
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом / Хабр
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
Вот так, например:
01100010 01101001 01110100 01110011
b i t s
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
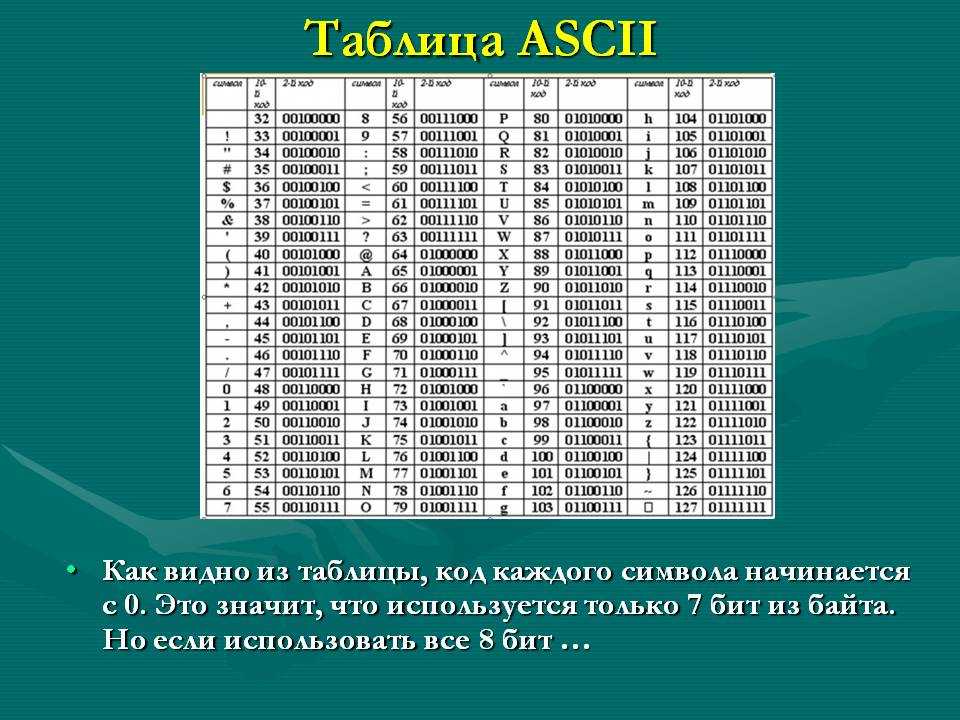
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие.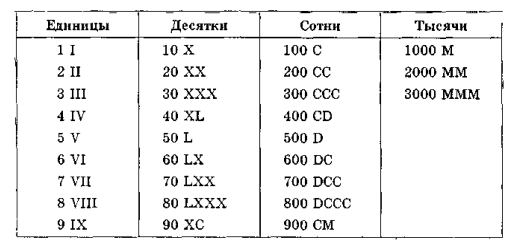 В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский.
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер.
Итак, и сколько же байт использует Unicode для кодирования?
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 0101101110000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню.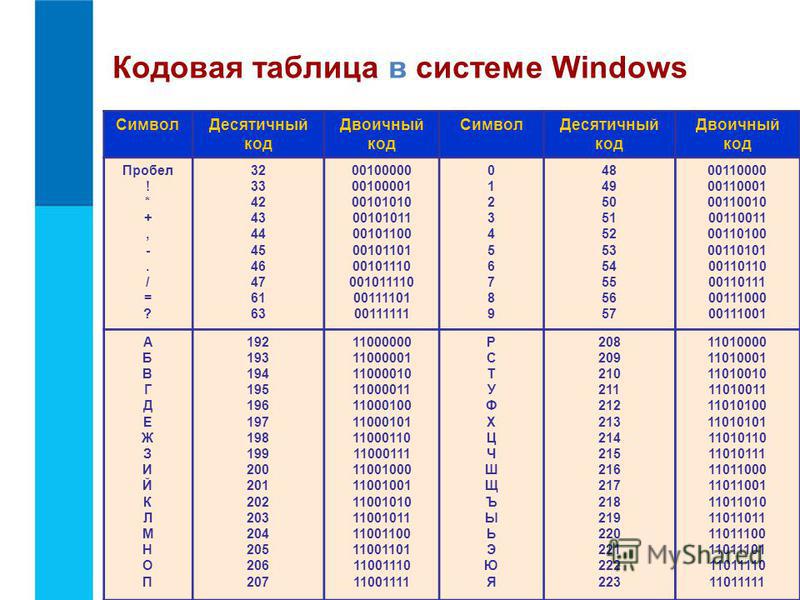 Иные программы тоже имеют аналогичные пункты.
Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
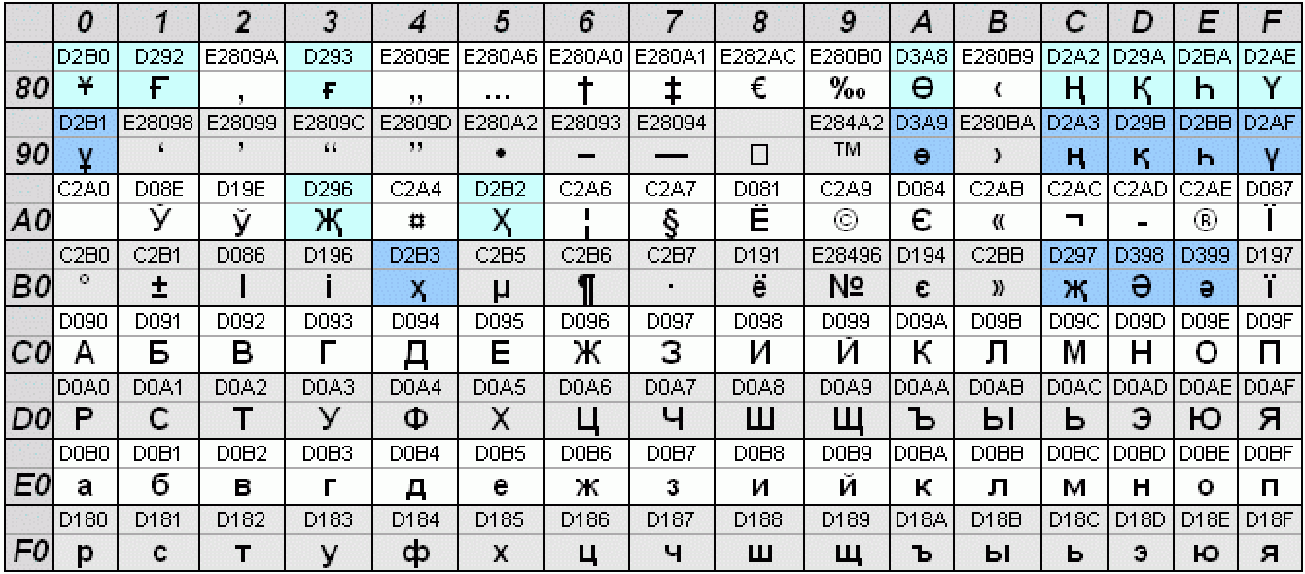
Перевод чисел из одной системы счисления в другую
Наиболее часто встречающиеся системы счисления – это двоичная, шестнадцатеричная и десятичная. Есть различные способы перевода чисел из одной системы счисления в другую на конкретных примерах.
