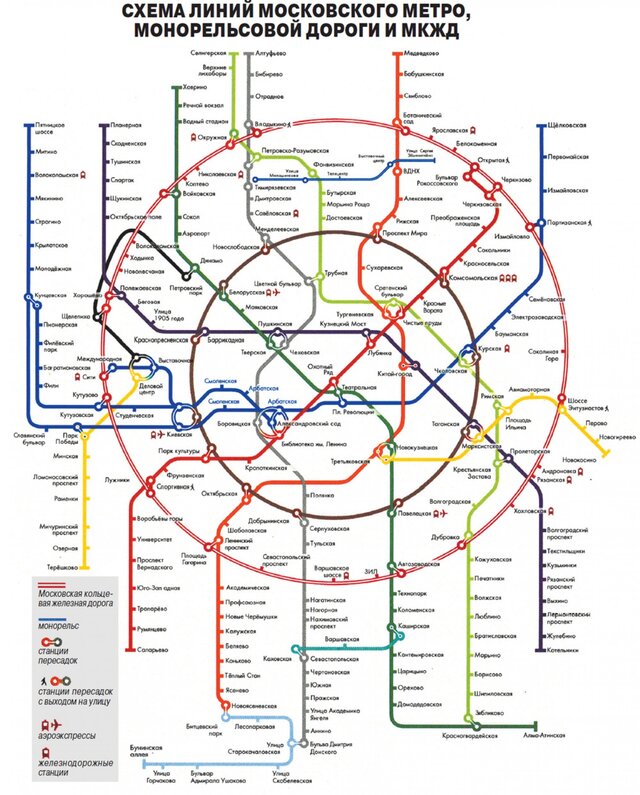
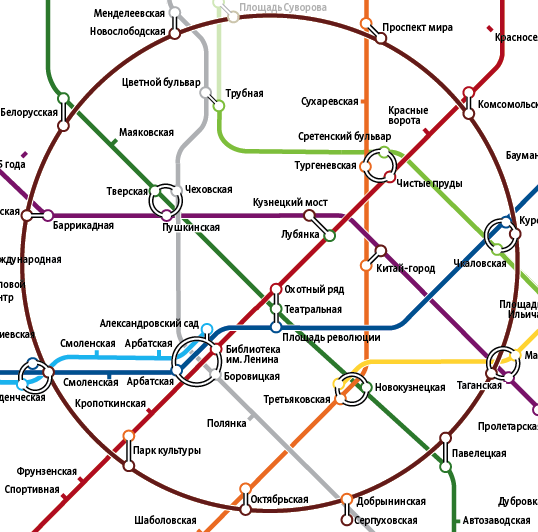
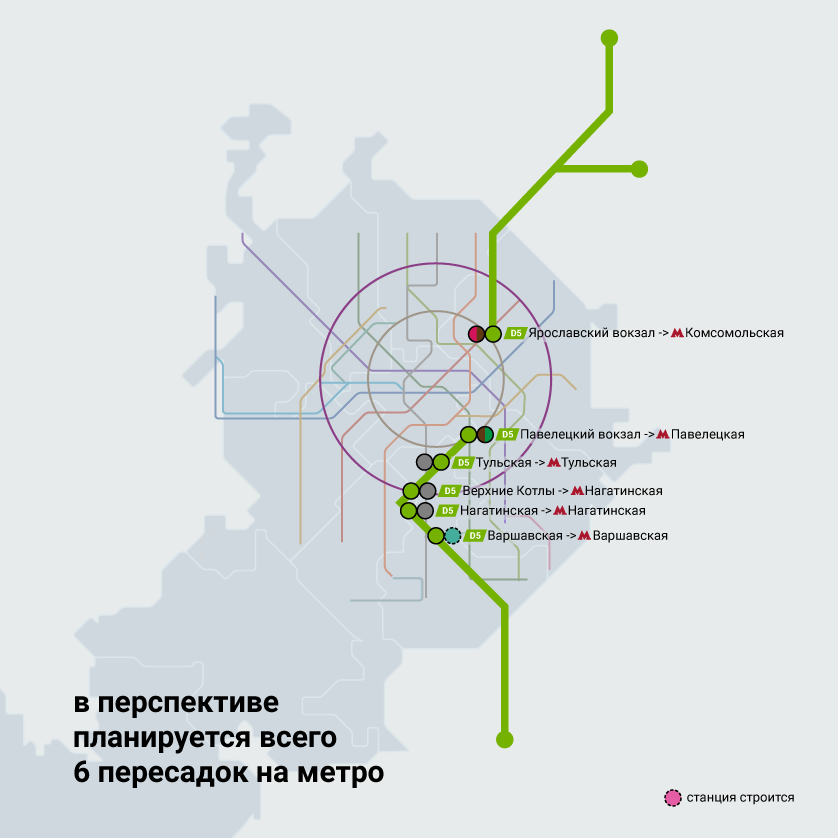
NetApp MetroCluster (MCC) / Хабр
MetroCluster гео-распределённый, отказоустойчивый кластер построенный на базе систем хранения данных NetApp FAS, такой кластер можно представить себе, как одну систему хранения, растянутую на два сайта, где в случае аварии на одном из сайтов всегда остаётся полная копия данных. MetroCluster используется для создания высоко доступного (HA) хранилища и сервисов. Более подробно о MCC официальной документации.
MetroCluster работающий на старой ОС Data ONTAP 7-Mode (до версии 8.2.х) имел аббревиатуру «MC», а работающий на ClusteredONTAP (8.х и старше), чтобы не было путаницы, принято называть MetroCluster ClusteredONTAP (MCC).
MCC может состоять из двух и более контроллеров. Существует три схемы подключения MCC:
- Fabric-Attached MetroCluster (FCM-MCC)
- Bridge-Attached Stretch MetroCluster
- Stretch MetroCluster
Различие в этих трех вариантах по сути только в сетевой обвязке.
Fabric-Attached MetroCluster
Эта конфигурация может состоять как из двух, так и из 4 идентичных контроллеров. Дву-нодовая конфигурация (mcc-2n) может быть конвертирована в четырех нодовую (mcc). В двухнодовой конфигурации на каждом сайте располагается по одному контроллеру и в случае выхода одного контроллера второй на другом сайте забирает на себя управление, это называется switchover. Если на каждом сайте есть больше чем одна нода, при этом выходит из строя одна нода кластера, то происходит локальный HA failover
Это самая затратная схема из всех вариантов подключения, так как требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- Дополнительных SAN свитчей на бэк-енде (не путать со свитчами для подключения СХД и хостов)
- Дополнительных SAS-FC бриджей
- FC-VI порты
- Возможно xWDM мультиплексоров
- И минимум 2 ISL long-wave FC SFP+ линка (4 жилы: 2x RX, 2x TX).
