
Расчет ш образного трансформатора по железу
Иногда приходится самостоятельно изготовлять силовой трансформатор для выпрямителя. В этом случае простейший расчет силовых трансформаторов мощностью до — Вт проводится следующим образом. Зная напряжение и наибольший ток, который должна давать вторичная обмотка U2 и I2 , находим мощность вторичной цепи: При наличии нескольких вторичных обмоток мощность подсчитывают путем сложения мощностей отдельных обмоток. Мощность передается из первичной обмотки во вторичную через магнитный поток в сердечнике. Поэтому от значения мощности Р1 зависит площадь поперечного сечения сердечника S, которая возрастает при увеличении мощности. Для сердечника из нормальной трансформаторной стали можно рассчитать S по формуле:.
Поиск данных по Вашему запросу:
Схемы, справочники, даташиты:
Прайс-листы, цены:
Обсуждения, статьи, мануалы:
Дождитесь окончания поиска во всех базах.

По завершению появится ссылка для доступа к найденным материалам.
Содержание:
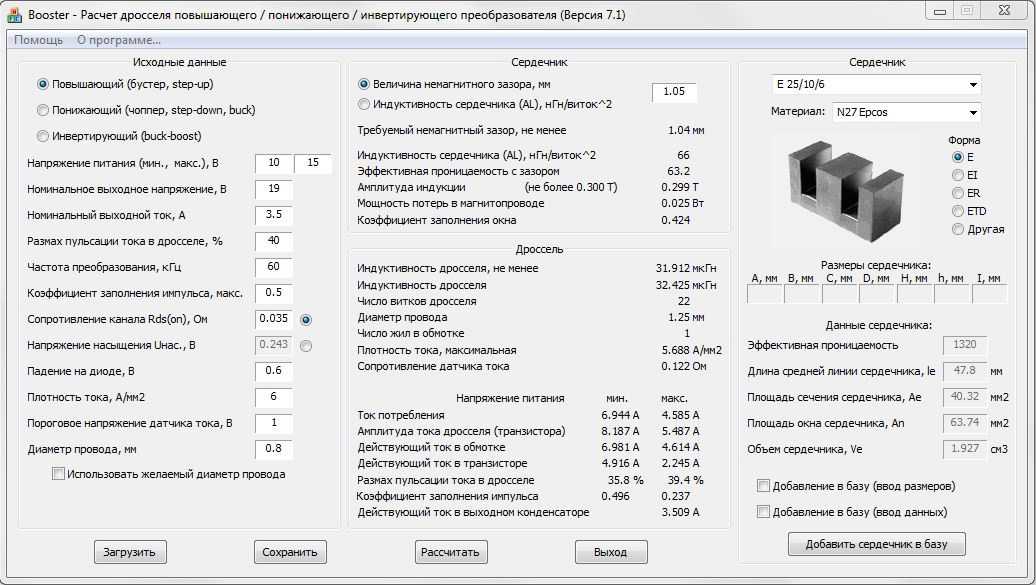
- Калькулятор расчёта трансформатора
- Расчёт трансформатора на калькуляторе в домашних условиях
- Силовой трансформатор, расчёт силового трансформатора
- Научный форум dxdy
- Расчет трансформатора, онлайн калькулятор
- Мощность трансформатора по сечению железа. Расчет трансформатора
- Расчет Ш-образного трансформатора
ПОСМОТРИТЕ ВИДЕО ПО ТЕМЕ: Намотка и расчет трансформатора. ПОДРОБНО!
 youtube.com/embed/7gyXZyfxRiU» frameborder=»0″ allowfullscreen=»»/>
youtube.com/embed/7gyXZyfxRiU» frameborder=»0″ allowfullscreen=»»/>Калькулятор расчёта трансформатора
Классический теоретический расчет трансформатора достаточно сложен Для его выполнения необходимо знать такие характеристики, как магнитная проницаемость используемых для сердечника пластин трансформаторной стали, длина магнитных силовых линий в сердечнике, средняя длина витка обмотки и другие параметры Профессиональному разработчику НИИ все эти параметры известны, так как он обладает сертификатами применяемых в трансформаторе материалов Радиолюбитель же вынужден использовать для трансформатора совершенно случайно попавший к нему сердечник, характеристики которого ему неизвестны.
По указанной причине для расчета трансформатора предлагается эмпирический метод, многократно проверенный радиолюбителями и основанный на практическом опыте Расчет элементарно прост и требует лишь знания простейших основ арифметикиПринцип действия трансформатора.
Рис 61 Трансформатор : а — общий вид б — условное обозначение. Трансформатор был изобретен П Н Яблочковым в году Устройство трансформатора показано на рис 61а, а его схематическое обозначение — на рис Трансформатор состоит из стального сердечника и обмоток, намотанных изолированным обмоточным проводом.
Сердечник собирается из тонких пластин специальной электротехнической стали для снижения потерь энергии. Обмотка, предназначенная для подключения к сети переменного тока, называется первичной Нагрузка подключается к вторичной обмотке, которых в трансформаторе может быть несколько Номера обмоток обычно проставляются римскими цифрами Часто обмоткам присваивают номера их выводов.
Работа трансформатора основана на магнитном свойстве электрического тока При подключении концов первичной обмотки к электросети по этой обмотке протекает переменный ток, который создает вокруг ее витков и в сердечнике трансформатора переменное магнитное поле Пронизывая витки вторичной обмотки, переменное магнитное поле индуцирует в них ЭДС Соотношение количества витков первичной и вторичной обмоток определяет получаемое напряжение на выходе трансформатора Если количество витков вторичной обмотки больше, чем первичной, выходное напряжение трансформатора будет больше напряжения сети Такая обмотка называется повышающей Если же вторичная обмотка содержит меньше витков, чем первичная, выходное напряжение окажется меньше сетевого понижающая обмотка.
Трансформатор — это пассивный преобразователь энергии Его коэффициент полезного действия КПД всегда меньше единицы Это означает, что мощность, потребляемая нагрузкой, которая подключена к вторичной обмотке трансформатора, меньше, чем мощность, потребляемая нагруженным трансформатором от сети Известно, что мощность равна произведению силы тока на напряжение, следовательно, в повышающих обмотках сила тока меньше, а в понижающих — больше силы тока, потребляемого трансформатором от сети.
Два разных трансформатора при одинаковом напряжении сети могут быть рассчитаны на получение одинаковых напряжений вторичных обмоток Но если нагрузка первого трансформатора потребляет большой ток, а второго — маленький, значит, первый трансформатор характеризуется по сравнению со вторым большей мощностью Чем больше сила тока в обмотках трансформатора, тем больше и магнитный поток в его сердечнике, поэтому сердечник должен быть толще Кроме того, чем больше сила тока в обмотке, тем более толстым проводом она должна быть намотана, а это требует увеличения окна сердечника Поэтому габариты трансформатора зависят от его мощности И наоборот, сердечник определенного размера пригоден для изготовления трансформатора только до определенной мощности, которая называется габаритной мощностью трансформатора.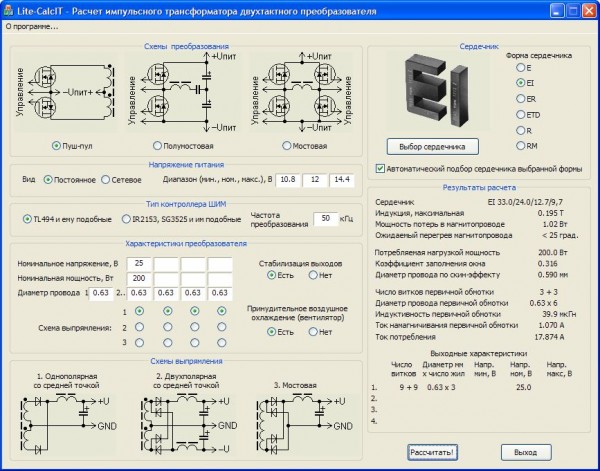
Количество витков вторичной обмотки трансформатора определяет напряжение на ее выводах Но это напряжение зависит также и от количества витков первичной обмотки При определенном значении напряжения питания первичной обмотки напряжение вторичной зависит от отношения количества витков вторичной обмотки к количеству витков первичной Это отношение и называется коэффициентом трансформации. Если напряжение на вторичной обмотке зависит от коэффициента трансформации, можно ли выбирать количество витков одной из обмоток, например первичной, произвольно Оказывается, нельзя Дело в том, что чем меньше габариты сердечника, тем больше должно быть количество витков каждой обмотки Поэтому размеру сердечника трансформатора соответствует вполне определенное количество витков его обмоток, приходящееся на один вольт напряжения, меньше которого брать нельзя Эта характеристика называется количеством витков на один вольт.
Как и всякий преобразователь энергии, трансформатор обладает коэффициентом полезного действия — отношением мощности, потребляемой нагрузкой трансформатора, к мощности, которую нагруженный трансформатор потребляет от сети.![]() КПД маломощных трансформаторов, которые обычно применяются для питания бытовой электронной аппаратуры, колеблется в пределах от 0,8 до 0,95 Более высокие значения имеют трансформаторы большей мощности.