Бит (англ. bit — немного) — единица измерения информации.
Байт (англ. byte) — единица измерения количества информации, по умолчанию байт считается равным восьми битам.
1Байт = 8Бит Байт | обозначение | Единица измерения |
1000 | kB | 1 килобайт |
1000000 | MB | 1 мегабайт |
1000000000 | GB | 1 гигабайт |
1000000000000 | TB | 1 терабайт |
1000000000000000 | PB | 1 петабайт |
1000000000000000000 | EB | 1 эксабайт |
100000000000000000000 | ZB | 1 зеттабайт |
1000000000000000000000000 | YB | 1 йоттабайт |
В
основном, в зависимости от объема,
пользуются первыми тремя единицами
измерения: Калобайты, Мегабайты,
Гигабайты.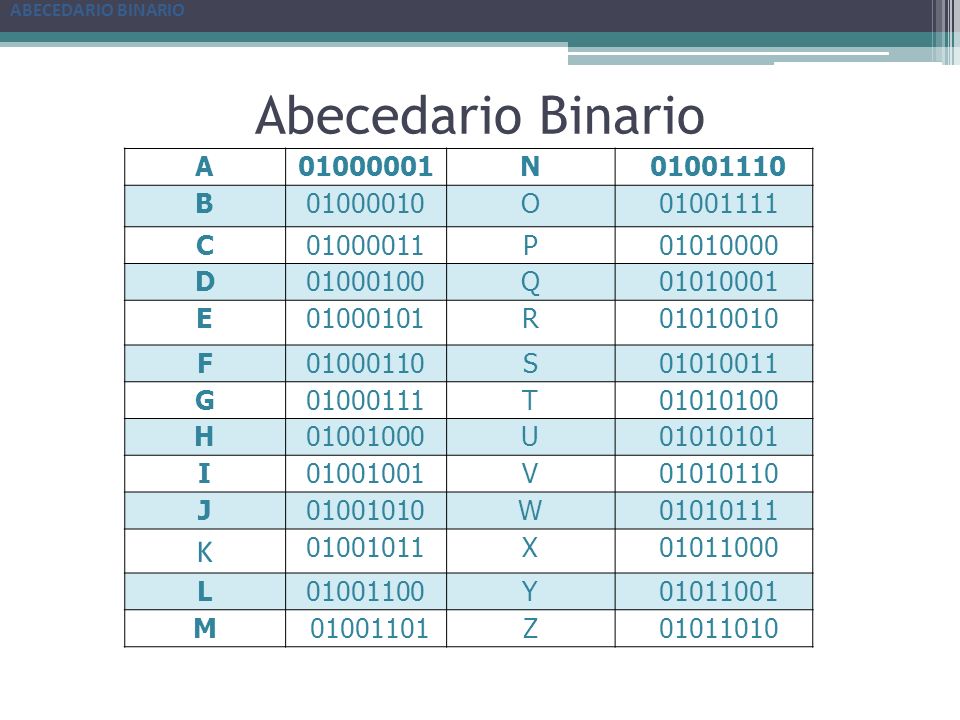
Таблица кодов — это табличка, в ячейки которой вписаны коды, то есть комбинации из цифр и букв латинского алфавита. Координаты ячеек определяются так же, как координаты клеток на шахматной доске (например, В3). Каждая таблица уникальна, комбинации кодов не повторяются.
Двоичное кодирование
В какой бы форме не представлялась подлежащая обработке информация, она должна быть переведена компьютером на язык, доступный для автоматической обработки. Язык компьютера – это язык чисел, причем не обычных (десятичных), а двоичных, алфавит которых состоит всего лишь из двух цифр – 0 и
1. Двоичная система наиболее проста и удобна для обработки на ЭВМ, т. к. компьютер – электрическая машина и работает с электрическими сигналами: есть сигнал – включено, нет сигнала – выключено.
В
современной вычислительной технике
информация как раз и кодируется с помощью
сигналов двух видов: включено или
выключено. На
этом простом принципе и основана работа
ЭВМ. Любая информация в компьютере может
быть представлена в виде последовательности
двоичных символов – бит.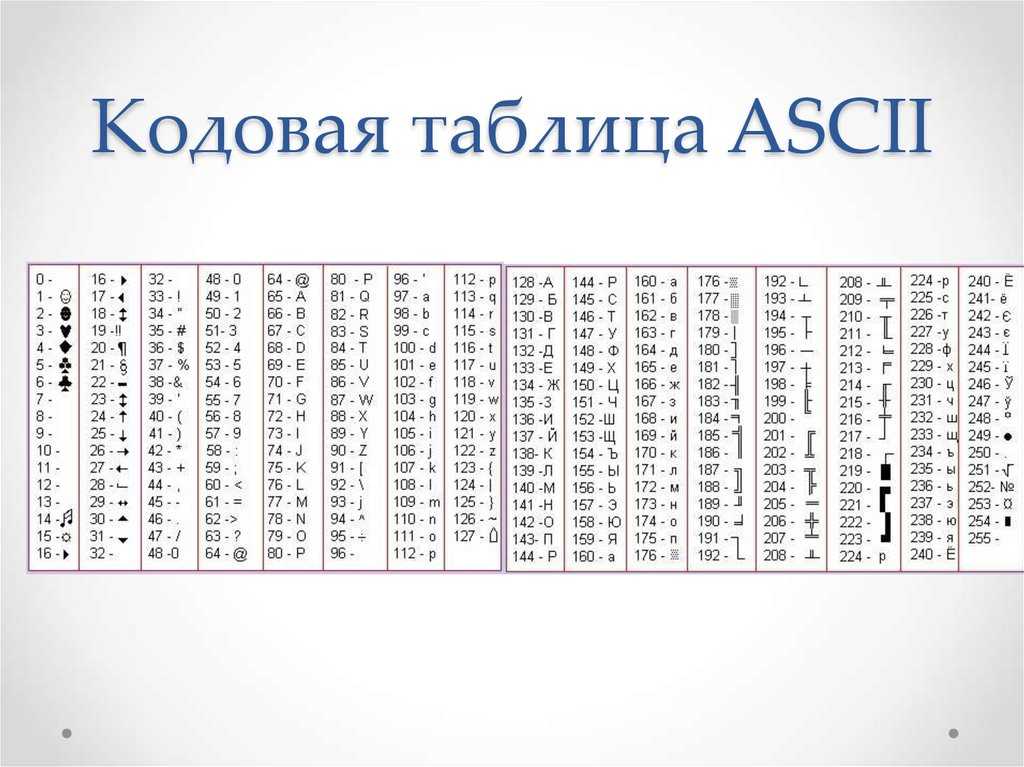
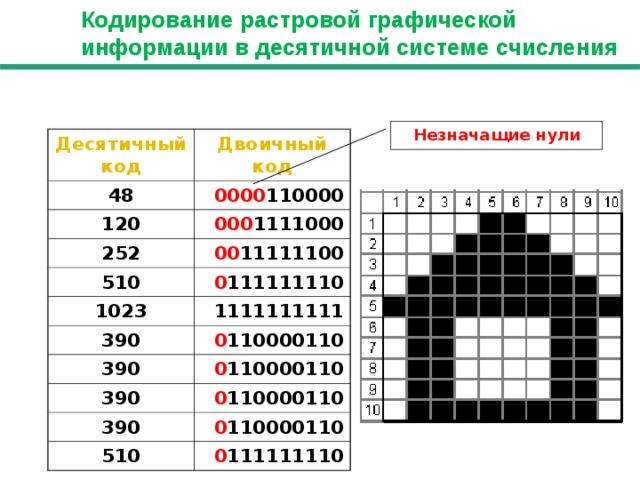
Представление текстовой информации При двоичном кодировании текстовой информации каждому символу соответствует его код – последовательность из 8 нулей и единиц, называемая байтом. Всего существует 256 разных последовательностей из 8 нулей и единиц. Это позволяет закодировать 256 символов, например большие и малые буквы латинского и русского алфавитов, цифры, знаки препинания, специальные символы, пробел и т. д.