 Т.е. к СХД подводится «темная оптика» (в промежутках может быть только xWDM, без каких-либо коммутаторов), эти линки выделенные исключительно под задачи репликации СХД (FC-VI & бэк-енд соединения)
Т.е. к СХД подводится «темная оптика» (в промежутках может быть только xWDM, без каких-либо коммутаторов), эти линки выделенные исключительно под задачи репликации СХД (FC-VI & бэк-енд соединения)
 Т.е. к СХД подводится «темная оптика» (в промежутках может быть только xWDM, без каких-либо коммутаторов), эти линки выделенные исключительно под задачи репликации СХД (FC-VI & бэк-енд соединения)
Т.е. к СХД подводится «темная оптика» (в промежутках может быть только xWDM, без каких-либо коммутаторов), эти линки выделенные исключительно под задачи репликации СХД (FC-VI & бэк-енд соединения)Итого между двумя сайтами минимум необходимо 4 жилы, плюс Cluster peering.
8-Node MCC
По аналогии с 4-х нодовой конфигурацией Fabric-Attached MetroCluster существует восьми-нодовая конфигурация, которая пока что поддерживает работу только с NAS протоколами доступа и прошивкой ONTAP 9. четырех нодовая конфигурация может обновляться до восьми нод. Такая конфигурация пока что не поддерживает SAN протоколы доступа. В восьми-нодовой конфигурации, 4 ноды расположены на одном сайте и 4 на другом. С точки зрения сети ничего особенно не меняется, в аналогичной схеме Fabric-Attached MetroCluster из 4 нод: количество FC свичей на бэк-енде остаётся прежним, увеличивается только число необходимых портов на каждом сайте для локальных коммутаций, но межсайтовых соединений и межсайтовых портов может быть столько же.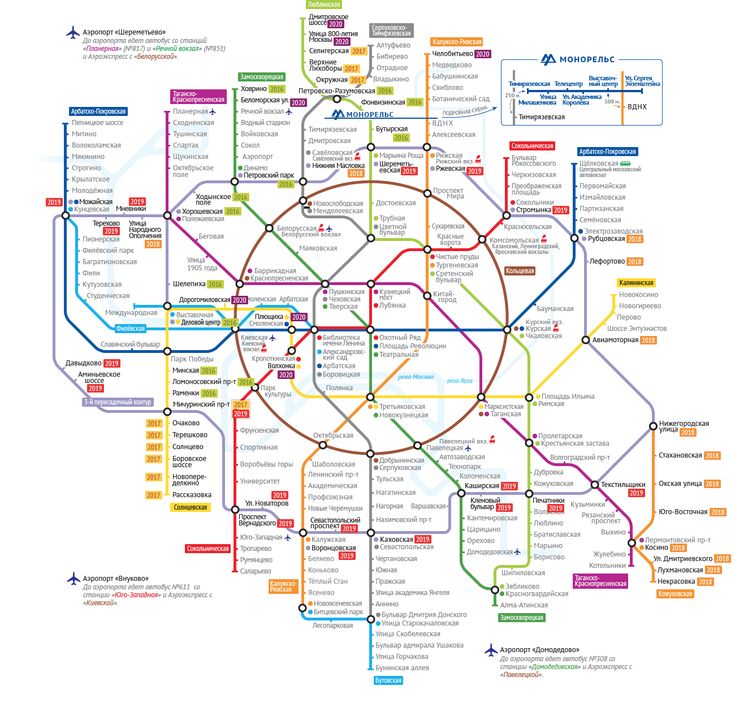
Bridge-Attached Stretch MetroCluster
Может растягиваться до 500 метров и требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- Дополнительных SAS-FC бриджей
- FC-VI порты
- минимум два линка (4 жилы: 2x RX, 2x TX) темной оптики выделенные исключительно под подключение контроллеров СХД (FC-VI)
- И минимум четыре линка (итого 4х2 = 8 жил) темной оптики выделенные исключительно под бэк-енд связи
Итого между двумя сайтами минимум необходимо 4+8=12 жил, плюс Cluster peering.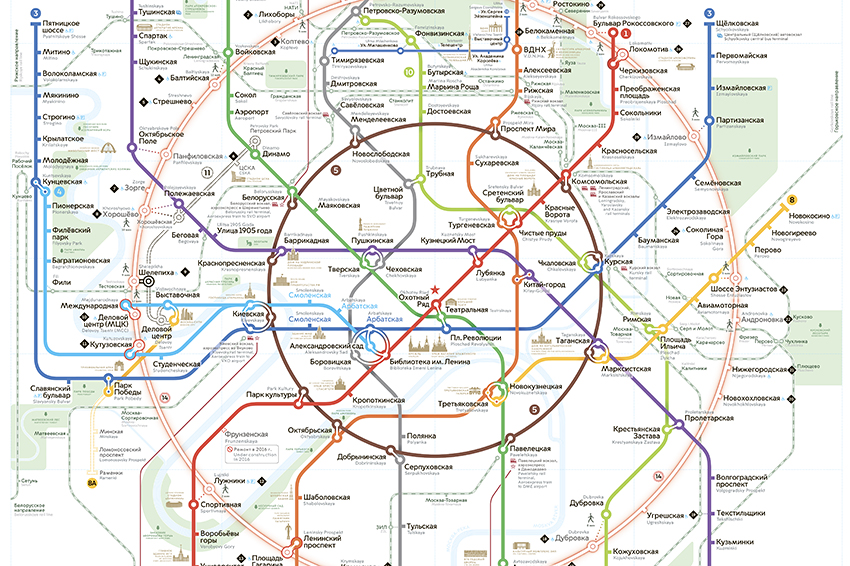
Stretch MetroCluster с прямым включением
Самый дешевый вариант. Может растягиваться до 500 метров и требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- FC-VI порты
- минимум два линка (4 жилы: 2x RX, 2x TX) темной оптики выделенные исключительно под подключение контроллеров СХД (FC-VI)
- И минимум два 4 канальных (для каждого канала 2 жили: RX и TX) кабеля (итого 2х8 = 16 жил) темной оптики выделенные исключительно под задачи репликации для доступа к каждой полке по двум путям.
- Для бэк-енд связности полок используется специальный 4 канальный (для каждого канала 2 жили: RX и TX) оптический SAS коннектор и оптическая патч-панель
Итого между двумя сайтами минимум необходимо 4+16=20 жил, плюс Cluster peering.
Оптический кабель для Stretch MetroCluster
В зависимости от расстояния и скорости подключения, применяется различный оптический кабель для конфигураций Stretch MetroCluster с прямым включением.
| Speed (Gbps) | Maximum distance (m) | |||
|---|---|---|---|---|
| 16Gbps SW SFP | 16Gbps LW SFP | |||
| OM2 | OM3 | OM3+/OM4 | Single-Mode (SM) Fiber | |
| 2 | N/A | N/A | N/A | N/A |
| 4 | 150 | 270 | 270 | 500 |
| 8 | 50 | 170 | 500 | |
| 16 | 35 | 100 | 125 | 500 |
FC-VI порты
Обычно на каждый FAS контроллер метро кластера устанавливается специализированная плата расширения, на которой FC порты работают в режиме FC-VI. На некоторых 4-портовых FC HBA платах для FAS контроллеров разрешается использовать 2 порта для FC-VI и 2 других как таргет или инициатор порты. У некоторых FAS моделей порты на борту материнской платы могут переключаться в FC-VI режим. Порты с ролью FC-VI используют протокол Fibre Channel для зеркалирования содержимого NVRAM между контроллерами метро кластера.