КПД маломощных трансформаторов, которые обычно применяются для питания бытовой электронной аппаратуры, колеблется в пределах от 0,8 до 0,95 Более высокие значения имеют трансформаторы большей мощности.
Прежде чем начать электрический расчет силового трансформатора, необходимо сформулировать требования, которым он должен удовлетворять Они и будут являться исходными данными для расчета Технические требования к трансформатору определяются также путем расчета, в результате которого определяются те напряжения и токи, которые должны быть обеспечены вторичными обмотками Поэтому перед расчетом трансформатора производится расчет выпрямителя для определения напряжений каждой из вторичных обмоток и потребляемых от этих обмоток токов Если же напряжения и токи каждой из обмоток трансформатора уже известны, то они и являются техническими требованиями к трансформатору.
Для определения габаритной мощности трансформатора необходимо определить мощности, потребляемые от каждой вторичной обмотки, и сложить их, учитывая также КПД трансформатора Мощность, потребляемую от любой обмотки, определяют умножением напряжения между выводами этой обмотки на силу потребляемого от нее тока:.![]()
Для определения габаритной мощности трансформатора полученное значение суммарной мощности P s нужно разделить на КПД трансформатора:. Заранее рассчитать КПД трансформатора нельзя, так как для этого нужно знать величину потерь энергии в обмотках и в сердечнике, которые зависят от параметров самих обмоток диаметры проводов и их длина и параметров сердечника длина магнитной силовой линии и марка стали И те и другие параметры становятся известны только после расчета трансформатора Поэтому с достаточной для практического расчета точностью КПД трансформатора можно определить из табл Допустим, что нужно рассчитать трансформатор , имеющий три вторичные обмотки со следующими исходными данными:.
Наиболее распространены две формы сердечника: О-образная рис, 62а и Ш-образная рис, На сердечнике О-образной формы обычно располагаются две катушки, а на сердечнике Ш-образной формы — одна рис, 63 Зная габаритную мощность трансформатора, находят сечение рабочего керна его сердечника, на котором находится катушка:.
После этого выбирают тип пластин трансформаторной стали и определяют толщину пакета сердечника Сначала находят приблизительную ширину рабочего керна сердечника по формуле:. Затем по полученному значению а производят выбор типа пластин трансформаторной стали из числа имеющихся в наличии и находят фактическую ширину рабочего керна а, после чего определяют толщину пакета сердечника с:.
Количество витков, приходящихся на 1 вольт напряжения, определяется сечением рабочего керна сердечника трансформатора по формуле:. Зная необходимое напряжение каждой обмотки и количество витков на 1 В, легко определить количество витков обмотки, перемножив эти величины:. Такое соотношение справедливо только для первичной обмотки, а при определении количества витков вторичных обмоток нужно дополнительно вводить приближенную поправку для учета падения напряжения на самой обмотке от протекающего по ее проводу тока нагрузки:.
Коэффициент ш зависит от силы тока, протекающего по данной обмотке см табл Толщина провода, которым наматывается обмотка трансформатора, определяется силой тока, протекающего по этой обмотке Чем больше ток, тем толще должен быть провод, подобно тому как для. Выбрав коэффициент р, можно определить диаметр провода каждой обмотки Найденное значение диаметра округляют до большего стандартного.
Сила тока в первичной обмотке определяется с учетом габаритной мощности трансформатора и напряжения сети:. Находим приближенное значение ширины рабочего керна:. Определяем количество витков дополнительной секции первичной обмотки, которую необходимо подключить к обмотке, рассчитанной на В, для питания напряжением В:. Определяем количество витков каждой из вторичных обмоток с округлением до ближайшего целого числа:.
Обмотки трансформатора наматываются рядовой намоткой виток к витку с прокладками между слоями для обеспечения электрической изоляции одного слоя по отношению к соседнему, иначе возникнет пробой между витками обмоток Ведь между началом одного слоя и концом следующего, которые оказываются расположенными один под другим, действует значительное напряжение, соответствующее количеству витков двух слоев намотки и многократно превышающее допустимое напряжение для эмалевой изоляции Поэтому между слоями используются прокладки в виде одного слоя кабельной бумаги толщиной d, а между обмотками — три слоя такой же бумаги Иногда, если прочность электрической изоляции какой-либо обмотки нужно специально увеличить, между этой обмоткой и другими прокладывают дополнительно один или несколько слоев лакоткани.
При определении толщины обмотки сначала нужно подсчитать количество витков W , которое можно намотать в одном слое Для этого эффективную ширину окна следует разделить на диаметр провода по изоляции:. Полученное значение п,округляют до ближайшего большего целого числа, после чего определяют толщину обмотки t:.
Для определения толщины катушки нужно сложить значения толщины каждой обмотки и к результату прибавить толщину прокладок между обмотками:. Произведем конструктивный расчет трансформатора, который должен следовать за электрическим расчетом, проведенным ранее. Полученный результат позволяет сделать вывод о том, что намотка может быть выполнена вручную при средней квалификации намотчика.
В рубрике Радиолюбительские расчеты. Метки: витков количество обмотки обмоток первичной сердечника трансформатора.
Вы можете подписаться на новые комментарии к этой записи по RSS 2. Вы можете оставить комментарий к записе. Возможность оставить trackback со своего сайта отсутствует. Имя required. Почта не публикуется required. Ключи на полевых транзисторах в схемах на микроконтроллере Ручной регулятор мощности — варианты схем Последовательное и параллельное включение обмоток.
Имя required. Почта не публикуется required. Ключи на полевых транзисторах в схемах на микроконтроллере Ручной регулятор мощности — варианты схем Последовательное и параллельное включение обмоток.
Оптические датчики. Фоторезисторы в схемах на МК 5. Микросхемы маломощного высоковольтного импульсного преобразователя серии TNY2xx Генераторы высокого напряжения с емкостными накопителями энергии В рубрике Радиолюбительские расчеты Метки: витков количество обмотки обмоток первичной сердечника трансформатора Вы можете подписаться на новые комментарии к этой записи по RSS 2. Оставить комментарий Нажмите сюда для отмены комментария. Имя required Почта не публикуется required Сайт.
Подписаться на NauchebeNet.
Расчёт трансформатора на калькуляторе в домашних условиях
В радиолюбительской практике иногда возникает необходимость в изготовлении трансформатора с нестандартными значениями напряжения и тока. Хорошо, если удается подобрать готовый трансформатор с нужными обмотками, в противном случае трансформатор приходится изготавливать самостоятельно.![]() Эта страничка посвящена изготовлению силового трансформатора своими силами. В промышленных условиях расчет трансформатора — весьма трудоемкая работа, но для радиолюбителей созданы упрощенные методики расчета.
Эта страничка посвящена изготовлению силового трансформатора своими силами. В промышленных условиях расчет трансформатора — весьма трудоемкая работа, но для радиолюбителей созданы упрощенные методики расчета.
Расчет мощности линейного (не импульсного) трансформатора для 50Гц ( т.е. если это Ш образный сердечник, то высчитывается . Ведь для кровельного железа, по идее нужны уже совсем другие методы!.
Силовой трансформатор, расчёт силового трансформатора
На этой страничке приведен простой метод расчета параметров трансформатора для сетей питания промышленной частоты для России это V 50 Гц. Это может понадобиться для радиолюбительского творчества, ремонта и модификации трансформаторов. Обратите внимание, что даже если приведенный метод расчета и некоторые уравнения могли быть обобщены, здесь для упрощения вычислений принимались во внимание только классические сердечники трансформаторов с закрытым магнитным потоком, составленные из стальных пластин. Когда разрабатывается трансформатор, первый шаг в разработке состоит в выборе подходящего сердечника, чтобы трансформатор мог передать необходимую мощность.![]() Обычно чем больше мощность, тем больше должны быть размеры трансформатора. В действительности нет теоретических или физических ограничений на то, чтобы трансформатор меньшего размера мог передавать большую мощность. Но по практическим соображениям на сердечнике малого размера недостаточно места для размещения всех обмоток, поэтому можно выбрать только лишь сердечник не меньше определенного размера. Хороший базовый выбор может дать следующая эмпирическая формула для рабочей частоты трансформатора 50 Гц :. Площадь поперечного сечения S соответствует минимальному сечению магнитного потока в трансформаторе, и S можно определить по размерам участка магнитопровода, на котором расположены обмотки, как показано на рисунке ниже:. Рисунок выше показывает сердечник с двумя петлями магнитного потока, который применяется чаще всего из-за незначительного магнитного поля рассеивания, небольшого размера и технологичности в изготовлении трансформатора.