Соответствие
байтов и символов задается с помощью
таблицы кодировки, в которой устанавливается
взаимосвязь между символами и их
порядковыми номерами в компьютерном
алфавите. Все символы компьютерного
алфавита пронумерованы от 0 до 255. Каждому
номеру соответствует восьмиразрядный
двоичный код от 00000000 до 11111111. Этот код
есть порядковый номер символа в двоичной
системе счисления.
Стандартными
в этой таблице являются только первые
128 символов, т. е. символы с номерами от
0 (двоичный код 000000000) до 127 (двоичный код
01111111). Сюда входят буквы латинского
алфавита, цифры, знаки препинания, скобки
и некоторые другие символы. остальные
128 кодов, начиная с 128 (двоичный код
10000000) и кончая 255 (двоичный код 11111111),
использу-ются для кодировки букв
национальных алфавитов, символов
псевдографики и научных симво-лов. В
русских национальных кодировках в этой
части таблицы размещаются символы
русского алфавита.
остальные
128 кодов, начиная с 128 (двоичный код
10000000) и кончая 255 (двоичный код 11111111),
использу-ются для кодировки букв
национальных алфавитов, символов
псевдографики и научных симво-лов. В
русских национальных кодировках в этой
части таблицы размещаются символы
русского алфавита.
Принцип последовательного кодирования алфавита: в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Современные ЭВМ реализованы на электронных элементах (триггерах), имеющих два устойчивых состояния (типа включен/выключен). Эти состояния кодируются – одно обозначается “0”(ноль), другое – “1” (единица). Таким образом, язык ЭВМ содержит как и азбука Морзе (телеграфная азбука) только два символа. Это в свою очередь, вынуждает для представления данных в ЭВМ использовать специальные коды. Данные по типу можно разделить на четыре группы.
СИМВОЛЬНЫЕ –
используются для обозначения понятий,
объектов и формирования ТЕКСТОВ по
правилам того или иного языка сообщений.
ЧИСЛОВЫЕ – используются для обозначения КОЛИЧЕСТВ в различных формах и различных системах счисления (двоичной, восьмеричной, десятичной и шестнадцатеричной)
ДАТА — используется для представления ДАТ в различных формах (американской, германской, европейской и других)
ЛОГИЧЕСКИЕ – используются для обозначения НАЛИЧИЯ или отсутствия какого-либо признака (ЕСТЬ/НЕТ) и имеют только два значения: ИСТИНА – обозначается либо .T., либо .
ЛОЖЬ –
обозначается либо .F.,
либо N Основным элементом кодированного
представления данных в ЭВМ является БАЙТ.
Это код из восьми позиций, в каждой из
которых может находиться либо 0,
либо 1.
Например: 01001000 или01000101 и
т.п. Каждая позиция называется разрядом или битом.
В зависимости от того, какой тип данных
представляет байт, его содержимое
интерпретируется по-разному.
При представлении СИМВОЛЬНЫХ данных один байт представляет собой кодированное представление одного символа, например
двоичный онлайн-конвертер
Изображение, показанное выше, может напомнить вам серию фильмов «Матрица», но для большинства людей оно все равно не имеет смысла. Изображение состоит из набора единиц и нулей, и большинство людей думают, что это компьютерный код. Это верно только до определенной степени. Именно так компьютер читает код, но не так, как он написан. Компьютеры — удивительные машины, но они, в конце концов, машины. Компьютер формируется как отражение человеческого разума. Компьютер способен хранить огромные объемы данных и алгоритмов, которые доступны мгновенно, что делает их очень эффективными машинами. Однако компьютер не способен думать самостоятельно. Это творческий потенциал человеческого разума, который способен распознавать закономерности в своем окружении и передавать эту информацию в компьютер.