У некоторых FAS моделей порты на борту материнской платы могут переключаться в FC-VI режим. Порты с ролью FC-VI используют протокол Fibre Channel для зеркалирования содержимого NVRAM между контроллерами метро кластера.
Active/Active
Есть два основных подхода при репликации данных:
- «Подход А»: Обеспечивается защита от Split-Brain
- «Подход Б»: В котором есть возможность доступа (чтение и запись) ко всем данным через все сайты
Это по определению два взаимоисключающие подхода.
Преимущество «Подхода Б» в том, что нет задержек синхронизации между двумя сайтами. В силу не ведомых мне обстоятельств некоторые производители СХД допускают схемы в которых возможен Spit-Brain. Бывают реализации по сути, работающие по «Подходу А», но при этом эмулирующие возможность писать на обе стороны одновременно, как бы скрывая Active/Passive архитектуру, но суть такой схемы в том, что пока конкретная одна такая транзакция записи не синхронизируется между двумя площадками, она не будет подтверждена, назовём его «Гибридный подход», в ней всё-равно есть основной набор данных и его зеркальная копия.
На рисунке визуализированы 3 варианта возможных путей обращения к данным. Первый вариант (Path 1) это классическая реализация подхода для защиты от Split-Brain: данные проходят один раз по локальному пути и один раз по длинному межсайтовому соединению ISL (Inter Switch Link) для зеркалирования. Этот вариант обеспечивает как-бы Active/Passive режим роботы кластеров, но при этом на каждом сайте есть свои хосты, каждый из которых обращается к своему локальному хранилищу (Direct Path), где обе стороны кластера утилизированы, образуя таким образом Active/Active конфигурацию.
Split-Brain
Как было сказано в разделе Active/Active, метро кластер архитектурно устроен таким образом, что локальные хосты работают с локальной половинкой метро кластера. И только в случае, когда целиком один сайт умирает, хосты переключаются на второй сайт. А что происходит если оба сайта живые, но просто пропала связь между ними? В архитектуре метро кластера все просто — хосты продолжают работать, писать и читать, в свои локальные половинки как ни в чём небывало. Просто в этот момент прекращается синхронизация между площадками. Как только линки будут восстановлены, обе половинки метро кластера автоматически начнут синхронизироваться. В такой ситуации данные будет вычитываться с основного плекса, а не как это обычно происходит через NVRAM, после того как оба плекса снова станут одинаковыми зеркалирование вернется в режим репликации на основе памяти NVRAM.
И только в случае, когда целиком один сайт умирает, хосты переключаются на второй сайт. А что происходит если оба сайта живые, но просто пропала связь между ними? В архитектуре метро кластера все просто — хосты продолжают работать, писать и читать, в свои локальные половинки как ни в чём небывало. Просто в этот момент прекращается синхронизация между площадками. Как только линки будут восстановлены, обе половинки метро кластера автоматически начнут синхронизироваться. В такой ситуации данные будет вычитываться с основного плекса, а не как это обычно происходит через NVRAM, после того как оба плекса снова станут одинаковыми зеркалирование вернется в режим репликации на основе памяти NVRAM.
Active/Passive и Unmirrored Aggregates
MCC это полностью симметричная конфигурация: сколько дисков на одном сайте столько и на другом, какие FAS системы стоят на одном сайте, такие же должны быть и на другом. Начиная с версии прошивки ONTAP 9 для FAS систем, допускается иметь Unmirrored агрегаты (пулы).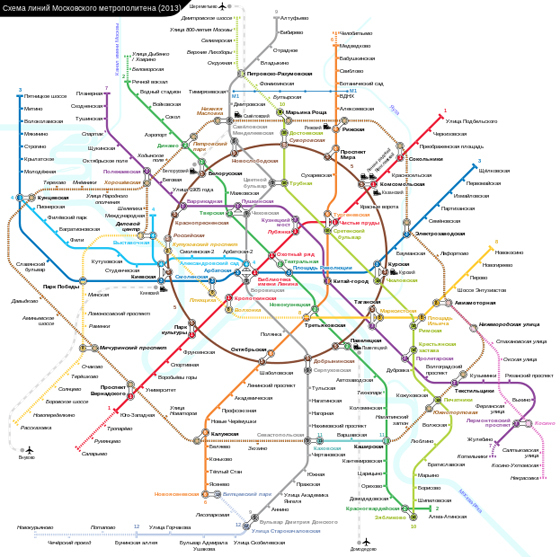 Таким образом, в новой прошивке количество дисков теперь может отличаться на двух площадках. Таким образом, к примеру, на одном сайте могут быть два агрегата, один из них зеркалируется (на удалённом сайте полное зеркало по типам дисков, их скорости, рейд группам), второй агрегат, который есть только на первом сайте, но он не реплицируется на удалённый сайт.
Таким образом, в новой прошивке количество дисков теперь может отличаться на двух площадках. Таким образом, к примеру, на одном сайте могут быть два агрегата, один из них зеркалируется (на удалённом сайте полное зеркало по типам дисков, их скорости, рейд группам), второй агрегат, который есть только на первом сайте, но он не реплицируется на удалённый сайт.
Стоит разделить два варианта Active/Passive конфигураций:
- Первый вариант. Когда используется только один основной сайт, а второй принимает реплику и живёт для подстраховки на случай выключения основного сайта
- Второй вариант. Когда есть 4 или больше ноды в кластере и на каждом сайте используется не все контроллеры
Unmirrored агрегаты позволяют создавать ассиметричные конфигурации и как крайний, частный случай первый вариант Active/Passive конфигурации: когда только один сайт используется для продуктивной нагрузки, а второй принимает синхронную реплику и подстрахует на случай выхода из строя основной площадки. В такой схеме при выходе из строя одного контроллера, сразу происходит переключение на запасной сайт.
В такой схеме при выходе из строя одного контроллера, сразу происходит переключение на запасной сайт.
Второй вариант Active/Passive конфигурации собирают для экономии дисков в кластере из 4 или больше нод: только часть из контроллеров будут обслуживать клиентов, в то время как контроллеры, которые простаивают будут терпеливо ждать, когда умрёт сосед, чтобы его подменить. Такая схема позволяет не переключаться между сайтами в случае выхода из строя одного контроллера, а выполнить локальный НА takeover.
