать следующие значения и задавать следующие опции: если «00» — режим импульса, то есть при распознавании голосовой команды, на нужный нам порт подается короткий импульс. Если «01» — режим инверсии, то есть при распознавании голосовой команды, на нужный нам порт сменит состояние на противоположное, если был 0 – станет 1 и наоборот. Если «02» — режим при котором порт переходит в ноль. Если «03» — режим при котором порт переходит в единицу.
Команда «20» — настройка портов модуля.
«AA 03 20 01 0A» — третий байт — это номер команды, которую мы будем записывать. Пример записи двух команд 1 и 2: «AA 04 20 01 02 0A». Пример записи двух команд 1, 2, 3: «AA 05 20 01 02 03 0A».
Команда «30» — загрузка записи в «распознаватель» модуля.
«AA 03 30 01 0A» — третий байт команда загрузки в память распознавателя записи 01. Если нужно записать две команды — «AA 04 30 01 02 0A», если нужно записать все семь команд — «AA 09 30 01 02 03 04 05 06 07 0A».
Команда «15» — Автозагрузка голосовых команд в распознаватель при включении питания – автономный режим работы без внешнего контроллера.
«AA 03 15 07 01 02 03 0A» — третий байт команда, четвертый байт метка команд, то есть своеобразный идентификатор, и равен 01 для загрузки одной команды, 03 – для загрузки двух команд, 07 – для загрузки трех команд и так далее, смотрите в даташит таблицу.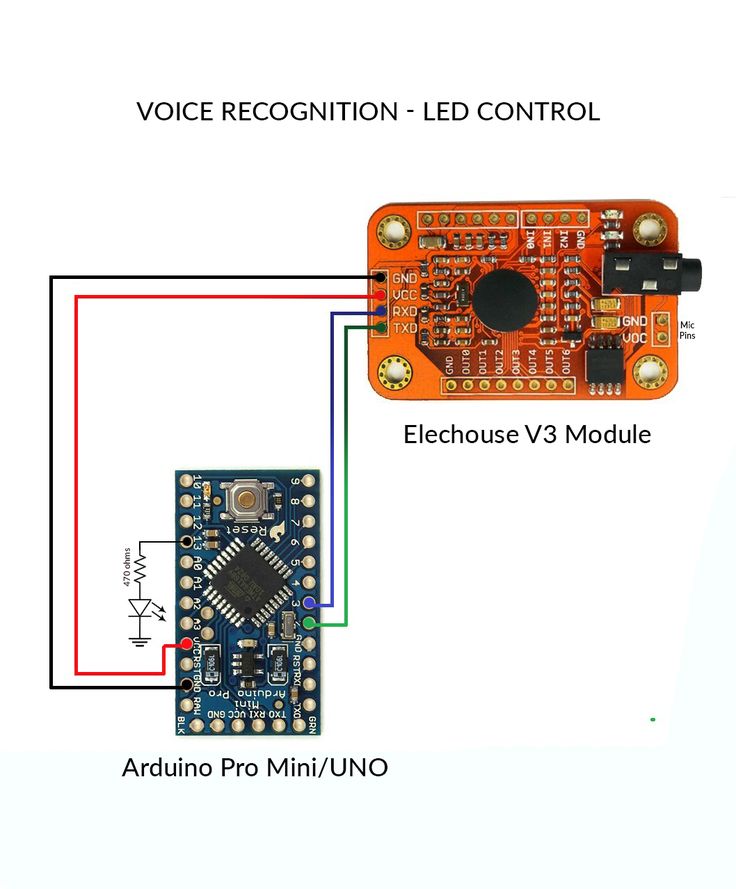 Ну а дальше идут номера команд, которые нужно загружать.
Ну а дальше идут номера команд, которые нужно загружать.
Вот и всё: проверили связь с модулем, сконфигурировали порты, записали команды, настроили автозагрузки голосовых команд.
Об остальных командах читайте в даташит. Я лишь объяснил примерный вид работы с модулем.