Компьютеры могут преобразовывать текст в двоичный код для облегчения понимания и удобочитаемости.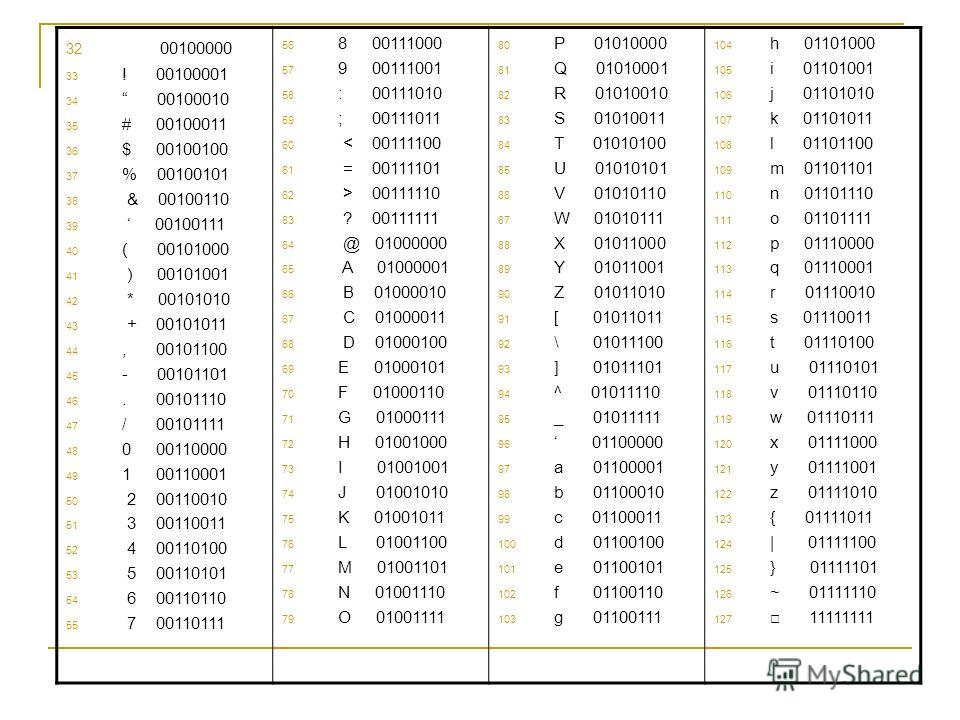 Например, простое слово, такое как «Привет», выглядит как «01101000 01100101 01101100 01101100 01101111» при преобразовании в двоичный формат. К счастью, эти преобразования не нужно делать вручную. Использование двоичного конвертера устраняет проблему.
Например, простое слово, такое как «Привет», выглядит как «01101000 01100101 01101100 01101100 01101111» при преобразовании в двоичный формат. К счастью, эти преобразования не нужно делать вручную. Использование двоичного конвертера устраняет проблему.
По мере взросления человеческий ребенок развивает нечто, известное как «здравый смысл». Если ребенок упирается в стену, которая не движется, он пытается найти способ обойти препятствие. Компьютеры и роботы не обладают «здравым смыслом» и терпят неудачу на самом базовом уровне. В новых технологиях и достижениях используются точные датчики, превосходное кодирование и искусственный интеллект, чтобы заставить роботов определять препятствия, но смоделированные сценарии все еще очень ограничены. Машины, захватившие мир и приведшие к апокалипсису, на данный момент кажутся маловероятными.
Что такое двоичный код? Двоичный код — это набор математических правил и языка. Это то, как компьютеры интерпретируют код и действуют соответственно.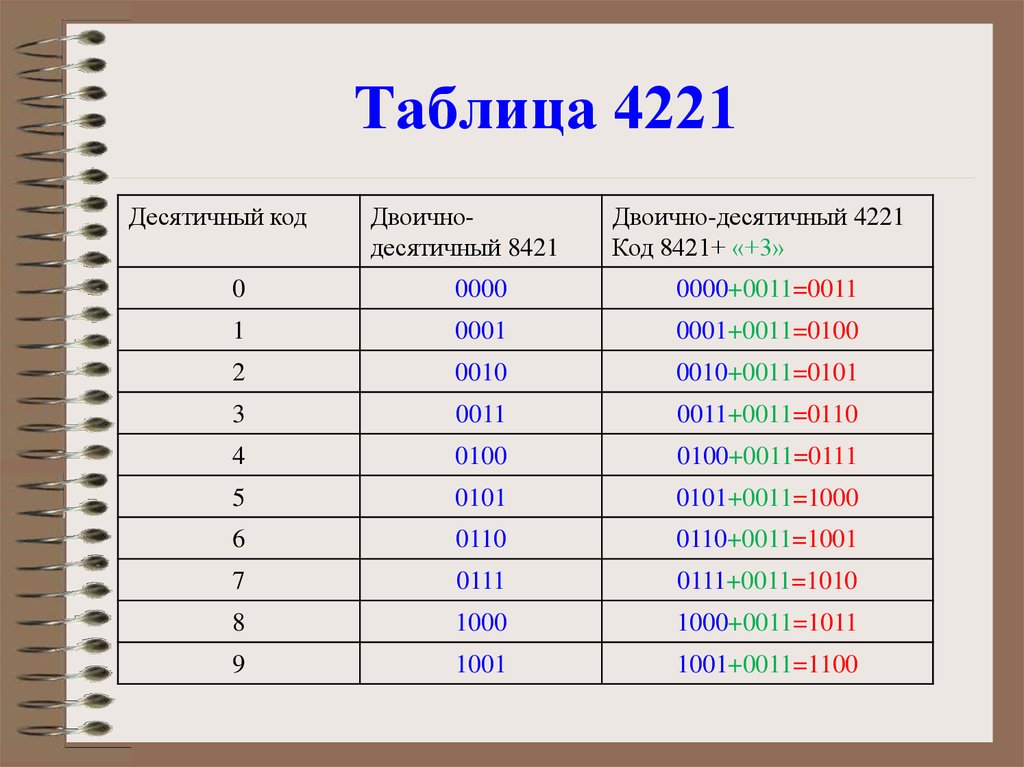 Представьте себе, что компьютер — это очень мощный калькулятор, который производит миллионы вычислений в секунду, расшифровывая шаблоны и предсказывая точные результаты. Хотя компьютер может быть быстрее человеческого мозга, он не может быть творческим как таковым, если уравнение полностью разваливается.
Представьте себе, что компьютер — это очень мощный калькулятор, который производит миллионы вычислений в секунду, расшифровывая шаблоны и предсказывая точные результаты. Хотя компьютер может быть быстрее человеческого мозга, он не может быть творческим как таковым, если уравнение полностью разваливается.
Двоичная система счисления состоит только из двух возможных значений результата: единицы и нуля, также называемых «высоким» и «низким» значениями. Единица означает, что значение принято, и функция может двигаться вперед с ним, тогда как ноль означает, что значение не принято, и код завершается в этой точке. Компьютеры работают по сложным алгоритмам, похожим на блок-схемы. В тот момент, когда блок-схема не может отразить новую ситуацию, компьютерная программа дает сбой.