SyncMirror — Синхронная репликация
Технология SyncMirror позволяет зеркалировать данные и может работать в двух режимах:
- Local SyncMirror
- MetroCluster SyncMirror
Разница между локальным SyncMirror и MCC SyncMirror состоит в том, что в первом случае данные всегда зеркалируется из NVRAM
в рамках одного контроллера и сразу на два плекса, его иногда используют для того чтобы защититься от выхода из строя целой полки.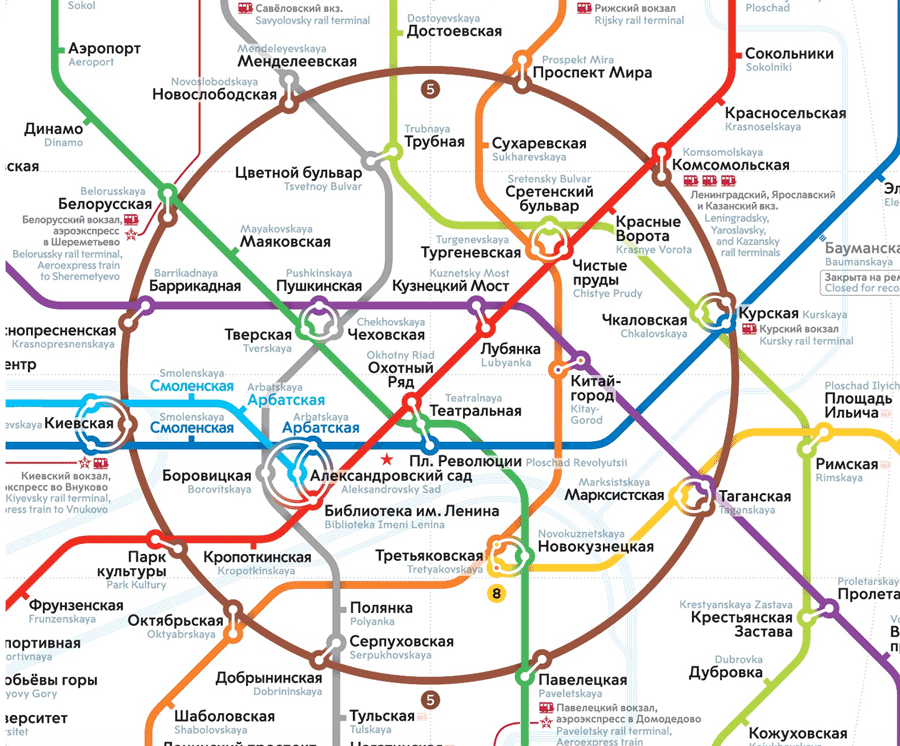 А во втором случае зеркалирование NVRAM выполняется между несколькими контроллерами. Зеркалирование NVRAM между несколькими контроллерами выполняется через специализированные FC-VI порты. MCC SyncMirror используется для защиты от выхода из строя целого сайта.
А во втором случае зеркалирование NVRAM выполняется между несколькими контроллерами. Зеркалирование NVRAM между несколькими контроллерами выполняется через специализированные FC-VI порты. MCC SyncMirror используется для защиты от выхода из строя целого сайта.
SyncMirror выполняет репликацию как-бы на уровне RAID, по аналогию с зеркальным RAID-60: есть два plex’а, Plex0 (основной набор данных) и Plex1 (зеркало), каждый плекс может состоять из одной или нескольких RAID-DP групп. Почему «как-бы»? Потому-что эти два плекса, они видны как составные, зеркальные части одного агрегата (пула), но на самом деле, в нормально работающей системе, зеркалирование выполняется на уровне NVRAM контроллера. А как вы можете уже знать WAFL, RAID-DP, NVRAM и NVLOG это всё составные части одной целой архитектуры дисковой подсистемы, и их весьма условно можно отделить одно от другого. Важной деталью технологии SyncMirror является необходимость в полной симметрии дисков в двух зеркалированых пулах: размер, тип, скорость дисков, RAID группы должны быть полностью одинаковы. Есть небольшие исключения из правил, но пока я не буду о них упоминать, чтобы не вводить читателя в заблуждение.
Есть небольшие исключения из правил, но пока я не буду о них упоминать, чтобы не вводить читателя в заблуждение.
Синхронная репликация позволяет с одной стороны снять нагрузку на дисковую подсистему, реплицируя только память, с другой стороны для решения проблемы Split-Brain и проблемы консистентности (с точки зрения структура WAFL на системе хранения) необходимо убедиться, что данные записаны на удалённую систему: в результате «синхронность», в любых системах хранения, увеличивает скорость отклика на время равное времени отправки данных на удалённый сайт + время подтверждения этой записи.
SnapMirror vs SyncMirror
Не путайте
- SyncMirror
- и SnapMirror
SyncMirror реплицирует содержимое одного плекса во второй плекс которые составляют собой один агрегат: все его RAID группы, условно говоря «по-дисково», где в зеркале должны быть такие же диски с таким же количеством, объемом, геометрией и скоростью. В SyncMirror MCC выполняется реплика NVLOG. В случае локального SyncMirror оба плекса живут и обслуживаются одним контроллером. А в случае SyncMirror MCC две половинки плекса живут, одна на одном контроллера, а вторая на удалённом. В один момент времени, в нормальной работе системы хранения, активен и работает только один плекс, второй только хранит копию информации.
В SyncMirror MCC выполняется реплика NVLOG. В случае локального SyncMirror оба плекса живут и обслуживаются одним контроллером. А в случае SyncMirror MCC две половинки плекса живут, одна на одном контроллера, а вторая на удалённом. В один момент времени, в нормальной работе системы хранения, активен и работает только один плекс, второй только хранит копию информации.
Каждый агрегат может содержать один или несколько FlexVol вольюмов (контейнер с данными), каждый вольюм равномерно размазывается по всем дискам в агрегате. Каждый вольюм это отдельная структура WAFL. В случае со SnapMirror, реплика выполняется на уровне WAFL и может выполняться на диски с совершенно другой геометрией, количеством и объёмом.
Если углубляться в технологии, то на самом деле, как Snap так и SyncMirror, для репликации данных используют снепшоты, но в случае SyncMirror это системные снепшоты по событию СP (NVRAM/NVLOG) + снепшоты на уровне агрегата, а в случае SnapMirror это снепшоты снимаемые на уровне FlexVol (WAFL).
SnapMirror и SyncMirror легко могут сосуществовать друг с другом, так можно реплицировать данные с/на метро кластер из другой системы хранения с прошивкой ONTAP.
Memory и NVRAM
Для того чтобы обеспечить защиту данных от Split-Brain, данные которые поступают на запись попадают в NVRAM в виде логов (NVLOG) и в системную память. Подтверждение записи хосту придёт только после того, как они попадут в NVRAM одного локально контроллера, его соседа (если MCC состоит из 4 нод) и одного удалённого соседа. Синхронизация между локальными контроллерами выполняется через HA interconnect (это обычно внутренняя шина или иногда это внешнее подключение), а синхронизация на удалённую ноду выполняется через FC-IV порты. Локальный НА партнёр имеет только копию NVLOG, он не создаёт полной копии данных, ведь он и так видит диски с этими данными своего НА соседа. Удалённый DR партнёр имеет копию NVLOG и имеет полную копию всех данных (в Plex 1) на своих собственных дисках. Эта схема позволяет выполнять переключение в рамках сайта если второй контроллер HA пары уцелел или переключаться на второй сайт, если все локальные ноды хранилища вышли из строя. переключение на второй сайт происходит за пару секунд.
Эта схема позволяет выполнять переключение в рамках сайта если второй контроллер HA пары уцелел или переключаться на второй сайт, если все локальные ноды хранилища вышли из строя. переключение на второй сайт происходит за пару секунд.