Ссылки для покупки:
Модуль – http://ali.pub/dk0gv
Преобразователь — http://ali.pub/fhond
Преобразователь с проводами — http://ali.pub/hlvn5
Ссылки для скачивания:
Дата шит – http://www.elechouse.com/elechouse/images/product/VR3/VR3_manual.pdf
Терминал — http://www.sudt.com/download/AccessPort137.zip
Speak Recognition, Модуль распознавания голоса V3 MOD54
Описание
Модуль распознавания голоса представляет собой компактную и простую в управлении плату распознавания речи. Этот продукт представляет собой модуль распознавания голоса, зависящий от говорящего. Всего он поддерживает до 80 голосовых команд. Максимум 7 голосовых команд могут работать одновременно. Любой звук можно обучить как команду. Пользователям необходимо сначала обучить модуль, прежде чем позволить ему распознавать любую голосовую команду.
Всего он поддерживает до 80 голосовых команд. Максимум 7 голосовых команд могут работать одновременно. Любой звук можно обучить как команду. Пользователям необходимо сначала обучить модуль, прежде чем позволить ему распознавать любую голосовую команду.
Особенность
- Поддержка максимум 80 голосовых команд, каждый голос 1500 мс (произнесение одного или двух слов)
- Максимум 7 голосовых команд действуют одновременно
- Библиотека Arduino поставляется в комплекте
- Простое управление: UART/GPIO
- Общий контактный вывод пользовательского управления
- Напряжение: 4,5–5,5 В
- Ток: <40 мА
Обзор
Модуль распознавания голоса ELECHOUSE представляет собой компактную и простую в управлении плату распознавания речи.
Этот продукт представляет собой модуль распознавания голоса, зависящий от говорящего. Всего он поддерживает до 80 голосовых команд.
Всего он поддерживает до 80 голосовых команд.
Максимум 7 голосовых команд могут работать одновременно. Любой звук можно обучить как команду. Пользователям необходимо сначала обучить модуль
, прежде чем позволить ему распознавать любую голосовую команду.
Эта плата имеет 2 способа управления: последовательный порт (полная функция), общие входные контакты (часть функции). Общие
Выходные контакты на плате могли генерировать несколько типов волн, в то время как соответствующая голосовая команда
распознавалась.
Pin-out description
VCC: positive power supply pin
GND: ground power supply pin
RXD: Receiver pin from Arduino
TXD: Transmitter pinto Arduino
Hardware connection
- Подключите модуль Voice Recognition V3 к Arduino, по умолчанию так:
2. Загрузите библиотеку VoiceRecognitionV3.
3. Если вы используете zip-файл, извлеките VoiceRecognitionV3. zip в папку Arduino Sketchlibraries.
zip в папку Arduino Sketchlibraries.
Train
- Open vr_sample_train (Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_train)
- Выберите правильную плату Arduino (Tool -> Board, UNO рекомендует)
- Нажмите кнопку Upload , дождитесь загрузки Arduino.
- Открыть серийный монитор . Установить скорость передачи 115200, установить отправку с Новая строка или Оба NL и CR.
5. Отправьте настройки команды (без учета регистра), чтобы проверить настройки модуля распознавания голоса. Введите настройки и нажмите Enter, чтобы отправить.
6. Обучить модуль распознавания голоса. Отправить sigtrain 0 On команду на поезд записи 0 с подписью
«On». Когда Serial Monitor печатает «Говори сейчас», вам нужно говорить своим голосом (может быть любым словом, 9Рекомендуется использовать значимое слово 0037, здесь может быть «Вкл. »), и когда Serial Monitor напечатает «Произнесите
»), и когда Serial Monitor напечатает «Произнесите
еще раз», вам нужно повторить свой голос еще раз. Если эти два голоса совпадают, Serial Monitor печатает
«Успех», и «запись 0» обучается, или, если они не совпадают, повторяйте произнесение до успеха.