Обычно чем больше мощность, тем больше должны быть размеры трансформатора. В действительности нет теоретических или физических ограничений на то, чтобы трансформатор меньшего размера мог передавать большую мощность. Но по практическим соображениям на сердечнике малого размера недостаточно места для размещения всех обмоток, поэтому можно выбрать только лишь сердечник не меньше определенного размера. Хороший базовый выбор может дать следующая эмпирическая формула для рабочей частоты трансформатора 50 Гц :. Площадь поперечного сечения S соответствует минимальному сечению магнитного потока в трансформаторе, и S можно определить по размерам участка магнитопровода, на котором расположены обмотки, как показано на рисунке ниже:. Рисунок выше показывает сердечник с двумя петлями магнитного потока, который применяется чаще всего из-за незначительного магнитного поля рассеивания, небольшого размера и технологичности в изготовлении трансформатора.
Научный форум dxdy
Данный онлайн расчет трансформатора выполнен по типовым расчетам электрооборудования. В типовых расчётах все начинается с определения необходимой мощности вторичной обмотки, а уж потом с поправкой на КПД — коэффициент полезного действия, находим мощность всего трансформатора, и на основании этого рассчитываем необходимое сечение и тип сердечника и так далее. Изначально так и было в моём расчете. Пока не появились предложения от посетителей сайта внести изменения в расчет.
В типовых расчётах все начинается с определения необходимой мощности вторичной обмотки, а уж потом с поправкой на КПД — коэффициент полезного действия, находим мощность всего трансформатора, и на основании этого рассчитываем необходимое сечение и тип сердечника и так далее. Изначально так и было в моём расчете. Пока не появились предложения от посетителей сайта внести изменения в расчет.
Трансформатор на тороидальный магнитопроводе — самый компактный и эффективный, может использоваться при мощностях от 30 до Вт, а особенно — когда важно минимальное рассеяние магнитного потока или когда требование минимального объема является первостепенным. Имея преимущества в объеме, массе и характеристиках перед другими типами конструкций трансформаторов, тороидальные трансформаторы вместе с тем являются и наименее технологичными в изготовлении.
Расчет трансформатора, онлайн калькулятор
Забыли пароль? Изменен п. Расшифровка и пояснения — тут. Автор: ivan , 8 декабря в Общий. Затем первичные обмотки трансформаторов включить параллельно, а вторичные последовательно.
Мощность трансформатора по сечению железа. Расчет трансформатора
Для блока питания нужен трансформатор и Дима из мастерской Lumenus indi расскажет, как его рассчитать и намотать. Limenus indi вКонтакте. Наверно это некрасиво, но я скопирую статью, по которой был снят этот ролик к себе на сайт, что бы она всегда была доступна пользователям канала. Наиболее распространённые типы магнитопроводы изображены на рисунке. Ш-образные пластинчатые сердечники, аналогичны расчету Ш-образного ленточного сердечника. Тороидальный трансформатор может использоваться при мощностях от 30 до Вт, когда требуется минимальное рассеяние магнитного потока или когда требование минимального объема является первостепенным. Исходными начальными данными для упрощенного расчета являются:.
простой расчёт написан в конце первого поста. Для киловаттного трансформатора сечение провода первичной обмотки выбирается из . Стержневой (П-образный), броневой (Ш-образный) и тороидальный. Первое — площадь железа, второе — площадь пустоты (дырки) в железе.
Расчет Ш-образного трансформатора
Трансформатор — устройство, в котором переменный ток одного напряжения преобразовывается в переменный ток другого напряжения. При этом преобразовании напряжений одновременно всегда происходит также преобразование силы тока: если трансформатор повышает напряжение, то сила тока при этом уменьшается. Трансформатор представляет собой стальной сердечник с двумя катушками, имеющими обмотки. Одна из обмоток называется первичной, другая — вторичной.
Для изготовления трансформаторных блоков питания необходим силовой однофазный трансформатор, который понижает переменное напряжение электросети вольт до необходимых вольт, которое затем выпрямляется диодным мостом и фильтруется электролитическим конденсатором. Эти преобразования электрического тока необходимы, поскольку любая электронная аппаратура собрана на транзисторах и микросхемах, которым обычно требуется напряжение не более вольт. Чтобы самостоятельно собрать блок питания , начинающему радиолюбителю требуется найти или приобрести подходящий трансформатор для будущего блока питания. В исключительных случаях можно изготовить силовой трансформатор самостоятельно. Такие рекомендации можно встретить на страницах старых книг по радиоэлектронике.
В исключительных случаях можно изготовить силовой трансформатор самостоятельно. Такие рекомендации можно встретить на страницах старых книг по радиоэлектронике.
Классический теоретический расчет трансформатора достаточно сложен Для его выполнения необходимо знать такие характеристики, как магнитная проницаемость используемых для сердечника пластин трансформаторной стали, длина магнитных силовых линий в сердечнике, средняя длина витка обмотки и другие параметры Профессиональному разработчику НИИ все эти параметры известны, так как он обладает сертификатами применяемых в трансформаторе материалов Радиолюбитель же вынужден использовать для трансформатора совершенно случайно попавший к нему сердечник, характеристики которого ему неизвестны. По указанной причине для расчета трансформатора предлагается эмпирический метод, многократно проверенный радиолюбителями и основанный на практическом опыте Расчет элементарно прост и требует лишь знания простейших основ арифметикиПринцип действия трансформатора.
Простейший расчет силового трансформатора позволяет найти сечение сердечника, число витков в обмотках и диаметр провода. Переменное напряжение в сети бывает В, реже В и совсем редко В. Для питания анодных и экранных цепей электронных ламп чаще всего используют постоянное напряжение — В, для питания накальных цепей ламп переменное напряжение 6,3 В. Все напряжения, необходимые для какого-либо устройства, получают от одного трансформатора, который называют силовым. Силовой трансформатор выполняется на разборном стальном сердечнике из изолированных друг от друга тонких Ш-образных, реже П-образных пластин, а так же вытыми ленточными сердечниками типа ШЛ и ПЛ Рис.
Ведь не всегда найдётся, например, готовый сетевой трансформатор. Более актуальным этот вопрос становится, когда нужен анодно-накальный или выходной трансформатор для лампового усилителя. Здесь остаётся лишь запастись проволокой и подобрать хорошие сердечники.
Расчет трансформатора для сварочного полуавтомата, сварочного аппарата.

В этой статье попытаюсь вам рассказать, как рассчитать трансформатор для сварочного аппарата.
На самом деле ни чего сложного здесь нет. Этот расчет относится как к простым (П и Ш образным) так и к тороидальным трансформаторам.
Для начала определим габаритную мощность будущего сварочного трансформатора:
Где: Sc - площадь сечения сердечника см.кв. So - площадь сечения окна см.кв. f - рабочая частота трансформатора Гц. (50). J - плотность тока в проводе обмоток A/кв.мм (1.7..5). ɳ - КПД трансформатора (0,95). B - магнитная индукция (1..1,7). Km - коэффициент заполнения окна сердечника медью (0,25..0,4). Kc - коэффициент заполнения сечения сердечника сталью (0,96).
Подставляя нужные значения упрощаем формулу, она будет иметь вид:
P габаритн = 1.9*Sc*So для торов (ОЛ).
P габаритн = 1.7*Sc*So для ПЛ,ШЛ.
P габаритн = 1.5*Sc*So для П,Ш.
Например у нас ОЛ сердечник (тор).
Площадь сердечника Sс = 45 см.кв.
Площадь окна сердечника So = 80 см.кв.
Формула для тора (ОЛ):
P габаритн = 1.9*Sc*So
Где: P габаритн - габаритная мощность трансформатора в ваттах. Sc - площадь сердечника трансформатора в см.кв. So - площадь окна сердечника в см.кв.
P = 1.9*45*80 = 6840 ватт.
Далее нужно рассчитать количество витков для первичной и вторичной обмотки. Для этого сначала рассчитаем необходимое количество витков на 1 вольт.
Для этого используем формулу:
K = 50/S
Где: K - количество витков на вольт. S - площадь сердечника в см.кв. Вместо 50 в формулу подставляем нужный коэффициент: для ОЛ (тор) = 35, для ПЛ,ШЛ = 40, для П и Ш = 50.
Так как у нас ОЛ сердечник (тор), примем коэффициент равный 35.
К = 35/45 = 0.77 витка на 1 вольт.
Далее рассчитываем сколько нужно витков для первичной и вторичной обмоток.
Здесь у нас два пути расчета:
- если нам нужен трансформатор с единой первичной обмоткой, то есть мы не собираемся регулировать ток по первичной обмотке ступенями.
- если мы собираемся регулировать ток по первичной обмотке и нам нужно рассчитать ступени регулирования.
Регулировка ступенями по вторичной обмотке трансформатора экономически не выгодна, требует дорогостоящих коммутирующих элементов, также требует увеличение длины провода вторичной обмотки, тем самым утяжеляя конструкцию и поэтому здесь не рассматривается.
1. Рассчитаем количество витков для первичной и вторичной обмотки в варианте без регулирования по первичной обмотке ступенями.