На картинке показана схема для четырех-нодового метро кластера. Двух-нодовая схема аналогична, но не имеет локального НА партнёра. Восьми-нодовая схема это те же самые две четыре нодовые схемы: т.е. в такой конфигурации реплика NVRAM выполняется в рамках этих 4-х нод, а объединение двух таких четырех нодовых конфигураций позволяет прозрачно перемещать данные между нодами метро кластера в рамках каждого сайта.
NVRAM дополняет технологию SyncMirror: после поступления данных в NVRAM удалённого хранилища, сразу же поступает подтверждение записи, тоесть RAID приходит в полностью синхронное состояние на втором плексе с задержкой, при этом не скомпроментировав консистентность зеркальной копии — это позволяет существенно ускорить работу отклика при зеркалировании половинок метрокластера.
Tie Breaker witness
Для того, чтобы выполнить автоматическое переключение между двумя сайтами необходимо человеческое вмешательство или третий узел, так сказать свидетель всего происходящего, беспристрастный и всевидящий арбитр, который мог бы принять решение какой из сайтов должен остаться в живых после аварии, его называют TieBreaker. TieBreaker это или бесплатное ПО от NetApp для Windows Server или специализированное оборудование ClusterLion.
OnCommand Unified Manager (OCUM)
Если же TieBreaker не установлен, можно переключаться между сайтами в ручном режиме из бесплатной утилиты OnCommand Unified Manager (OCUM) или из командной строки при помощи команд metrocluster switchover.
All-Flash
MCC поддерживает All Flash FAS системы для конфигураций Fabric-Attached и Bridge-Attached Stretch MetroCluster, в них рекомендуется использовать бриджи ATTO 7500N FibreBridge.
FlexArray
Технология виртуализации FlexArray позволяет в качестве бек-энда использовать сторонние СХД, подключая их по протоколу FCP. Допускается не иметь родных полок с дисковыми полками производства NetApp. Сторонние СХД можно подключать через те же FC фабрики, что и для FC-VI подключения, это может существенно сэкономить деньги как на том что в схеме Fabric-Attached MetroCluster устраняется необходимость в FC-SAS бриджах, так и на том, что можно утилизировать существующие позволяя сохранить инвестиции за счёт утилизации старых систем хранения. Для работы FlexArray требуется чтобы такая система хранения была в матрице совместимости.
VMware vSphere Metro Storage Cluster
VMware может использовать с MCC для обеспечения HA на основе аппаратной репликации NetApp. Также, как и в случае с SRM/SRA это плагин для vCenter, который может взаимодействовать с MetroCluster TieBreaker для обеспечения автоматического переключения в случае аварии.
VMware VVOL
Технология VVOL поддерживается с vMSC.
Выводы
Технология MCC предназначена для создания высоко доступного хранилища и высоко доступных сервисов поверх него. Использование аппаратной репликации SyncMirror позволяет реплицировать очень крупные критические корпоративные инфраструктуры и в случае аварии автоматически или вручную переключаться между сайтами производя защиту от Split-Brain. MCC устроен таким образом, что для конечных хостов он выглядит как одно устройство, а переключение для хоста выполняется на уровне сетевой отказоустойчивости. Это позволяет интегрировать MCC практически с любым решением.
Здесь могут содержаться ссылки на Habra-статьи, которые будут опубликованы позже.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания, дополнения и вопросы по статье напротив, прошу в комментарии.
Развертывание узла кэша — Windows Deployment
- Статья
- Чтение занимает 8 мин
Область применения
- Windows 10
- Windows 11
Действия по развертыванию MCC
Чтобы развернуть MCC на сервере, выполните приведенные далее действия.
- Предоставьте корпорации Майкрософт идентификатор подписки Azure
- Создание ресурса MCC в Azure
- Создание узла MCC
- Изменение сведений об узле кэша
- Установка MCC на физическом сервере или виртуальной машине
- Проверка правильной работы сервера MCC
- При необходимости ознакомьтесь с распространенными проблемами .
По вопросам, касающимся этих инструкций, обращайтесь к [email protected]
Предоставьте корпорации Майкрософт идентификатор подписки Azure
В рамках процесса подключения предварительной версии MCC необходимо предоставить в корпорацию Майкрософт идентификатор подписки Azure.
Важно.
Пройдите этот опрос и укажите идентификатор подписки Azure и контактные данные, которые будут добавлены в список разрешений для этой предварительной версии. Вы не сможете продолжить работу, если пропустите этот шаг.
Сведения о создании или поиске идентификатора подписки см. в статье Действия по получению идентификатора подписки Azure.
Создание ресурса MCC в Azure
Портал управления Azure MCC используется для создания узлов MCC и управления ими. Идентификатор подписки Azure используется для предоставления доступа к предварительной версии и создания ресурса MCC в узлах Azure и кэша.
После того как вы проверите приведенный выше опрос и команда MCC добавит идентификатор подписки в список разрешений, вам будет предоставлена ссылка на портал Azure, где можно создать ресурс, описанный ниже.
На домашней странице портал Azure выберите Создать ресурс:
Введите Microsoft Connected Cache в поле поиска и нажмите клавишу ВВОД , чтобы отобразить результаты поиска.
Примечание.
Вы не увидите Microsoft Connected Cache в раскрывающемся списке. Вам потребуется ввести строку и нажать клавишу ВВОД, чтобы увидеть результат.
Выберите Microsoft Connected Cache Enterprise и нажмите кнопку Создать на следующем экране, чтобы начать процесс создания ресурса MCC.
Заполните обязательные поля для создания ресурса MCC.
Выберите подписку, которую вы предоставили корпорации Майкрософт.
Группы ресурсов Azure — это логические группы ресурсов. Создайте новую группу ресурсов и выберите имя для своей группы ресурсов.
Выберите (США) Западная часть США для расположения ресурса.
Этот выбор не повлияет на MCC, если физическое расположение находится не в западной части США, это просто ограничение предварительной версии.Важно.
Ресурс MCC будет создан неправильно, если не выбрать (США) западная часть США
Выберите имя ресурса MCC.
- Ресурс MCC не должен содержать слово Майкрософт .
После ввода всех сведений нажмите кнопку Проверить и создать . После завершения проверки нажмите кнопку Создать , чтобы начать создание ресурса.
 Этот выбор не повлияет на MCC, если физическое расположение находится не в западной части США, это просто ограничение предварительной версии.
Этот выбор не повлияет на MCC, если физическое расположение находится не в западной части США, это просто ограничение предварительной версии.Ошибка: сбой проверки
Создание узла MCC в Azure
Создание узла MCC — это многоэтапный процесс, и первым шагом является доступ к порталу управления ранней предварительной версии MCC.
После успешного создания ресурса выберите Перейти к ресурсу.
В разделе Управление узлами кэша на крайней левой панели выберите Узлы кэша.
В колонке Узлы кэша нажмите кнопку Создать узел кэша .
При нажатии кнопки Создать узел кэша откроется страница Создание узла кэша ; Имя узла кэша — это единственное поле, необходимое для создания узла кэша.