Что такое подпись? Подпись — это текстовое описание голосовой команды. Например, для
, если ваша 7 голосовая команда «1, 2, 3, 4, 5, 6, 7», вы можете тренироваться следующим образом:
sigtrain 0 one
sigtrain 1 два
sigtrain 2 три
sigtrain 3 четыре
sigtrain 4 пять
sigtrain 5 шесть
sigtrain 6 семь
Подпись могла отображаться, если была вызвана соответствующая команда.
Во время тренировки два светодиода на модуле распознавания голоса могут указывать на ваш тренировочный процесс.
После отправки обучающей команды светодиод SYS_LED (желтый) быстро мигает, напоминая вам, что
нужно приготовиться. Произнесите голосовую команду, как только загорится индикатор STATUS_LED (красный).
Процесс записи завершается один раз, когда гаснет индикатор STATUS_LED (красный). Затем снова замигает светодиод SYS_LED
, будьте готовы к следующему процессу записи. Когда процесс обучения завершается успешно, индикаторы
SYS_LED и STATUS_LED мигают вместе. Если обучение не удается, индикаторы SYS_LED и STATUS_LED
мигают вместе, но быстро.
7. Обучите другую запись. Отправьте команду sigtrain 1 Off для записи поезда 1 с подписью «Off».
Выберите ваши любимые слова для тренировки (это может быть любое слово, рекомендуется значимое слово, может быть
«Выкл.» здесь)
8. Отправьте команду загрузки 0 1 для загрузки голоса. И скажите свое слово, чтобы увидеть, может ли модуль распознавания голоса
распознавать ваши слова.
Если голос распознан, вы можете увидеть
9. Финиш поезда. Образец поезда также поддерживает несколько других команд.
Пример управления светодиодом
Здесь мы показываем простой пример, показывающий, как управлять светодиодом на плате Arduino (подключение к
pin13) с помощью голосовых команд. Перед этим примером вам нужно сначала обучить модуль VR способом
Перед этим примером вам нужно сначала обучить модуль VR способом
, как показано выше vr_sample_train. Используйте следующие команды:
● sigtrain 0 on Обучение голосовой команде, используемой для включения светодиода
● sigtrain 0 off Обучение голосовой команде, используемой для выключения светодиода
Затем выполните следующие действия:
1. Откройте vr_sample_control_led (Файл -> Примеры -> VoiceRecognitionV3 ->
vr_sample_control_led)
2. Выберите правильную плату Arduino (Tool -> Board, рекомендуется UNO), выберите правильный последовательный порт.
3. Нажмите кнопку «Загрузить», дождитесь загрузки Arduino.
4. Откройте последовательный монитор. Установите скорость передачи 115200.
5. Вы увидите индикацию:
Произнесите голосовые команды, которые вы обучали выше, и проверьте состояние светодиода на Arduino.
Вы также можете выполнять другие команды, так как он может сохранить до 7 различных голосовых команд.
Ресурсы:
Библиотека: Библиотека VoiceRecognition V3
Эскиз Arduino:
Эскиз vr_sample_train
vr_sample_control_led sketch
ESP32 Поддержка модуля распознавания голоса Elechouse V3 — Frank’s Random Wanderings
frank Компьютеры, электроника, ESP32, программирование Комментариев нет
В рамках недавнего проекта по добавлению автономного голосового управления к осциллографу я хотел соединить модуль распознавания голоса Elechouse V3 с ESP32. Это сработало довольно хорошо, поэтому я делаю информацию об оборудовании и программном обеспечении доступной здесь.
Аппаратное обеспечение
Несколько соображений при соединении двух модулей вместе:
- Elechouse VR3 представляет собой модуль на 5 В, а контакты на ESP32 не рассчитаны на 5 В. Следовательно, выходной контакт UART 5 В от VR3 необходимо уменьшить до 3,3 В для входного контакта ESP32. Это легко сделать с помощью двух резисторов.
- ESP32 имеет 3 последовательных порта. По умолчанию первый, U0UXD, используется для последовательного порта USB, в том числе для программирования. Второй, U1UXD, обычно используется для подключения к флэш-чипу SPI. Следовательно, только третий UART, U2UXD, действительно безопасен в использовании. По этой причине как схема подключения, показанная ниже, так и программное обеспечение предполагают, что Elechouse VR3 подключен к третьему UART, U2UXD.