Рассчитаем количество витков первичной обмотки по формуле:
W1 = U1*K
Где: W1 - количество витков первичной обмотки. U1 - напряжение первичной обмотки в вольтах. K - количество витков на вольт.
W1 = 220*0.77 = 170 витков.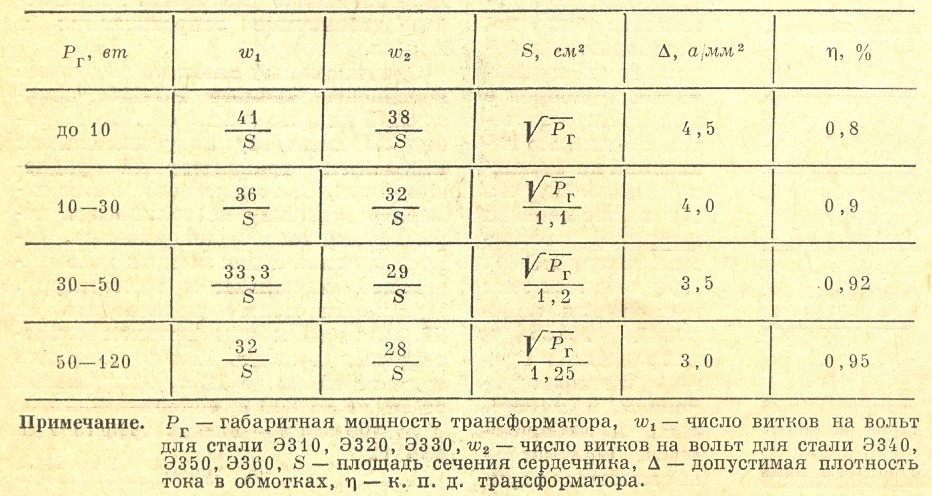
Далее..
Примем максимальное напряжение вторичной обмотки равным U2 = 35 вольт
Рассчитаем количество витков вторичной обмотки по формуле:
W2 = U2*K
Где: W2 - количество витков вторичной обмотки. U2 - напряжение вторичной обмотки в вольтах. K - количество витков на вольт.
W2=35*0.77=27 витков
Далее рассчитываем площадь сечения провода первичной и вторичной обмоток. Для этого нам нужно знать, какой максимальный ток течет в данной обмотке.
Для этого мы воспользуемся формулой:
Для первичной обмотки.
I первич_max = P габаритн/U первич
Где: I первич_max - максимальный ток первичной обмотки. P габаритн - габаритная мощность трансформатора. U первич - напряжение сети.
I первич_max = 6840/220 = 31 А
Для вторичной обмотки:
Сразу хочу сказать, что я не теоретик, но попытаюсь объяснить формирование величины сварочного тока в трансформаторе, как понимаю это я.
Напряжение дуги для сварки проволокой в среде углекислого газа равно:
Uд = 14+0.05*Iсв
Где: Uд - напряжение дуги. Iсв - ток сварки.
Выводим формулу тока вторички при конкретном напряжении дуги:
Iсв = (Uд — 14)/0.05
Далее рассчитаем для полуавтомата.
1. Принимаем напряжение дуги 25 вольт, получаем требуемую мощность трансформатора:
Iвторич = (25-14)/0.05 = 220 ампер
220*25 = 5500 вт.… Но у нас габаритная мощность трансформатора больше.
Считаем дальше..
2. Принимаем напряжение дуги равным 26 вольт, получаем требуемую мощность трансформатора:
Iвторич = (26-14)/0.05 = 240 ампер
240*26 = 6240 вт… Почти рядом.
Считаем дальше..
3. Принимаем напряжение дуги равным 27 вольт, получаем требуемую мощность трансформатора:
Iвторич = (27-14)/0.05 = 260 ампер.
260*27 = 7020вт. .. Требуемая габаритная мощность выше чем имеющаяся, это говорит о том, что при данном напряжении дуги не будет тока 260 ампер, так как не хватает габаритной мощности трансформатора.
.. Требуемая габаритная мощность выше чем имеющаяся, это говорит о том, что при данном напряжении дуги не будет тока 260 ампер, так как не хватает габаритной мощности трансформатора.
Из выше перечислительных расчетов, можно сделать вывод, что при напряжении дуги в 26 вольт обеспечивается максимальный ток в 240 ампер при данной габаритной мощности трансформатора и именно этот ток вторички мы примем за максимальный:
Iвторич max = 240 ампер.
Для расчета максимального сварочного тока для сварки электродом, рассчитываем так же, только по другой формуле..
Uд = 20+0.04*Iсв
Где: Uд - напряжение дуги. Iсв - ток сварки.
Выводим формулу тока вторички при конкретном напряжении дуги:
Iсв = (Uд — 20)/0.04 (считать не будем, я думаю понятно).
Далее…
Из справочных материалов нам известно, что плотность тока в меди равна 5 ампер на мм.кв, в алюминии 2 ампера на мм.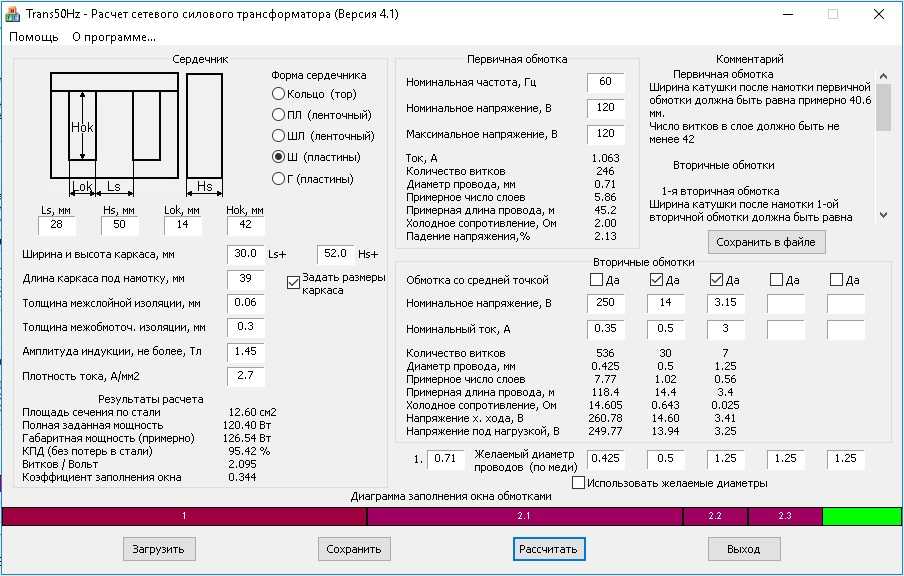 кв.
кв.
Исходя из этих данных можно рассчитать площадь сечения обмоток трансформатора.
Сечения проводов для продолжительной работы трансформатора ПН = 80% и выше:
Для меди:
S первич медь = 31/5 = 6.2 мм.кв
S вторичн медь = 250/5 = 50 мм.кв.
Для алюминия:
S первич алюмин = 31/2 = 16 мм.кв.
S вторичн алюмин = 250/2 = 125 мм.кв.
Итак мы имеем трансформатор с габаритной мощностью 6840 ватт. Сетевое напряжение 220 вольт. Напряжение вторичной обмотки 35 вольт.
Первичная обмотка содержит 170 витков провода площадью 6.2 мм.кв из меди или 16 мм.кв. из алюминия.
Вторичная обмотка содержит 27 витков провода площадью 50 мм.кв. из меди или 125 мм.кв. из алюминия.
Для ПН = 40% сечения первички и вторички можно уменьшить в 2 раза.
Для ПН = 20% сечения первички и вторички можно уменьшить в 3 раза.
Например ПН = 20% — это значит, что если взять за 100% 1 час работы трансформатора под нагрузкой, то 12 минут варим 48 минут отдыхаем, иначе трансформатор перегреется и перегорит (этот режим больше всего годится для не больших домашних дел). Я думаю тут понятно.
Я думаю тут понятно.
ПН — продолжительность нагрузки.
ПВ — продолжительность включения.
ПР — продолжительность работы.
Все эти термины одно и тоже, измеряются в процентах.
2. Рассчитаем количество витков для первичной и вторичной обмотки в варианте с регулированием ступенями по первичной обмотке.
Например, нам нужен трансформатор с регулированием сварочного тока 16 ступенями например используемого в этой схеме сварочного полуавтомата.
Выбираем номинальное напряжение вторичной обмотки.
Uномин = Uмакс — Uмакс*10/100
Где: Uномин - напряжение номинальной обмотки (на это напряжение будем рассчитывать вторичку). Uмакс - максимальное напряжение вторички для конкретного типа расчета.
Рассчитываем, Uмакс = 35 вольт
Uномин = 35 — 35*10/100 = 32 вольт.
Рассчитаем количество витков для вторичной обмотки номинальным напряжением 32 вольт, тип сердечника ОЛ (тор).