Имя поля Ожидаемое значение Описание Имя узла кэша Буквенно-цифровое имя, не включающее пробелы. Имя узла кэша. Вы можете выбрать имена в зависимости от расположения, например Seattle-1. Это имя должно быть уникальным и не может быть изменено позже.Введите сведения для узла кэша и нажмите кнопку Создать .
Если есть ошибки, форма предоставит рекомендации по исправлению ошибок.
После создания узла MCC будут предоставлены инструкции установщика. Дополнительные сведения о инструкциях по установке установщика будут рассмотрены позже в этой статье в разделе Установка подключенного кэша .
Дополнительные сведения о инструкциях по установке установщика будут рассмотрены позже в этой статье в разделе Установка подключенного кэша .
Изменение сведений об узле кэша
Узлы кэша можно удалить здесь, установив флажок слева от имени узла кэша , а затем выбрав элемент панели инструментов удаления. Имейте в виду, что при удалении узла кэша невозможно восстановить узел кэша или какие-либо сведения, связанные с узлом кэша.
Установка MCC в Windows
Установка MCC на устройстве с Windows — это простой процесс. Скрипт PowerShell выполняет следующие задачи:
- Устанавливает Azure CLI
- Скачивание, установка и развертывание EFLOW
- Включает Центр обновления Майкрософт, чтобы EFLOW могла оставаться в актуальном состоянии
- Создание виртуальной машины
- Включает брандмауэр и открывает порты 80 и 22 для входящего и исходящего трафика. Порт 80 используется MCC, а порт 22 используется для связи по протоколу SSH.
- Настраивает параметры настройки подключенного кэша.
- Создает необходимый бесплатный ресурс Azure — Центр Интернета вещей/IoT Edge.
- Развертывает контейнер MCC на сервере.
Запуск установщика
Скачайте и распакуйте
mccinstaller.zipстраницу создания узла кэша или страницу конфигурации узла кэша, оба из которых содержат необходимые файлы установки.В файле содержатся
mccinstaller.zipследующие файлы:- installmcc.ps1: основной файл установщика.
- installEflow.ps1: устанавливает необходимые компоненты, такие как виртуальная машина Linux, среда выполнения IoT Edge и Docker, а также устанавливает необходимые параметры ОС узла для оптимизации производительности кэширования.
- resourceDeploymentForConnectedCache.ps1. Создает облачные ресурсы Azure, необходимые для поддержки уровня управления MCC.
- mccdeployment. json: манифест развертывания, используемый IoT Edge для развертывания контейнера MCC и настройки параметров в контейнере, таких как размеры дисков кэша.
- updatemcc.ps1: скрипт обновления, используемый для обновления MCC до определенной версии.
- mccupdate.json: используется как часть скрипта обновления.
Откройте Windows PowerShell с правами администратора, а затем перейдите к расположению этих файлов.
Примечание.
Убедитесь, что на вашем устройстве включен Hyper-V.
- Windows 10:включение Hyper-V на Windows 10
- Windows Server:установка роли Hyper-V на Windows Server
Не используйте powerShell ISE, PowerShell 6.x или PowerShell 7.x. Поддерживается только Windows PowerShell версии 5.x.
Если вы устанавливаете MCC на локальной виртуальной машине, отключите виртуальнуюмашину, включив вложенную виртуализацию и спуфинг MAC.
Включите вложенную виртуализацию:
Set-VMProcessor -VMName "VM name" -ExposeVirtualizationExtensions $true
Включение спуфингов MAC:
Get-VMNetworkAdapter -VMName "VM name" | Set-VMNetworkAdapter -MacAddressSpoofing On
Задайте политику выполнения.
Set-ExecutionPolicy -ExecutionPolicy Unrestricted -Scope Process
Примечание.
После настройки политики выполнения появится предупреждение с запросом на изменение политики выполнения. Выберите [A] Да для всех.
Скопируйте команду из портал Azure и выполните ее в Windows PowerShell.
Примечание.
После выполнения команды и несколько раз на протяжении всего процесса установки вы получите следующее уведомление. Выберите [R] Выполнить один раз , чтобы продолжить. Предупреждение системы безопасности. Выполняйте только сценарии, которым вы доверяете. Хотя скрипты из Интернета могут быть полезны, этот скрипт может потенциально нанести вред вашему компьютеру.
Если вы доверяете этому скрипту, используйте командлет Unblock-File, чтобы разрешить выполнение скрипта без этого предупреждающего сообщения. Запустить C:\Users\mccinstaller\Eflow\installmcc.ps1?
[D] Не запускать [R] Выполнить один раз [S] Приостановить [?] Справка (по умолчанию — «D»):Укажите, нужно ли создать новый виртуальный коммутатор или выбрать существующий. Присвойте переключателю имя и выберите Сетевой адаптер, который будет использоваться для коммутатора. При создании нового коммутатора потребуется перезагрузка компьютера.
Примечание.
Рекомендуется перезагрузить компьютер после создания коммутатора. Если компьютер не был перезагружен, вы заметите задержки сети во время установки.
Если вы перезагрузили компьютер после создания параметра, начните с шага 2 выше и пропустите шаг 5.
Повторно запустите сценарий после перезапуска. На этот раз при запросе на создание нового параметра выберите Нет .
Введите номер, соответствующий ранее созданному коммутатору.Решите, хотите ли вы использовать динамический или статический адрес для виртуальной машины Eflow.
Примечание.
При выборе динамического IP-адреса может быть назначен другой IP-адрес при перезапуске MCC. Рекомендуется использовать статический IP-адрес, чтобы не изменять это значение в решении для управления при перезапуске MCC.
Выберите место, где вы хотите скачать, установить и сохранить виртуальный жесткий диск для EFLOW. Вам также будет предложено, сколько памяти, хранилища и сколько ядер вы хотите выделить для виртуальной машины. В этом примере мы выбрали значения по умолчанию для всех запросов.
Перейдите по ссылке Для входа на устройство Azure и войдите в портал Azure.
Если это первое развертывание MCC, выберите n, чтобы можно было создать новую Центр Интернета вещей. Если вы уже настроили MCC ранее, выберите y, чтобы сгруппировать mcCs в одну Центр Интернета вещей.
Отобразится список существующих Центров Интернета вещей в подписке Azure. Введите номер, соответствующий Центр Интернета вещей, чтобы выбрать его. Скорее всего, в вашей подписке будет только 1 Центр Интернета вещей. В этом случае вы хотите ввести «1»
Развертывание MCC завершено.
- Если вы не видите ошибок, перейдите к следующему разделу, чтобы проверить развертывание MCC. Виртуальная машина не будет отображаться в диспетчере Hyper-V, так как это виртуальная машина EFLOW.
- Проверив правильность работы MCC, ознакомьтесь с документацией по решению для управления, например Intune, чтобы задать для политики узла кэша IP-адрес вашего MCC.