Каждая двоичная цифра известна как «Бит» и является наименьшей единицей данных на компьютере. Каждый бит может содержать одно значение 1 или 0. Изучение того, как вычислять числа и программы в двоичном формате, является основой компьютерного программирования.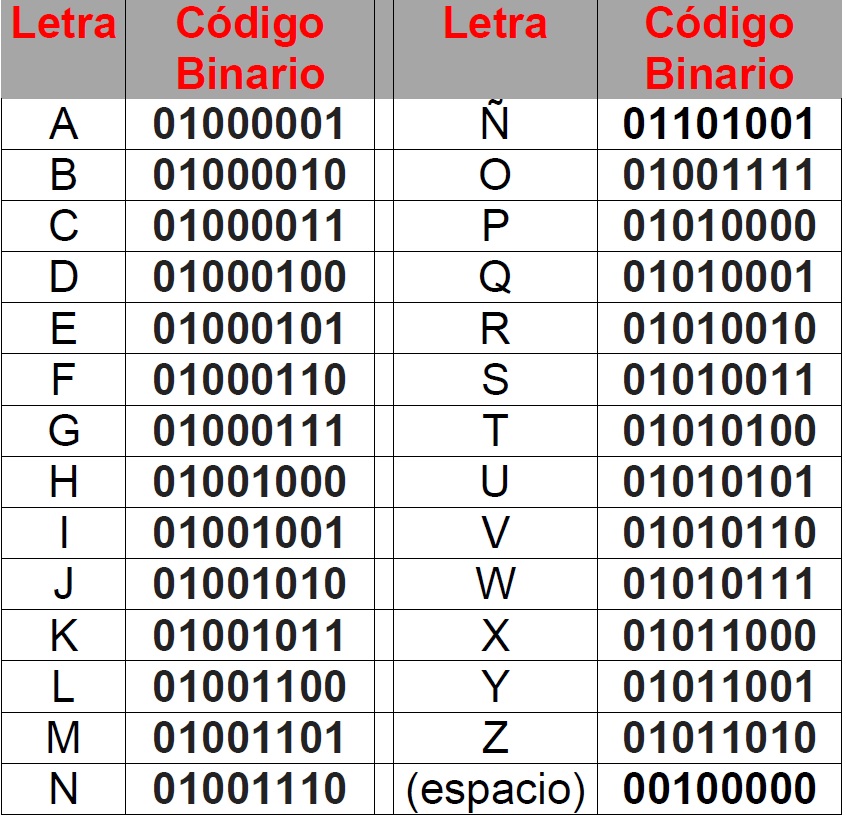 Онлайновые двоичные конвертеры широко доступны для более легкого использования и понимания.
Онлайновые двоичные конвертеры широко доступны для более легкого использования и понимания.
Алан Тьюринг, британский математик, первым изобрел что-то похожее на компьютер. Хотя в то время компьютер был размером с комнату и имел много проводов и операторов для его управления. Тьюринг использовал компьютеры для расшифровки зашифрованных сообщений, отправленных немцами во время Второй мировой войны, и саботировал их планы, давая британцам преимущество в войне. Первые компьютеры работали так же, как и современные, с миллионами перестановок и комбинаций в калькуляторе для получения результатов. Для реализации алгоритмов использовались базовые блок-схемы и двоичная система. Хотя в то время не было интернета и не было онлайн-конвертера двоичных файлов. Было непросто преобразовать слова в код, понятный компьютеру.
Кто использует двоичный код? Двоичный код — это базовая форма понимания современных компьютеров и их работы. Без предварительного изучения того, как работает двоичный код, вы не сможете иметь ясного представления о том, как компьютеры читают и пишут код. Таким образом, вопрос, который вы действительно должны задать, заключается в том, чем полезен двоичный код. Хотя онлайн-конвертер двоичных файлов может быть учебным инструментом для понимания работы двоичных файлов и преобразования в другие языки, в настоящее время он нигде напрямую не используется. Студенты, изучающие информатику и разработку приложений, изучают двоичный код в качестве базового курса, но вскоре переходят на другие языки, такие как html, java, php, C++ и python. Двоичный формат лежит в основе всех этих языков.
Без предварительного изучения того, как работает двоичный код, вы не сможете иметь ясного представления о том, как компьютеры читают и пишут код. Таким образом, вопрос, который вы действительно должны задать, заключается в том, чем полезен двоичный код. Хотя онлайн-конвертер двоичных файлов может быть учебным инструментом для понимания работы двоичных файлов и преобразования в другие языки, в настоящее время он нигде напрямую не используется. Студенты, изучающие информатику и разработку приложений, изучают двоичный код в качестве базового курса, но вскоре переходят на другие языки, такие как html, java, php, C++ и python. Двоичный формат лежит в основе всех этих языков.
В основе всех программ лежит двоичный код, хотя некоторые из них более полезны, чем другие. Вот несколько полезных программ, используемых почти везде, куда бы вы ни пошли.
Android и iOS Смартфоны являются наиболее распространенным примером расширенного программирования и кодирования.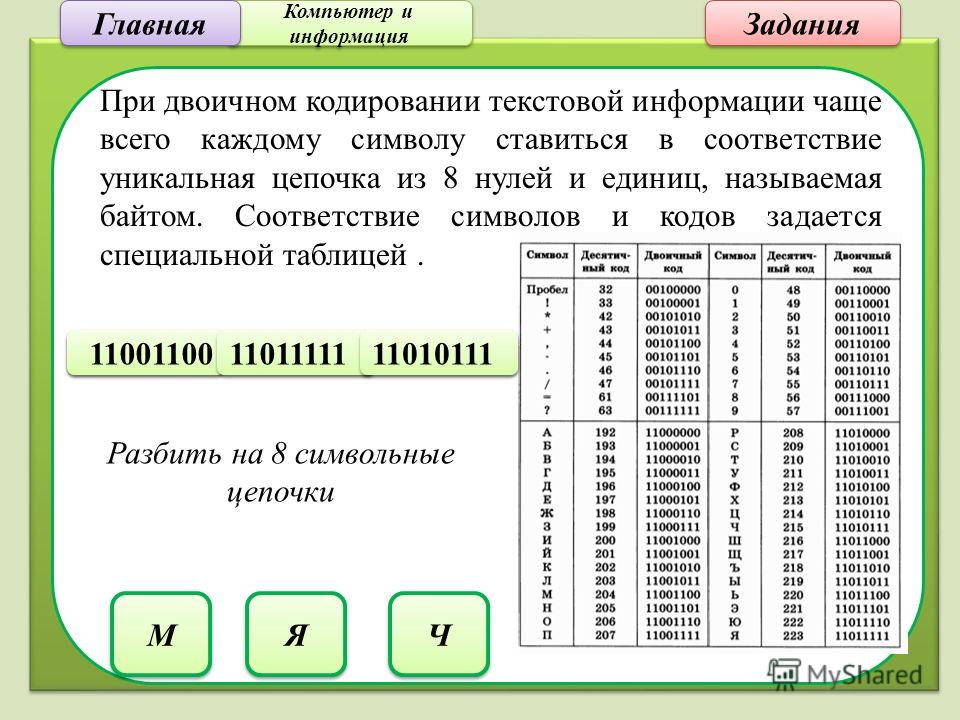 Телефоны Android и iOS используют многоуровневую структуру для запуска своих операционных систем. У вас есть мини-суперкомпьютер на ладони. В нем есть все функции, которые могут вам понадобиться для удобного выполнения повседневных дел. В нем есть камера, mp3-плеер, блокнот, калькулятор, игры и видео и так далее. Многие люди недостаточно используют свои телефоны, и это такой позор, потому что эти машины предназначены для гораздо большего.