K = 35/S
К = 35/45 = 0.77 витка на 1 вольт.
W2 =U2*K = 32*0.77 = 25 витков
Теперь рассчитаем ступени первичной обмотки.
W1_ст = (220*W2)/Uст2
<strong>Где: Uст2 - нужное выходное напряжение на вторичной обмотке. W2 - количество витков вторички. W1_ст - количество витков первичной обмотки.</strong>
Как мы рассчитали ранее количество витков обмотки W2 = 25 витков.
Рассчитаем количество витков первички для напряжения на вторичке равное 35 вольт. W1_ст1 = (220*25)/35 = 157 витков.. Форсированный режим Далее рассчитываем на 34 вольт (шаг 1 вольт на вторичке) W1_ст2 = (220*25)/34 = 161 виток.. Форсированный режим Далее рассчитываем на 33 вольт W1_ст3 = (220*25)/33 = 166 витков.. Форсированный режим Далее рассчитываем на 32 вольт W1_ст4 = (220*25)/32 = 172 витка.. Номинальная обмотка Далее рассчитываем на 31 вольт W1_ст5 = (220*25)/31 = 177 витков.. Пассивный режим Далее рассчитываем на 30 вольт .. W1_ст6 = (220*25)/30 = 183 витка.. Пассивный режим Далее рассчитываем на 29 вольт W1_ст7 = (220*25)/29 = 190 витков.. Пассивный режим Далее рассчитываем на 28 вольт W1_ст8 = (220*25)/28 = 196 витков.. Пассивный режим Далее рассчитываем на 27 вольт W1_ст9 = (220*25)/27 = 204 витка.. Пассивный режим Далее рассчитываем на 26 вольт W1_ст10 = (220*25)/26 = 211 витков.. Пассивный режим Далее рассчитываем на 25 вольт W1_ст11 = (220*25)/25 = 220 витков.. Пассивный режим Далее рассчитываем на 24 вольт W1_ст12 = (220*25)/24 = 229 витков.. Пассивный режим Далее рассчитываем на 23 вольт W1_ст13 = (220*25)/23 = 239 витков.. Пассивный режим Далее рассчитываем на 22 вольт W1_ст14 = (220*25)/22 = 250 витков.. Пассивный режим Далее рассчитываем на 21 вольт W1_ст15 = (220*25)/21 = 261 виток.. Пассивный режим И последняя ступень на 20 вольт W1_ст16 = (220*25)/20 = 275 витков.. Пассивный режим
 .
W1_ст6 = (220*25)/30 = 183 витка.. Пассивный режим
Далее рассчитываем на 29 вольт
W1_ст7 = (220*25)/29 = 190 витков.. Пассивный режим
Далее рассчитываем на 28 вольт
W1_ст8 = (220*25)/28 = 196 витков.. Пассивный режим
Далее рассчитываем на 27 вольт
W1_ст9 = (220*25)/27 = 204 витка.. Пассивный режим
Далее рассчитываем на 26 вольт
W1_ст10 = (220*25)/26 = 211 витков.. Пассивный режим
Далее рассчитываем на 25 вольт
W1_ст11 = (220*25)/25 = 220 витков.. Пассивный режим
Далее рассчитываем на 24 вольт
W1_ст12 = (220*25)/24 = 229 витков.. Пассивный режим
Далее рассчитываем на 23 вольт
W1_ст13 = (220*25)/23 = 239 витков.. Пассивный режим
Далее рассчитываем на 22 вольт
W1_ст14 = (220*25)/22 = 250 витков.. Пассивный режим
Далее рассчитываем на 21 вольт
W1_ст15 = (220*25)/21 = 261 виток.. Пассивный режим
И последняя ступень на 20 вольт
W1_ст16 = (220*25)/20 = 275 витков.. Пассивный режим
.
W1_ст6 = (220*25)/30 = 183 витка.. Пассивный режим
Далее рассчитываем на 29 вольт
W1_ст7 = (220*25)/29 = 190 витков.. Пассивный режим
Далее рассчитываем на 28 вольт
W1_ст8 = (220*25)/28 = 196 витков.. Пассивный режим
Далее рассчитываем на 27 вольт
W1_ст9 = (220*25)/27 = 204 витка.. Пассивный режим
Далее рассчитываем на 26 вольт
W1_ст10 = (220*25)/26 = 211 витков.. Пассивный режим
Далее рассчитываем на 25 вольт
W1_ст11 = (220*25)/25 = 220 витков.. Пассивный режим
Далее рассчитываем на 24 вольт
W1_ст12 = (220*25)/24 = 229 витков.. Пассивный режим
Далее рассчитываем на 23 вольт
W1_ст13 = (220*25)/23 = 239 витков.. Пассивный режим
Далее рассчитываем на 22 вольт
W1_ст14 = (220*25)/22 = 250 витков.. Пассивный режим
Далее рассчитываем на 21 вольт
W1_ст15 = (220*25)/21 = 261 виток.. Пассивный режим
И последняя ступень на 20 вольт
W1_ст16 = (220*25)/20 = 275 витков.. Пассивный режимМотаем первичную обмотку трансформатора до 157 витка, делаем отвод, он будет соответствовать 35 вольтам на вторичке.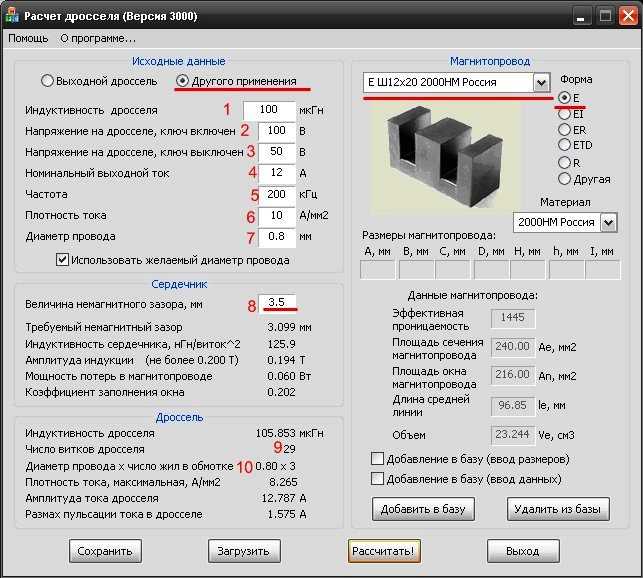
Далее мотаем 4 витка до 161 витка и делаем отвод, он будет соответствовать напряжению на вторичке 34 вольт.
Далее мотаем 5 витков и делаем отвод на 166 витке, он будет соответствовать напряжению на вторичке 33 вольт и т.д. согласно выше приведенному расчету.
Заканчиваем намотку первичной обмотки на 275 витке, он будет соответствовать напряжению на вторичке 20 вольт.
В итоге у нас получился трансформатор габаритной мощностью в 6840 ватт, первичной обмоткой с 16 ступенями регулирования.
Сечение обмоток такие же, как в первом варианте расчета.
На данном этапе мы заканчиваем расчет трансформатора.
Как сделать трансформатор смотрите здесь Делаем тороидальный сварочный трансформатор
Таким образом было рассчитано много трансформаторов и они прекрасно работают в сварочных полуавтоматах и сварочных аппаратах.
Не нужно бояться форсированного режима работы трансформатора (это такой режим, когда к обмотке трансформатора рассчитанного например на 190 вольт приложено напряжение 220 вольт), трансформатор прекрасно работает в таком режиме. Имея маломощный трансформатор, можно вытянуть из него все возможности используя форсированный режим для комфортного процесса сварки с помощью сварочного полуавтомата.
Имея маломощный трансформатор, можно вытянуть из него все возможности используя форсированный режим для комфортного процесса сварки с помощью сварочного полуавтомата.
Ссылка для статьи на сайте Расчет трансформатора для сварочного полуавтомата, сварочного аппарата.
Ответ на комментарий.
Как наматывать на П-образный сердечник:
Первичная обмотка.
Вариант 1. Мотаем две одинаковые обмотки (клоны) в одну сторону и соединяем их начала. Концы этих обмоток используем для подключения к сети 220 вольт.
Вариант 2. Мотаем две одинаковые обмотки (клоны) в одну сторону, делаем отводы. Замыкая эти отводы, регулируем сварочный ток. Начало этих обмоток используем для подключения к сети 220 вольт.
Вторичная обмотка.