- Если во время развертывания возникли ошибки, см. раздел Распространенные проблемы этой статьи.
 json: манифест развертывания, используемый IoT Edge для развертывания контейнера MCC и настройки параметров в контейнере, таких как размеры дисков кэша.
json: манифест развертывания, используемый IoT Edge для развертывания контейнера MCC и настройки параметров в контейнере, таких как размеры дисков кэша.
 Если вы доверяете этому скрипту, используйте командлет Unblock-File, чтобы разрешить выполнение скрипта без этого предупреждающего сообщения. Запустить C:\Users\mccinstaller\Eflow\installmcc.ps1?
[D] Не запускать [R] Выполнить один раз [S] Приостановить [?] Справка (по умолчанию — «D»):
Если вы доверяете этому скрипту, используйте командлет Unblock-File, чтобы разрешить выполнение скрипта без этого предупреждающего сообщения. Запустить C:\Users\mccinstaller\Eflow\installmcc.ps1?
[D] Не запускать [R] Выполнить один раз [S] Приостановить [?] Справка (по умолчанию — «D»): Введите номер, соответствующий ранее созданному коммутатору.
Введите номер, соответствующий ранее созданному коммутатору.
Проверка правильной работы сервера MCC
Проверка на стороне клиента
Подключитесь к виртуальной машине EFLOW и проверьте, правильно ли работает MCC:
Откройте PowerShell от имени администратора.
Введите следующие команды:
Connect-EflowVm sudo -s iotedge list
Вы увидите MCC, edgeAgent и edgeHub запущены. Если вы видите edgeAgent или edgeHub, но не MCC, попробуйте выполнить эту команду через несколько минут. Развертывание контейнера MCC может занять несколько минут.
Проверка на стороне сервера
Чтобы проверить правильность работы MCC, выполните следующую команду на виртуальной машине EFLOW или любом устройстве в сети. Замените <CacheServerIP> IP-адресом сервера кэша.
wget [http://<CacheServerIP>/mscomtest/wuidt.gif?cacheHostOrigin=au.download.windowsupdate.com]
В результате успешного теста отобразится код состояния 200 вместе с дополнительными сведениями.
Аналогичным образом введите следующий URL-адрес в браузере в сети:
http://<YourCacheServerIP>/mscomtest/wuidt.gif?cacheHostOrigin=au.download.windowsupdate.com
Если тест завершается сбоем, дополнительные сведения см. в разделе о распространенных проблемах .
в разделе о распространенных проблемах .
конфигурация Intune (или другого программного обеспечения для управления) для MCC
Для развертывания Intune создайте профиль конфигурации и добавьте IP-адрес или полное доменное имя узла кэша:
Общие проблемы
Проблемы с PowerShell
Если вы видите ошибки, аналогичные этой ошибке: The term Get-<Something> isn't recognized as the name of a cmdlet, function, script file, or operable program.
Убедитесь, что используется Windows PowerShell версии 5.x.
Запустите $PSVersionTable и убедитесь, что используется версия 5.x, а не версия 6 или 7.
Убедитесь, что у вас включен Hyper-V:
Windows 10:включение Hyper-V на Windows 10
Windows Server:установка роли Hyper-V на Windows Server
Проверка запуска контейнера MCC
Подключитесь к серверу подключенного кэша и проверьте список запущенных модулей IoT Edge с помощью следующих команд:
Connect-EflowVm sudo iotedge list
Если контейнеры edgeAgent и edgeHub указаны, но не «MCC», вы можете просмотреть состояние диспетчера безопасности IoT Edge с помощью команды :
sudo journalctl -u iotedge -f
Эта команда предоставит текущее состояние запуска, остановки контейнера или извлечения и запуска контейнера.
Примечание.
Вы должны ознакомиться с руководством по устранению неполадок IoT Edge (распространенные проблемы и решения для Azure IoT Edge) о любых проблемах, которые могут возникнуть при настройке IoT Edge, но мы перечислили несколько проблем, с которыми мы столкнулись во время внутренней проверки.
Коды торговых категорий (MCC): определение, цели, примеры
К
Юлия Каган
Полная биография
Джулия Каган — финансовый/потребительский журналист и бывший старший редактор отдела личных финансов Investopedia.
Узнайте о нашем редакционная политика
Обновлено 23 марта 2021 г.
Рассмотрено
Томас Брок
Рассмотрено Томас Брок
Полная биография
Томас Дж. Брок является CFA и CPA с более чем 20-летним опытом работы в различных областях, включая инвестиции, управление страховым портфелем, финансы и бухгалтерский учет, консультации по личным инвестициям и финансовому планированию, а также разработку учебных материалов. о страховании жизни и аннуитетах.
о страховании жизни и аннуитетах.
Узнайте о нашем Совет по финансовому обзору
Что такое коды категорий продавцов (MCC)?
Коды категорий продавцов (MCC) — это четырехзначные числа, которые эмитент кредитных карт использует для классификации транзакций, которые потребители совершают с использованием определенной карты. Платежные бренды используют коды категорий продавцов для классификации продавцов и предприятий по типу товаров или услуг, предоставляемых для отслеживания и ограничения транзакций.
Центры клиентов можно использовать для налоговой отчетности, продвижения обмена и сбора информации о покупательском поведении держателей карт.
Часто MCC признаются всеми эмитентами кредитных карт; однако не все коды распознаются всеми. Эмитенты часто добавляют, удаляют или изменяют коды с помощью регулярно запланированных улучшений.
Key Takeaways
- Коды категорий продавцов (MCC) — это четырехзначные числа, описывающие основную деятельность продавца.
- MCC используются эмитентами кредитных карт для определения типа бизнеса, которым занимается продавец.
- Центры клиентов используются для отслеживания покупательских привычек и распределения баллов по кредитным картам за квалифицированные покупки.

Коды категорий продавцов
Коды категорий продавцов имеют несколько целей. Они часто определяют вознаграждение, которое потребители получают за использование своих кредитных карт, и определяют, нужно ли сообщать о деловой операции в IRS. Кроме того, они определяют процент от каждой транзакции, который бизнес должен платить обработчику кредитной карты. В следующих примерах часто используются коды категорий продавцов.
- Если потребитель владеет кредитной картой, которая предлагает 5-процентный возврат на авиабилеты, он должен получить вознаграждение за любую покупку, которая классифицируется в соответствии с MCC 4511, который предназначен для авиакомпаний и авиаперевозчиков.
- Компании и государственные учреждения сообщают о приобретении услуг в IRS, чтобы IRS могло убедиться, что эти услуги уплачивают все причитающиеся подоходные налоги. Если предприятия совершают эти покупки с помощью кредитной карты, фирмы могут использовать Центр клиентов, чтобы определить, какие транзакции классифицируются как услуги.
- Предприятие, классифицируемое в соответствии с MCC для автозаправочных станций, иногда платит обработчику кредитных карт комиссионные сборы, отличные от комиссий, классифицируемых как компания по аренде автомобилей.
 Если предприятия совершают эти покупки с помощью кредитной карты, фирмы могут использовать Центр клиентов, чтобы определить, какие транзакции классифицируются как услуги.