Телефоны Android и iOS используют многоуровневую структуру для запуска своих операционных систем. У вас есть мини-суперкомпьютер на ладони. В нем есть все функции, которые могут вам понадобиться для удобного выполнения повседневных дел. В нем есть камера, mp3-плеер, блокнот, калькулятор, игры и видео и так далее. Многие люди недостаточно используют свои телефоны, и это такой позор, потому что эти машины предназначены для гораздо большего.
Вы можете использовать свои старые мобильные телефоны для добычи биткойнов. Майнинг биткойнов также включает в себя преобразование кода и реализацию. Однако для этого вам нужно будет создать онлайн-аккаунт. Хотя добыча биткойнов на самом деле не требует использования онлайн-конвертера двоичных файлов, все же интересно узнать, как все это работает. Биткойн недавно взлетел выше отметки в 7500 долларов и, как ожидается, к 2018 году вырастет до 25 000 долларов. В начале 2017 года он составлял около 1200 долларов. Если вы опоздаете на гонку, это все равно может быть хорошей инвестиционной возможностью для получения прибыли.
Adobe берет верх над созданием и редактированием цифровых медиафайлов. Пакет Adobe включает Illustrator, Photoshop, Premiere и After Effects. Эти программы производят высокоточные цифровые и печатные носители. Программное обеспечение используется для создания нового контента, дизайна, телевизионных рекламных роликов, учебных материалов и документальных фильмов. Многие компании используют это программное обеспечение для разработки своих логотипов, инфографики и бизнес-презентаций. Просто подумайте, что основа всех этих программ сводится к пониманию двоичного кода и кода.
Разработка игр Игры с открытым миром используют сложные физические движки, чтобы сделать их более реалистичными, но в конце концов все сводится к единицам и нулям. Блок-схемы помогают компьютеру выполнять последовательные функции, когда они требуются. Хотя дизайн и графика исходят из вышеупомянутого программного обеспечения для дизайна и цифровых изображений, компьютер считывает код в двоичном формате, что делает все это реалистичным и обеспечивает сотни часов увлекательного игрового процесса.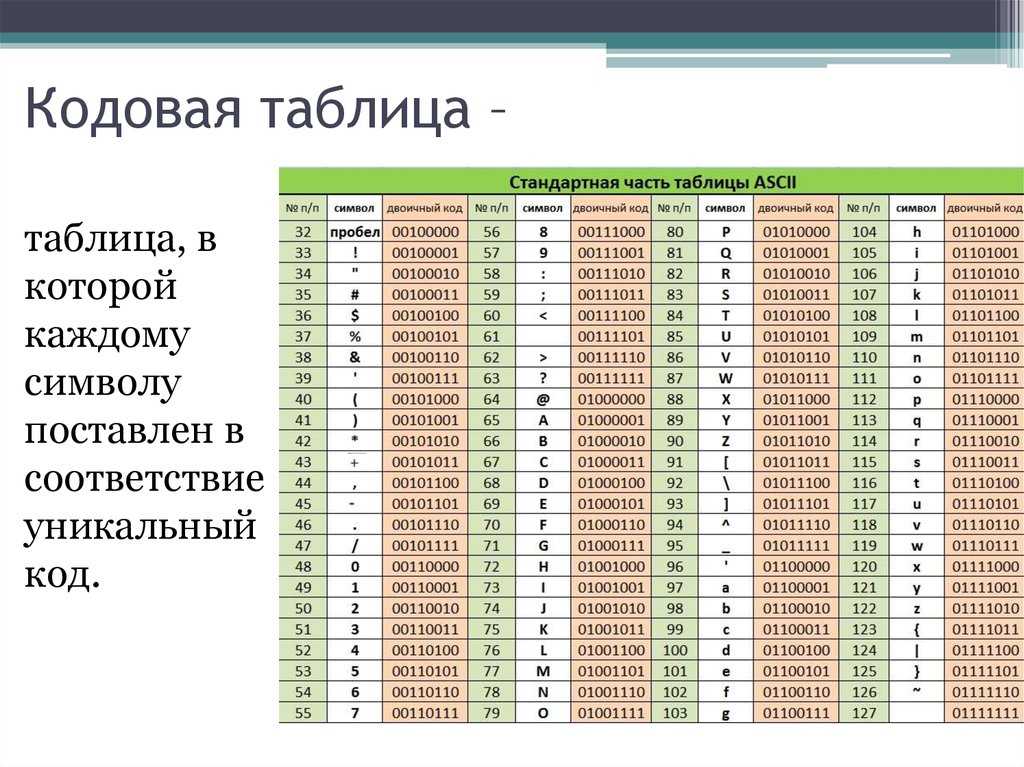 Самые известные игры с открытым миром включают Grand Theft Auto V и Watch Dogs.
Самые известные игры с открытым миром включают Grand Theft Auto V и Watch Dogs.
Архитекторы используют цифровое программное обеспечение для проектирования домов и зданий с помощью программ автоматизированного проектирования (CAD), прежде чем наносить что-либо на бумагу и начинать строительство. Компьютеры способны выполнять сложное 3D-моделирование, которое невозможно на плоском листе бумаги. С помощью САПР вы можете получить реальную картину того, как будет выглядеть здание, когда оно будет завершено. Это также позволяет вам вносить необходимые изменения еще до начала работы.
Сложные алгоритмы и программное обеспечение для проектирования позволяют создавать уникальные по форме и красивые конструкции, которые ранее были невозможны. Можно строить высокие небоскребы, устойчивые к землетрясениям и стихийным бедствиям. Всегда полезно пройти хотя бы несколько базовых курсов компьютерного программирования в колледже или старшей школе, чтобы лучше понять, куда движется мир.
Прежде чем вы начнете сносить стены и покупать мебель, которая не подходит к шторам, вы можете использовать программное обеспечение для дизайна интерьера, чтобы смоделировать, как будет выглядеть дом. Возможно, вам даже не придется нанимать профессионала и платить тысячи долларов за ремонт дома. Просто загуглите пару образцов, чтобы дать волю своим сокам, а затем дайте волю своему природному творчеству. Есть так много, чего вы можете достичь самостоятельно и с помощью некоторых техник DIY.
МузыкаВсе любят музыку, если только вы не мертвы внутри. Студии звукозаписи и многие артисты используют компьютерное программирование и программное обеспечение для тонкой настройки своей музыки, чтобы сделать ее более привлекательной для своих поклонников.