 Следовательно, выходной контакт UART 5 В от VR3 необходимо уменьшить до 3,3 В для входного контакта ESP32. Это легко сделать с помощью двух резисторов.
Следовательно, выходной контакт UART 5 В от VR3 необходимо уменьшить до 3,3 В для входного контакта ESP32. Это легко сделать с помощью двух резисторов.Вот как соединить модули вместе:
ESP32 — Электропроводка Elechouse VR3
Модуль ESP32 получает питание от своего USB-порта и обеспечивает его для Elechouse VR3. В зависимости от конкретной платы ESP32, которую вы используете, выходной контакт 5V на плате ESP32 может называться 5V или называться (несколько запутанно) VIN.
Программное обеспечение
Программное обеспечение использует Arduino, работающую на ESP32. Вот простое руководство по его настройке:
Вот простое руководство по его настройке:
Installing the ESP32 Board in Arduino IDE (Windows, Mac OS X, Linux)
Я выбрал плату «ESP32 Dev Module».
Убедитесь, что вы можете следовать небольшому руководству, чтобы собрать / запрограммировать / запустить пример. Если у вас возникли проблемы с программированием платы, попробуйте нажать кнопку «загрузка» на несколько секунд на этапе программирования.
Теперь установите библиотеку Voice Recognition V3. Следуйте инструкциям на странице Elechouse github здесь:
GitHub — elechouse/VoiceRecognitionV3: библиотека Arduino для модуля elechouse Voice Recognition V3
По сути, это просто загрузка ZIP-файла и его распаковка в указанное место. НО, Elechouse предоставляет более старую библиотеку arduino, которая не полностью работает на ESP32. После того, как вы установили библиотеку Elechouse, перезапишите 4 из этих файлов моими обновленными файлами отсюда:
Или, если хотите, вы можете скачать их по отдельности с github здесь.
Это файлы, специфичные для ESP32; они не будут работать на Atmel/Microchip Arduino. Но они работают для ESP32 Arduino. Файлы:
- VoiceRecognitionV3.cpp и .h
- vr_sample_train.ino
- vr_sample_bridge.ino
VoiceRecognitionV3.cpp и .h — это основной файл библиотеки. Они были изменены для работы с ESP32 путем обновления вызовов последовательного порта для использования собственных функций последовательного порта ESP32. Кроме того, последовательный порт был жестко закодирован (в методе «начало») для использования порта U2UXD. При создании экземпляра класса вы можете передать другие номера выводов, но они игнорируются — эти параметры сохраняются для обратной совместимости, но в остальном игнорируются.
Передача от ESP32 к VR3 также немного замедлилась. Между последовательными байтами при отправке команд на VR3 была вставлена небольшая задержка — похоже, это повышает надежность.
VR3 по умолчанию использует скорость 9600 бод, поэтому при вызове метода «begin» всегда передавайте 9600, если скорость передачи VR3 не была явно изменена.
vr_sample_train.ino и vr_sample_bridge.ino — два очень полезных примера, предоставленных Elechouse. Единственным изменением, внесенным в эти два файла, является удаление этой строки:
#include
из каждого из них. Поскольку SoftwareSerial не применим к ESP32 Arduino и приводит к ошибке сборки.
Чтобы узнать, как и зачем использовать vr_sample_train и vr_sample_bridge, см. документацию Elechouse
https://www.elechouse.com/elechouse/images/product/VR3/VR3_manual.pdf
или мой проект голосового управления осциллографом, где я описать, как обучать и использовать модуль VR3.
Резюме
Вот и все. Немного простой проводки, включая пару резисторов. Arduino на ESP32 с обновленными программными файлами ESP32 Elechouse Voice Recognition V3. Затем вы можете обучать VR3 своими словами, а ESP32 делать что-то, когда эти слова произносятся. Для голосового управления осциллографом это работает довольно хорошо.