Мотаем две одинаковые обмотки в одну сторону и соединяем их концы. Начала этих обмоток используем для сварки.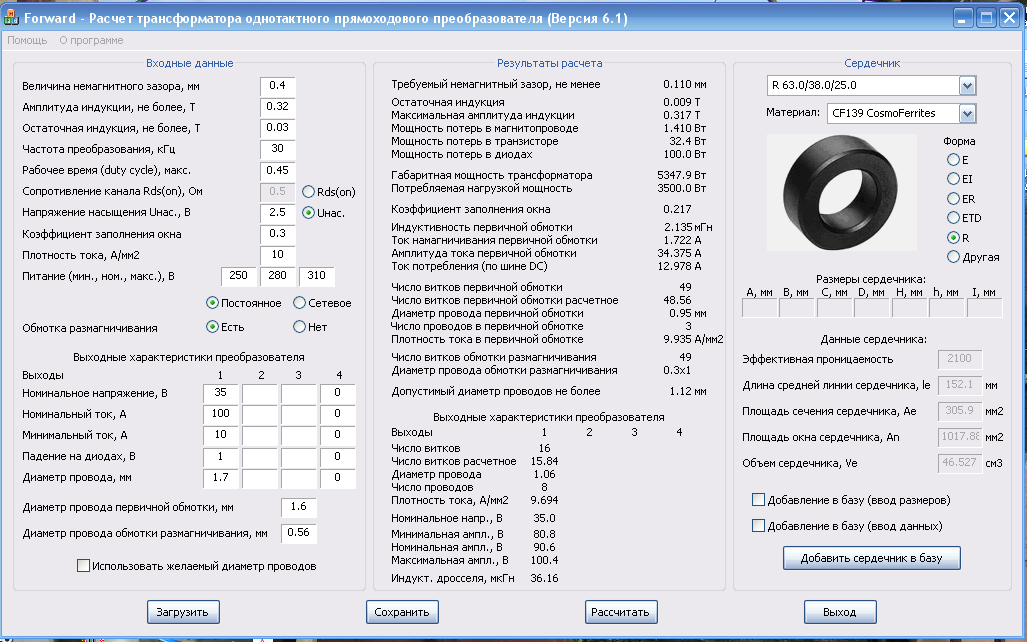
Расчет площади сердечника и площади окна сердечника Sc и So.
По этим формулам, можно рассчитать требуемые величины.
Если возникнут вопросы, задавайте их в комментариях.
Автор замысловатых расчетов: Admin Svapka.Ru
Понимание преобразователя зрения и подсчет его параметров | Андрей-Кристиан Рад | Analytics Vidhya
Photo by Simon Migaj на UnsplashВ этом посте я поделюсь своим пониманием архитектуры Vision Transformer. Все рисунки в этом посте являются оригинальным контентом, основанным на знаниях из статьи и других учебных пособий, на которые будут ссылаться при необходимости.
Архитектуры-трансформеры стали крупным прорывом в задачах обработки естественного языка (NLP) с тех пор, как они были предложены в 2016 году. различные задачи, включая языковое моделирование, обобщение текста и ответы на вопросы.
Цель состояла в том, чтобы доказать, что рекуррентные нейронные сети могут быть полностью заменены, а решения могут быть разработаны с использованием только механизмов внимания — отсюда и каламбур в названии статьи Transformer. Подробное описание того, как работает оригинальная архитектура Transformer, выходит за рамки этой статьи, но есть множество надежных руководств и видео, которые объясняют, как это работает.
Подробное описание того, как работает оригинальная архитектура Transformer, выходит за рамки этой статьи, но есть множество надежных руководств и видео, которые объясняют, как это работает.
В центре внимания этой статьи — обзор архитектуры Vision Transformer (ViT), предложенной в новой статье для Google, представленной для рассмотрения на ICLR 2021. Хотя были предыдущие попытки использовать механизмы внимания для задач компьютерного зрения (эта , это или это), ViT — наиболее перспективная архитектура, как с точки зрения масштабируемости, так и с точки зрения эффективности.
Vision Trnasformer ArchitecutreАрхитектура содержит 3 основных компонента.
- Встраивание патча.
- Извлечение признаков с помощью многоуровневых преобразователей.
- Классификация зав.
Каждый компонент будет подробно описан в следующих параграфах с упором на преобразования и обучаемые параметры. Первая размерность некоторых тензоров равна b , что представляет собой размер пакета, но для простоты в комментариях это и операции вещания будут проигнорированы.
На первом этапе входное изображение формы (высота, ширина, каналы) встраивается в вектор признаков формы (n+1, d) , , следуя последовательности преобразований. Это соответствует уравнению (1) из статьи:
- Изображение разбивается на n квадратных участков формы (p, p, c) , , где p — предварительно определенный параметр , в растровом порядке (слева направо, сверху вниз).
- Патчи выравниваются, в результате чего получается n линейных векторов формы (1, p²*c) .
- Сглаженные участки умножаются на обучаемый тензор вложения формы (p²*c, d) , который учится линейно проецировать каждый плоский участок на размерность d . Этот размер d является постоянным в архитектуре и используется в большинстве компонентов. Результат н закладные вставки формы (1, г).
- Обучаемый маркер [cls] формы (1, d) добавляется к последовательности вложений патчей. Идея этого токена взята из статьи BERT, где только последнее представление, соответствующее этому токену (выход преобразователя L), проходит через слои классификации. Интуитивно это представляет совокупность представлений патчей.
- A обучаемый тензор позиционного вложения, Eₚₒₛ , той же формы, (n+1, d) , добавляется к объединенной последовательности проекций. Этот тензор изучает одномерную позиционную информацию для каждого из участков, чтобы добавить пространственное представление каждого участка в последовательности.
 Результат н закладные вставки формы (1, г).
Результат н закладные вставки формы (1, г). Результат, z₀, является первым входом в энкодеры каскадного преобразователя. Кодировщики со стеком L представляют собой второй компонент архитектуры. Каждый преобразователь принимает в качестве входных данных функции, представленные в виде (n+1, d) тензор и дает результат той же размерности.
Каждый преобразователь принимает в качестве входных данных функции, представленные в виде (n+1, d) тензор и дает результат той же размерности.
На втором этапе сеть изучает более абстрактные функции из встроенных патчей, используя стек из L кодировщиков-трансформеров. Это соответствует уравнениям (2) и (3) из статьи.
Компонент кодировщика содержит механизм многоголового внимания (MHA) и двухуровневый MLP с нормализацией уровней и остаточными соединениями между ними.
Нормализация слоя помогает стабилизировать динамику скрытого состояния и сократить время обучения. Это делается путем масштабирования со средним значением и стандартным отклонением для каждого обучающего примера (в отличие от пакетной нормы, где это делается для каждой функции). Полученные функции умножаются на коэффициент масштабирования и добавляются к коэффициенту сдвига, которые можно изучить во время обучения.
Остаточные соединения предлагают градиентам альтернативные пути, чтобы решить проблему исчезновения градиентов в очень глубоких архитектурах.
Обучаемые грузы в этом компоненте находятся внутри механизма MHA и грузиков MLP. Поскольку MLP имеет 2 слоя (скрытый и выход), будет две матрицы веса:
- Wₕ формы (D, Dₘₗₚ)
- Wₒ из формы (Dₘₗₚ, D)
Шаг многоголового внимания (MHA), включенный в каждый из L-образных трансформаторов, соответствует уравнениям (5), (6), (7) и (8) из приложения к статье.
Скрытое состояние от предыдущего кодировщика разбивается на K головок, в результате чего получаются K тензоров признаков формы (n, dₕ) . Из интуиции внимания с несколькими головками несколько головок позволяют механизму учиться на разных аспектах абстрактного представления.
Каждая умножается на 3 обучаемые матрицы Qi, Ki, Vi формы (дₕ, дₕ). Это эквивалентно уравнению 5, так как в U= (d, 3dₕ) имеется ровно 3 матрицы для каждой головы, каждая из которых имеет форму (dₕ, dₕ) .
Ци, Ки и Ви представляют собой проекцию входа в 3 подпространства. Мы можем думать о каждой строке в Q как об изученной проекции интересующего нас участка, а о строках в K как о других участках, с которыми мы сравниваем Q. V и K научились выражать важность или вес для функций в V, чтобы вычислить окончательное «внимание».
После этого для каждой головы масштабированный тензор скалярного произведения (A) вычисляется как softmax произведения между матрицами Ki и Qi , нормализованного квадратным корнем из размера головы. i--я строка в этой матрице представляет собой функцию распределения вероятностей внимания для запроса i , означающую, на ключи каких других патчей наиболее похож запрос патча i .
Самостоятельное внимание является продуктом между A и v , который имеет форму (n+1, dₕ). Элемент в строке i и столбце j представляет собой средневзвешенное значение признака j по PDF в строке i в A. (n+1, d) тензор, который затем проходит через один линейный слой, эффективно умножая его на (d, d) обучаемый тензор. Этот линейный слой очень важен, так как он позволяет изучать признаки как агрегаты со всех головок.
(n+1, d) тензор, который затем проходит через один линейный слой, эффективно умножая его на (d, d) обучаемый тензор. Этот линейный слой очень важен, так как он позволяет изучать признаки как агрегаты со всех головок.