Заключительное слово Узнав о многих областях, использующих компьютерное программирование для повышения своих результатов, вы должны подумать, в какой области оно не используется.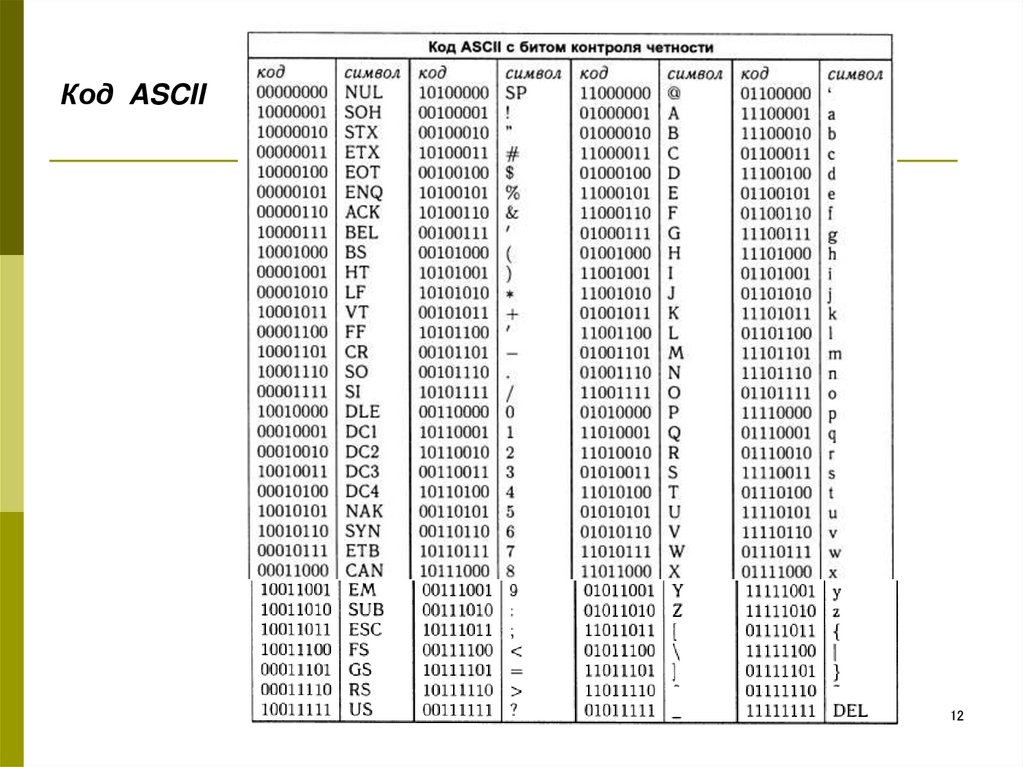 Практически нет. Компьютеры сформировали современный мир. И если вы не можете вести осмысленный разговор в группе друзей о бинарном и компьютерном программировании и чувствуете себя потерянным, вы скоро станете изгоем группы.
Практически нет. Компьютеры сформировали современный мир. И если вы не можете вести осмысленный разговор в группе друзей о бинарном и компьютерном программировании и чувствуете себя потерянным, вы скоро станете изгоем группы.
Бесплатный онлайн переводчик английского текста в двоичный
О бесплатном переводчике английского языка в двоичный
Наш переводчик с английского на двоичный преобразует обычный текст/английский или ASCII в двоичный код для связи с электронными машинами. Просто вставьте обычный текст/английский или значение ASCII и нажмите кнопку преобразования текста в двоичный формат.
Этот инструмент является лучшим вариантом для преобразования вашей строки английских букв в двоичный код (0 и 1), чтобы его было легко понять электронными машинами. Текстовая строка на английском языке или ASCII при переводе становится длинной строкой чисел.
Например,
- «привет» в двоичном формате будет 01001000 01100101 01101100 01101100 01101111.

- Заглавная буква «А» будет 01000001.
- Строчная буква «а» будет 01100001.
Зачем нам нужен конвертер текста для преобразования текста в двоичный формат?
Все мы знаем, что компьютеры понимают двоичный язык — язык 0 и 1. Двоичный код использовался веками, поэтому он широко используется в наших электронных машинах. Может быть несколько причин, по которым нам может потребоваться конвертер текста для преобразования простого текста/английского языка или ASCII в двоичный код, особенно когда нам нужно взаимодействовать с электронным устройством. Было бы лучше иметь двоичный язык, который система понимает и который выполняется преобразователем текста для предоставления двоичного кода.
Как использовать переводчик текста для перевода английского или ASCII в двоичный код?
Когда нам нужно быстро преобразовать текст на английском языке или ASCII в двоичный код, лучше всего использовать онлайн-инструмент преобразования букв в двоичные.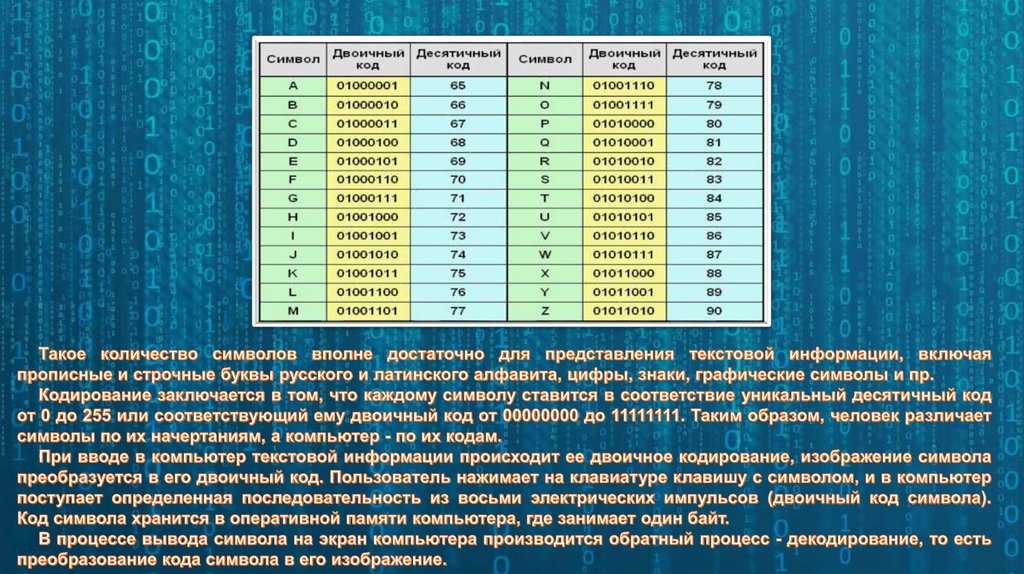 Этот процесс менее сложен и может быть выполнен в несколько кликов.
Этот процесс менее сложен и может быть выполнен в несколько кликов.
Использовать конвертер текста в двоичный код просто и требует выполнения нескольких шагов.
- Откройте конвертер текста в двоичный код.