Если предприятия совершают эти покупки с помощью кредитной карты, фирмы могут использовать Центр клиентов, чтобы определить, какие транзакции классифицируются как услуги.Как MCC могут повысить вознаграждение по кредитным картам
Владельцы бонусных карт обычно получают больше вознаграждений, если знают свои MCC. Предположим, у вас есть кредитная карта, которая дает 5 баллов за каждый доллар, потраченный в ресторане. Компания-эмитент кредитных карт определяет, проводились ли транзакции по кредитным картам в ресторане, просматривая MCC. Если вы покупаете обед в небольшом семейном заведении, которое сочетает в себе ресторан и продуктовый магазин, и MCC классифицирует это заведение как продуктовый магазин, вы не будете получать 5 баллов за 1 доллар США за то, что вы считали покупкой в ресторане. .
.
Однако, если вы часто посещаете это заведение и знаете связанный с ним MCC, вы можете использовать другую кредитную карту, возможно, ту, которая дает вам 3 процента возврата покупок в продуктовом магазине, чтобы максимизировать возврат наличных.
Другая возможность заключается в том, что эмитент кредитной карты не может предоставить вам правильное количество баллов или кэшбэк даже за транзакцию с MCC, которая должна активировать бонус. В этом случае вы можете связаться с компанией-эмитентом кредитной карты и попросить их исправить ошибку.
Чтобы узнать, как классифицируется транзакция, просто посмотрите выписку по кредитной карте. В разделе «категория» вы увидите, как компания кредитной карты классифицировала транзакцию. Вместо того, чтобы показывать MCC, в выписке обычно указывается название категории (например, «продуктовые магазины» или «аптеки»), чтобы вы могли легко понять информацию.
Примеры ЦУД
Ниже приведены некоторые MCC, связанные с поездками и транспортом, взятые из Citibank.
| Некоторые MCC Ситибанка для категории «Транспорт» (4000-47999) | |
|---|---|
| ЦУП | Описание |
| 4011 | Железные дороги — Грузовые перевозки |
| 4111 | Пригородные и местные пригородные пассажирские перевозки, включая паромы |
| 4112 | Пассажирские железные дороги |
| 4119 | Скорая помощь |
| 4121 | Такси и лимузины |
| 4131 | Автобусные линии |
| 4214 | Автомобильные грузовые перевозчики, Автоперевозки, Перевозка и хранение, Местная доставка |
| 4215 | Курьерские службы и наземные экспедиторы |
| 4225 | Складирование или хранение сельскохозяйственных продуктов, охлажденных продуктов и бытовых товаров |
| 4411 | Круизные линии |
| 4457 | Аренда и прокат лодок |
| 4468 | Марины и морские службы/принадлежности |
| 4511 | Авиакомпании/Авиаперевозчики |
| 4582 | Аэропорты, Аэровокзалы |
| 4722 | Туристические агентства, туроператоры |
| 4784 | Мостовые и дорожные сборы и сборы |
Источники статей
Investopedia требует, чтобы авторы использовали первоисточники для поддержки своей работы. К ним относятся официальные документы, правительственные данные, оригинальные отчеты и интервью с отраслевыми экспертами. Мы также при необходимости ссылаемся на оригинальные исследования других авторитетных издателей. Вы можете узнать больше о стандартах, которым мы следуем при создании точного и беспристрастного контента, в нашем
редакционная политика.
К ним относятся официальные документы, правительственные данные, оригинальные отчеты и интервью с отраслевыми экспертами. Мы также при необходимости ссылаемся на оригинальные исследования других авторитетных издателей. Вы можете узнать больше о стандартах, которым мы следуем при создании точного и беспристрастного контента, в нашем
редакционная политика.
https://www.citibank.com/tts/solutions/commercial-cards/assets/docs/govt/Merchant-Category-Codes.pdf
О ЦУП
Это MCC
Узнайте, как MCC работает со странами-партнерами, чтобы способствовать росту, помогать людям выбраться из бедности и инвестировать в будущие поколения.
Корпорация «Вызовы тысячелетия» (MCC) — это инновационное и независимое агентство США по оказанию помощи иностранным государствам, которое помогает вести борьбу с глобальной бедностью.
Созданная Конгрессом США в январе 2004 г. при сильной поддержке обеих партий, MCC изменила ход разговора о том, как лучше всего оказывать разумную помощь США иностранным государствам, сосредоточив внимание на правильной политике, ответственности страны и результатах. MCC предоставляет ограниченные по времени гранты, способствующие экономическому росту, сокращению бедности и укреплению институтов. Эти инвестиции не только поддерживают стабильность и процветание в странах-партнерах, но и укрепляют американские интересы. Благодаря рентабельным проектам, небольшому персоналу и основанному на фактических данных подходу MCC является хорошей инвестицией для американского народа.
В чем особенность MCC?
MCC устанавливает партнерские отношения с развивающимися странами, которые привержены принципам надлежащего управления, экономической свободы и инвестирования в своих граждан. MCC является ярким примером разумной помощи правительства США в действии, приносящей пользу как развивающимся странам, так и американским налогоплательщикам через:
- Конкурсный отбор : Совет MCC изучает эффективность страны по 20 независимым и прозрачным показателям политики и выбирает страны на основе эффективности политики.
- Решения под руководством страны : MCC требует, чтобы выбранные страны определили свои приоритеты для достижения устойчивого экономического роста и сокращения бедности. Страны разрабатывают свои предложения MCC в ходе широких консультаций со своим обществом. Затем MCC работает в тесном сотрудничестве, чтобы помочь странам усовершенствовать программы.
- Внедрение под руководством страны : Когда страна получает договор MCC, она создает местную подотчетную организацию для управления и надзора за всеми аспектами реализации. Мониторинг средств является строгим, прозрачным и часто управляется независимыми фискальными агентами.
- Сосредоточьтесь на результатах : MCC стремится добиваться результатов и гарантировать, что американцы получат хорошую отдачу от своих инвестиций. MCC применяет технически строгие, систематические и прозрачные методы проектирования, отслеживания и оценки воздействия своих программ.
Гранты MCC предназначены для дополнения других американских и международных программ развития, а также для создания благоприятной среды для инвестиций частного сектора. Существует три основных типа грантов MCC:
- Компакты — крупные пятилетние гранты для отдельных стран, отвечающих критериям приемлемости MCC
- Параллельные договоры для региональных инвестиций — гранты, которые продвигают трансграничную экономическую интеграцию и расширяют региональную торговлю и сотрудничество
- Пороговые программы — гранты меньшего размера, ориентированные на политические и институциональные реформы в отдельных странах, которые близки к соответствию критериям приемлемости MCC и демонстрируют твердую приверженность повышению эффективности своей политики
Что делает MCC?
Проекты MCC решают некоторые из самых насущных проблем, с которыми сталкиваются люди в развивающихся странах, такие как поставка электроэнергии, чтобы предприятия могли работать, а студенты могли учиться после наступления темноты; обеспечение чистой питьевой водой, чтобы женщинам не приходилось преодолевать большие расстояния — иногда с большим личным риском — за водой для своих семей; и строительство дорог, чтобы фермеры могли доставлять свои товары на рынок, а дети могли добраться до школы.