Как указывалось ранее, в заголовке классификации используется только последнее представление токена [cls] . Для предобучения используется 2-слойный МЛП, поэтому есть две весовые матрицы — Wₕ формы (d, dₘₗₚ) и Wₒ формы (dₘₗₚ, d) . Для тонкой настройки используется один линейный слой, поэтому имеется только один тензор формы 9.0005 (д, н_клс) . В каждом случае конечным выходом сети является вектор формы (1, n_cls) , , содержащий вероятности, связанные с каждым из
0_02cls классов. Параметры Vision Transformer [1]
Параметры Vision Transformer [1]Возьмем архитектуру ViT-Base и посчитаем количество параметров. обучаемый тензор в архитектуре.
На этапе внедрения исправления две матрицы внедрения учитывают 786,432 параметра.
p²*c*d + (n+1)*d = 256*3*768 + 256*768 = 786,432
В стеке энкодера всего 84,943,656 параметров.
L*(k*d*3*dₕ + d*d + d* dₘₗₚ + dₘₗₚ*d )
= 12*(12*768*3*64 + 768*768 + 2*768*3072)
= 12*(1.769.472 + 589.824 + 4.718.592)
= 12*589.824(3+1+8)
= 12*589.824*12
= 84.934.656
экземпляр), есть и другие параметры 768.000.
d*ncls = 768 * 1000 = 768.000
Складывая их, мы получаем около 86M, как указано в документе.
Архитектура ViT достигла самой современной производительности в ImageNet при предварительном обучении на JFT-300M. Однако авторы отметили, что производительность резко снижается при использовании небольших наборов данных для предварительного обучения и что более крупные модели лучше подходят для больших наборов данных. Эта проблема, скорее всего, возникает из-за отсутствия индуктивного смещения в трансформаторных сетях. Они способны обрабатывать любую последовательность, не зная ее отношения порядка.
Эта проблема, скорее всего, возникает из-за отсутствия индуктивного смещения в трансформаторных сетях. Они способны обрабатывать любую последовательность, не зная ее отношения порядка.
Мне очень помогла возможность визуализировать преобразования и поток в этой архитектуре. Надеюсь, в вашем случае так же. Ваше здоровье!
[1] А. Достовицкий и др. al., Изображение стоит 16×16 слов: преобразователи для распознавания изображений в масштабе (2020 г.) ICLR 2021 (на рассмотрении)
[2] A. Vaswani et. al., Attention is All You Need (2017), Proceedings of NIPS2017
[3] J. Devlin et. al., BERT: Pre-training of deep двунаправленные преобразователи для понимания языка (2018)
Трансформеры с визуальным объяснением (часть 2): как это работает, шаг за шагом | by Ketan Doshi
СЕРИЯ INTUITIVE TRANSFORMERS NLP
Нежное руководство по трансформеру под капотом и его комплексной работе.
 Фото Джошуа Сортино на Unsplash
Фото Джошуа Сортино на UnsplashЭто вторая статья из моей серии о Трансформерах. В первой статье мы узнали о функциональности Трансформеров, о том, как они используются, об их высокоуровневой архитектуре и их преимуществах.
В этой статье мы теперь можем заглянуть под капот и подробно изучить, как они работают. Мы увидим, как данные проходят через систему с их реальными матричными представлениями и формами, и поймем вычисления, выполняемые на каждом этапе.
Вот краткий обзор предыдущей и следующей статей этой серии. Моя цель будет заключаться в том, чтобы понять не только то, как что-то работает, но и почему это работает именно так.
- Обзор функций (Как используются трансформеры и почему они лучше, чем RNN. Компоненты архитектуры и поведение во время обучения и вывода)
- Как это работает — эта статья (Внутреннее сквозное функционирование. Как данные потоки и выполняемые вычисления, включая матричные представления)
- Multi-head Attention (внутренняя работа модуля Attention в Transformer)
- Почему Attention повышает производительность (Не только то, что делает Внимание, но и почему оно работает так хорошо. Как Внимание фиксирует отношения между словами в предложении)
 Как Внимание фиксирует отношения между словами в предложении)
Как Внимание фиксирует отношения между словами в предложении) И если вы интересуетесь приложениями НЛП в целом, у меня есть несколько других статей, которые могут вам понравиться .
- Поиск луча (Алгоритм, обычно используемый в приложениях преобразования речи в текст и НЛП для улучшения прогнозов)
- Оценка по Блю ( Оценка по Блю и Частота ошибок в словах — две важные метрики для моделей НЛП )
Как мы видели в части 1, основными компонентами архитектуры являются:
(Изображение автора)Входные данные для кодировщика и декодера, которые содержат:
- Уровень внедрения
- Уровень кодирования положения
Стек энкодеров содержит несколько энкодеров. Каждый кодировщик содержит:
- Многоголовочный уровень внимания
- Уровень прямой связи
Стек декодера содержит несколько декодеров. Каждый декодер содержит:
- Два слоя Multi-Head Attention
- Слой прямой связи
Выход (вверху справа) — генерирует окончательный результат и содержит:
- Линейный слой
- Слой Softmax.
Чтобы понять, что делает каждый компонент, давайте рассмотрим работу Transformer, пока мы обучаем его решать задачу перевода. Мы будем использовать один образец наших обучающих данных, который состоит из входной последовательности («Добро пожаловать» на английском языке) и целевой последовательности («De nada» на испанском языке).
Как и в любой модели НЛП, Трансформеру нужны две вещи о каждом слове — значение слова и его положение в последовательности.
- Слой внедрения кодирует значение слова.
- Слой Position Encoding представляет позицию слова.
Трансформатор объединяет эти две кодировки, добавляя их.
Embedding
Transformer имеет два слоя Embedded. Входная последовательность подается на первый слой внедрения, известный как входное внедрение.
(Изображение автора) Целевая последовательность подается на второй слой внедрения после смещения целей вправо на одну позицию и вставки токена Start в первую позицию. Обратите внимание, что во время вывода у нас нет целевой последовательности, и мы передаем выходную последовательность этому второму слою в цикле, как мы узнали в части 1. Вот почему это называется выходным внедрением.
Обратите внимание, что во время вывода у нас нет целевой последовательности, и мы передаем выходную последовательность этому второму слою в цикле, как мы узнали в части 1. Вот почему это называется выходным внедрением.
Текстовая последовательность сопоставляется с числовыми идентификаторами слов с использованием нашего словаря. Затем слой внедрения сопоставляет каждое входное слово вектору внедрения, который является более богатым представлением значения этого слова.
(Изображение автора)Кодирование позиции
Поскольку RNN реализует цикл, в котором каждое слово вводится последовательно, она неявно знает позицию каждого слова.
Однако Transformers не используют RNN, и все слова в последовательности вводятся параллельно. Это ее главное преимущество перед архитектурой RNN, но это означает, что информация о местоположении теряется и ее нужно добавлять обратно отдельно.
Так же, как и два слоя Embedded, существует два слоя Position Encoding. Кодирование положения вычисляется независимо от входной последовательности. Это фиксированные значения, которые зависят только от максимальной длины последовательности. Например,
Это фиксированные значения, которые зависят только от максимальной длины последовательности. Например,
- первый элемент представляет собой постоянный код, указывающий на первую позицию
- второй элемент представляет собой постоянный код, указывающий на вторую позицию,
- и так далее.
Эти константы вычисляются по приведенной ниже формуле, где
- pos — позиция слова в последовательности
- d_model — длина вектора кодирования (такого же, как вектор встраивания) и
- i — значение индекса в этом векторе.
Другими словами, он чередует синусоидальную кривую и кривую cos со значениями синуса для всех четных индексов и значениями cos для всех нечетных индексов. Например, если мы кодируем последовательность из 40 слов, мы можем увидеть ниже значения кодирования для нескольких комбинаций (позиция слова, кодирование_индекс).
(Изображение автора) Синяя кривая показывает кодировку 0-го индекса для всех 40 позиций слов, а оранжевая кривая показывает кодировку 1-го индекса для всех 40 позиций слов. Аналогичные кривые будут и для остальных значений индекса.
Аналогичные кривые будут и для остальных значений индекса.
Как мы знаем, модели глубокого обучения обрабатывают сразу несколько обучающих выборок. Уровни Embedding и Position Encoding работают с матрицами, представляющими набор образцов последовательности. Встраивание принимает матрицу идентификаторов слов в форме (выборки, длина последовательности). Он кодирует каждый идентификатор слова в вектор слов, длина которого является размером встраивания, в результате чего получается выходная матрица формы (выборки, длина последовательности, размер встраивания). Кодировка положения использует размер кодирования, равный размеру внедрения. Таким образом, он создает матрицу аналогичной формы, которую можно добавить к матрице встраивания.
(Изображение автора) Форма (выборки, длина последовательности, размер встраивания), созданная слоями Embedding и Position Encoding, сохраняется на всем протяжении преобразователя, поскольку данные проходят через стеки кодировщика и декодера, пока они не будут изменены окончательным Выходные слои.