- Введите текстовую строку ASCII и выберите тип «Кодировка символов».
- Нажмите кнопку «Конвертировать». Инструмент работает как конвертер текста в двоичный код, где слова точно и безошибочно переводятся в двоичный код.
- Например, введя текст «Пример», вы получите двоичный код «01000101 01111000 01100001 01101101 01110000 01101100 01100101».
- Если вы хотите перевести двоичный код в обычный текст/английский или ASCII. Используйте наш бинарный переводчик для бинарного перевода.
Часто задаваемые вопросы
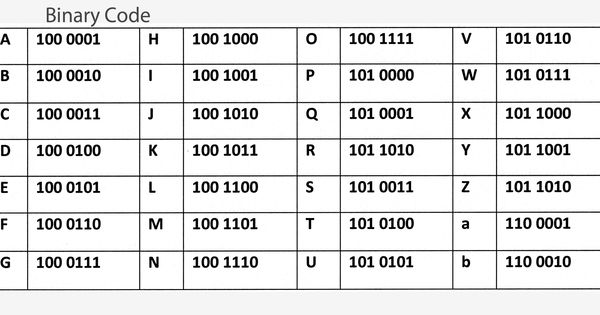
Как преобразовать букву «А» в двоичную? 90 128 64 32 16 8 4 2 1 0 1 0 0 0 0 0 1
Таким образом, заглавная буква «А» в двоичном коде будет 01000001
.
Как преобразовать число «0» в двоичное?
При первой регистрации в таблице цифре «0» присваивается десятичное число 48. 90
Таким образом, число «0» в двоичном формате будет 00110000
.Как преобразовать слово «Вау» в двоичное?
Сначала проверьте таблицу и получите десятичное число каждого алфавита.
Вт = 87
о = 111
ш = 119
- Для W
87 = 64 + 16 + 4 + 2 + 1128 64 32 16 8 4 2 1 0 1 0 1 0 1 1 1 Таким образом, заглавная буква «W» в двоичном коде будет 01010111
- Для о
111 = 64 + 32 + 8 + 4 + 2 +1128 64 32 16 8 4 2 1 0 1 1 0 1 1 1 1 Таким образом, маленькая буква «о» в двоичном коде будет 01101111
. - Для ж
119 = 64 + 32 + 16 + 4 + 2 + 1128 64 32 16 8 4 2 1 0 1 1 1 0 1 1 1 Таким образом, маленькая буква «о» в двоичном коде будет 01110111
.

Значит слово «Вау» в бинарном виде будет 01010111 01101111 01110111
Как преобразовать слово «Любовь» в двоичное?
Процесс будет аналогичен описанному выше. Просто имейте в виду, что значения для прописных и строчных букв будут разными.
Значит слово «Любовь» в бинарном виде будет 01001100 01101111 01110110 01100101
Текст ASCII в шестнадцатеричный и двоичная таблица преобразования
С помощью этого символа ASCII в двоичную диаграмму можно выполнить ручное преобразование текста в двоичный формат.
| Двоичный | Десятичный | Символ ASCII | Шестигранник |
| 0 | 0 | НУЛ | 0 |
| 1 | 1 | СОХ | 1 |
| 10 | 2 | СТХ | 2 |
| 11 | 3 | ЕТХ | 3 |
| 100 | 4 | ЭОТ | 4 |
| 101 | 5 | ENQ | 5 |
| 110 | 6 | ПОДТВЕРЖДЕНИЕ | 6 |
| 111 | 7 | БЕЛ | 7 |
| 1000 | 8 | БС | 8 |
| 1001 | 9 | НТ | 9 |
| 1010 | 10 | ЛФ | 0А |
| 1011 | 11 | ВТ | 0Б |
| 1100 | 12 | ФФ | 0С |
| 1101 | 13 | КР | 0Д |
| 1110 | 14 | СО | 0Е |
| 1111 | 15 | СИ | 0Ф |
| 10000 | 16 | ДЛЭ | 10 |
| 10001 | 17 | ДС1 | 11 |
| 10010 | 18 | ДС2 | 12 |
| 10011 | 19 | ДС3 | 13 |
| 10100 | 20 | ДС4 | 14 |
| 10101 | 21 | НАК | 15 |
| 10110 | 22 | СИН | 16 |
| 10111 | 23 | ЭТБ | 17 |
| 11000 | 24 | МОЖЕТ | 18 |
| 11001 | 25 | ЭМ | 19 |
| 11010 | 26 | СУБ | 1А |
| 11011 | 27 | ЕСК | 1Б |
| 11100 | 28 | ФС | 1С |
| 11101 | 29 | ГС | 1D |
| 11110 | 30 | RS | 1Э |
| 11111 | 31 | США | 1F |
| 100000 | 32 | Космос | 20 |
| 100001 | 33 | ! | 21 |
| 100010 | 34 | » | 22 |
| 100011 | 35 | # | 23 |
| 100100 | 36 | $ | 24 |
| 100101 | 37 | % | 25 |
| 100110 | 38 | и | 26 |
| 100111 | 39 | ‘ | 27 |
| 101000 | 40 | ( | 28 |
| 101001 | 41 | ) | 29 |
| 101010 | 42 | * | 2А |
| 101011 | 43 | + | 2Б |
| 101100 | 44 | , | 2С |
| 101101 | 45 | – | 2D |
| 101110 | 46 | .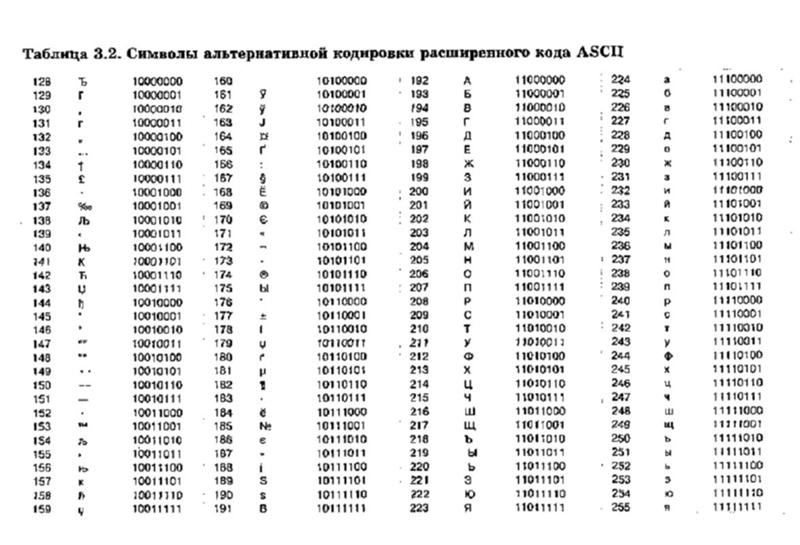 |