Это дает представление о размерах трехмерной матрицы в Transformer. Однако, чтобы упростить визуализацию, с этого момента мы будем отбрасывать первое измерение (для образцов) и использовать 2D-представление для одного образца.
(Изображение автора)Входное встраивание отправляет свои выходные данные в кодировщик. Точно так же выходное вложение подается в декодер.
Стеки кодеров и декодеров состоят из нескольких (обычно шести) кодеров и декодеров соответственно, соединенных последовательно.
(Изображение автора)Первый кодировщик в стеке получает входные данные от кодирования встраивания и положения. Другие кодировщики в стеке получают входные данные от предыдущего кодировщика.
Кодировщик передает свои входные данные на уровень многоголового внутреннего внимания. Выходные данные собственного внимания передаются на уровень прямой связи, который затем отправляет свои выходные данные вверх к следующему кодировщику.
(Изображение автора) Как подуровни самообслуживания, так и подуровни прямой связи имеют остаточное пропущенное соединение вокруг них, за которым следует нормализация уровня.
Выход последнего кодировщика подается в каждый декодер в стеке декодера, как описано ниже.
Структура декодера очень похожа на кодировщик, но с некоторыми отличиями.
Как и кодировщик, первый декодер в стеке получает входные данные от встраивания вывода и кодирования положения. Другие декодеры в стеке получают входные данные от предыдущего декодера.
Декодер передает свои входные данные на уровень многоголового внутреннего внимания. Это работает немного иначе, чем в Encoder. Разрешается посещать только более ранние позиции в последовательности. Это делается путем маскировки будущих позиций, о чем мы вскоре поговорим.
(Изображение автора) В отличие от кодировщика, декодер имеет второй уровень внимания с несколькими головками, известный как уровень внимания кодировщик-декодер. Слой внимания кодировщик-декодер работает так же, как самовнимание, за исключением того, что он объединяет два источника входных данных — слой самоконтроля под ним, а также выходные данные стека кодировщика.
Выходные данные собственного внимания передаются на уровень прямой связи, который затем отправляет свои выходные данные вверх к следующему декодеру.
Каждый из этих подуровней, Самостоятельное внимание, Внимание кодировщика-декодера и Прямая связь, имеют остаточное пропускное соединение вокруг них, за которым следует нормализация уровня.
В части 1 мы говорили о том, почему внимание так важно при обработке последовательностей. В Трансформере Внимание используется в трех местах:
- Самостоятельное внимание в Энкодере — входная последовательность обращает внимание на себя
- Самостоятельное внимание в Декодере — целевая последовательность обращает внимание на себя
- Кодировщик-Декодер-внимание в Декодере — целевая последовательность обращает внимание на входную последовательность
Слой Внимание принимает входные данные в виде трех параметры, известные как запрос, ключ и значение.
- В Самостоятельном внимании кодировщика ввод кодировщика передается всем трем параметрам: запросу, ключу и значению.
- В режиме самоконтроля декодера ввод декодера передается всем трем параметрам: запросу, ключу и значению.
- Вниманию Encoder-Decoder декодера вывод последнего Encoder в стеке передается параметрам Value и Key. Выходные данные модуля «Самовнимание» (и «Норма уровня»), расположенного ниже, передаются в параметр «Запрос».
Преобразователь называет каждый процессор внимания головой внимания и повторяет это несколько раз параллельно. Это известно как многоголовое внимание. Это дает его Вниманию большую способность различать, комбинируя несколько подобных расчетов Внимания.
(Изображение автора)Каждый запрос, ключ и значение проходят через отдельные линейные слои, каждый со своим собственным весом, в результате чего получаются три результата, называемые Q, K и V соответственно. Затем они объединяются вместе с использованием формулы внимания, как показано ниже, для получения оценки внимания.
(Изображение автора) Здесь важно понимать, что значения Q, K и V несут закодированное представление каждого слова в последовательности.![]() Затем расчеты внимания объединяют каждое слово с каждым другим словом в последовательности, так что оценка внимания кодирует оценку для каждого слова в последовательности.
Затем расчеты внимания объединяют каждое слово с каждым другим словом в последовательности, так что оценка внимания кодирует оценку для каждого слова в последовательности.
Недавно при обсуждении декодера мы вкратце упомянули маскировку. Маска также показана на диаграммах внимания выше. Посмотрим, как это работает.
При вычислении показателя внимания модуль «Внимание» выполняет этап маскирования. Маскирование служит двум целям:
В кодировщике-внимании к себе и в кодировщике-декодере-внимании: маскирование служит для нулевого внимания к выводам, где есть заполнение во входных предложениях, чтобы гарантировать, что заполнение не способствует самому себе. -внимание. (Примечание: поскольку входные последовательности могут иметь разную длину, они расширяются с помощью токенов-заполнителей, как и в большинстве приложений НЛП, так что векторы фиксированной длины могут быть введены в Преобразователь.)
(Изображение автора) Аналогично для кодировщика-декодера внимание.
В декодере Самостоятельное внимание: маскирование служит для предотвращения «заглядывания» декодера в остальную часть целевого предложения при прогнозировании следующего слова.
Декодер обрабатывает слова в исходной последовательности и использует их для предсказания слов в целевой последовательности. Во время обучения это делается с помощью форсировки учителя, когда полная целевая последовательность подается в качестве входных данных декодера. Следовательно, при прогнозировании слова в определенной позиции декодер имеет в своем распоряжении целевые слова, предшествующие этому слову, а также целевые слова, следующие за этим словом. Это позволяет декодеру «обмануть», используя целевые слова из будущих «шагов времени».
Например, при прогнозировании « Word 3» декодер должен ссылаться только на первые 3 входных слова из цели, но не на четвертое слово « Ketan» .
(Изображение автора) Таким образом, декодер маскирует входные слова, которые появляются позже в последовательности.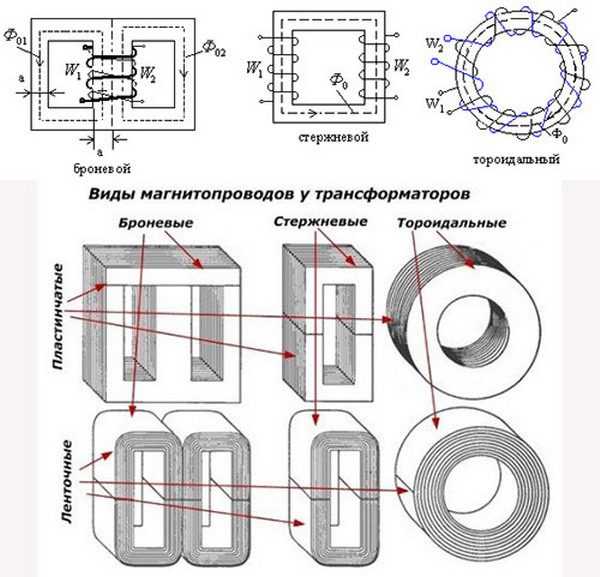
При расчете оценки внимания (см. рисунок выше, показывающий расчеты) маскирование применяется к числителю непосредственно перед Softmax. Замаскированные элементы (белые квадраты) установлены на отрицательную бесконечность, так что Softmax превращает эти значения в ноль.
Последний декодер в стеке передает свой вывод компоненту вывода, который преобразует его в окончательное выходное предложение.
Линейный слой проецирует вектор декодера в Word Scores со значением оценки для каждого уникального слова в целевом словаре в каждой позиции в предложении. Например, если наше окончательное выходное предложение состоит из 7 слов, а целевой словарь испанского языка содержит 10 000 уникальных слов, мы генерируем 10 000 значений баллов для каждого из этих 7 слов. Значения баллов указывают на вероятность появления каждого слова в словарном запасе в этой позиции предложения.
Затем слой Softmax преобразует эти оценки в вероятности (которые в сумме дают 1,0). В каждой позиции мы находим индекс слова с наибольшей вероятностью, а затем сопоставляем этот индекс с соответствующим словом в словаре. Затем эти слова образуют выходную последовательность преобразователя.
В каждой позиции мы находим индекс слова с наибольшей вероятностью, а затем сопоставляем этот индекс с соответствующим словом в словаре. Затем эти слова образуют выходную последовательность преобразователя.
Во время обучения мы используем функцию потерь, такую как кросс-энтропийная потеря, чтобы сравнить сгенерированное выходное распределение вероятностей с целевой последовательностью. Распределение вероятностей дает вероятность появления каждого слова в этой позиции.
(Изображение автора)Предположим, наш целевой словарь содержит всего четыре слова. Наша цель — создать распределение вероятностей, соответствующее нашей ожидаемой целевой последовательности «De nada END».
Это означает, что распределение вероятностей для первой позиции слова должно иметь вероятность 1 для «De» с вероятностью для всех других слов в словаре, равной 0. Точно так же, «nada» и «END» должны иметь вероятность 1 для второй и третьей позиции слова соответственно.
Как обычно, потери используются для вычисления градиентов для обучения Преобразователя с помощью обратного распространения ошибки.