
СЕТЕВЫЕ ТРАНСФОРМАТОРЫ ПРОСТЫМИ СЛОВАМИ
Добрый день новички, решил сегодня поговорить о трансформаторах напряжения, о принципе их работы и и области применения. Без трансформатора в электронике никак не обойтись. В бытовых приборах в основном используются понижающие трансформаторы. Все мы отлично знаем, что напряжение бытовой сети составляет 220 вольт 50 герц. С вольтажом думаю все понятно, а вот с частотой могут возникнуть вопросы. Что значит частота 50 герц? Источники переменного тока имеют определенную частоту от долей сотен килогерц и выше. Частота 50 герц означает, что электрический ток меняет свое направление и величину 50 раз за одну секунду, и сетевые трансформаторы работают именно на такой частоте.
Трансформатор состоит из двух обмоток: первичная – в которую подается напряжение и вторичная из которого выходит уже то напряжение, на которое расчитан трансформатор. Сетевые трансформаторы могут понижать и повышать номинал входного напряжения и силы тока.
Сила тока зависит от диаметра вторичной обмотки трансформатора, а величина напряжения – от количества витков этой же обмотки. Обе обмотки намотаны на железном сердечке, в первичную обмотку подается напряжение, методом индукции во вторичной обмотке образуется ток. Первичная и вторичная обмотка не связаны друг с другом.
Трансформаторы бывают разных мощностей от нескольких ватт до сотен киловатт. Трансформаторы используют повсюду для изменения величины и тока напряжения.
Есть также импульсные источники питания, где трансформатор работает на частоте в несколько килогерц, а такую частоту обеспечивает специальный генератор который называют задающим генератором. Такие блоки питания вошли в моду в последние 10-20 лет и уже незаменимы по этой линии, применяются повсюду, в блоках питания телевизоров, компьютеров, двд проигрывателей и во многом другом.
Такие источники питания отличаются малыми размерами большей выходной мощностью. Тут трансформатор работает тем же принципом, только вместо железного сердечника применен в основном ферромагнитный сердечник (феррит) который работает на высокой частоте, именно благодаря высокой частоте трансформатор имеет маленькие размеры, а трансформаторы с железным сердечником работают на частоте 50 герц (оптимальная частота).
Тут трансформатор работает тем же принципом, только вместо железного сердечника применен в основном ферромагнитный сердечник (феррит) который работает на высокой частоте, именно благодаря высокой частоте трансформатор имеет маленькие размеры, а трансформаторы с железным сердечником работают на частоте 50 герц (оптимальная частота).
Есть также трансформаторы в которых сердечник отсутствует – это трансформаторы свободных колебаний, в число таких трансформаторов входит трансформатор Теслы, более известный как катушка Теслы.
Трансформаторы могут иметь несколько вторичных обмоток для получения напряжения разных номиналов но суть одна – повышение или понижение начального напряжения. В данной статье не привожу расчетов и сложных формул, главное – это понять принцип действия. Спасибо за внимание – Ака.
Форум по радиоэлементам
TSZSW20-001M за 1 739.52 ₽ в наличии производства INDEL
Купить Трансформатор сетевой 20ВА TSZSW20-001M производителя INDEL можно оптом и в розницу с доставкой по всей России, Казахстану, Республике Беларусь и Украине, а так же в другие страны Таможенного союза (Армения, Киргизия и др.
Для того, чтобы купить данный товар по базовой цене в розницу, положите его в корзину и оформите заказ следуя детальной инструкции. Обращаем Ваше внимание, что в зависимости от увеличения объёма продукции перерасчёт розничной цены будет произведен автоматически. Оптовая цена на трансформатор сетевой 20ва 230вac 12в TSZSW20-001M выставляется исключительно после отправки коммерческого запроса на e-mail: [email protected] или [email protected].
- Более подробная информация находится в разделе Оплата.
Мы работаем со всеми крупными транспортными компаниями и гарантируем оперативность и надежность каждой поставки независимо от региона присутствия заказчика. Данный товар так же поставляются с различных складов Европы, Китая и США. Возможные варианты поставки запрашивайте у специалистов компании SUPPLY24.ONLINE.
- Более подробная информация находится в разделе Доставка.
Гарантия предоставляется непосредственно заводом-изготовителем INDEL . Гарантийный ремонт или замена оборудования осуществляется исключительно после проведения экспертизы и установления факта гарантийного случая.
Гарантийный ремонт или замена оборудования осуществляется исключительно после проведения экспертизы и установления факта гарантийного случая.
- Более подробная информация находится в разделах Гарантия и Условия Гарантийных Обязательств.
Трансформаторы с креплением практически всех известных мировых брендов представлены нашей компанией. В случае если интересующий Вас товар не был найден на нашем сайте, обратитесь в службу технической поддержки или обслуживающему Вас менеджеру и наши инженеры подберут аналоги для Вашего оборудования. Таким образом, возможно снизить затраты до 20% на обслуживание оборудования и оптимизировать Ваши расходы. Компания SUPPLY24.ONLINE берёт на себя полную ответственность за правильность подбора аналога. Наша компания предлагает только разумный подход, если по ряду критериев запрашиваемый товар не подразумевает замену на аналог, мы не предлагаем замену.

Внимание!
- Характеристики,внешний вид и комплектация товара могут изменяться производителем без уведомления.
- Изображение продукции дано в качестве иллюстрации для ознакомления и может быть изменено без уведомления.
- Точную спецификацию смотрите во вкладке «Характеристики» .
- При необходимости установки программного обеспечения и использования аксессуаров сторонних производителей, просьба проверить их совместимость с устройством, детально изучив документацию на сайте производителя INDEL
- Запрещается нарушение заводских настроек и регулировок без привлечения специалистов сертифицированных сервисных центров.
Характеристики
Производитель
Выводы
клеммная колодка
Монтаж
Мощность
Защита
предохранитель
0,55кг
Тип трансформатора
сетевой
Напряжение первичной обмотки
230В AC
Вторичное напряжение 1
Ток вторичной обмотки 1
ДОСТАВКА ПО РОССИИ
Доставка осуществляется в течении 2-3 дней с момента зачисления средств на р/с компании при наличии товара на складе в РФ. В отдельных случаях, при большой удаленности Вашего региона, срок доставки может быть увеличен.
В отдельных случаях, при большой удаленности Вашего региона, срок доставки может быть увеличен.
- Полный перечень городов, в которые осуществляется доставка, смотрите ниже.
ДОСТАВКА В СТРАНЫ ТАМОЖЕННОГО СОЮЗА
Доставка осуществляется в течении 3-5 дней с момента зачисления средств на р/с компании в следующие страны.
- Казахстан
- Армения
- Беларусь
- Киргизия
В случае, если выбранные товарные позиции находятся на одном из внешних складов Европы или США, то срок доставки товара может составлять до 3-4 недель. Для избежания недоразумений, рекомендуем уточнить актуальные сроки поставки в отделе логистики или у менеджера компании.
В данном случае, как правило, 90% заказов доставляются заказчикам в течении первых 2 недель.
Если какая-либо часть товара из Вашего заказа отсутствует на складе, мы отгрузим все имеющиеся в наличии товары, а после поступления с внешнего склада оставшейся части заказа отправим Вам её за счёт нашей компании.
ОФИСЫ ВЫДАЧИ ТОВАРА:
Доставка до ТК осуществляется бесплатноCКЛАДЫ
Нейронные сети-трансформеры: пошаговое описание
Нейронная сеть-трансформер представляет собой новую архитектуру, предназначенную для решения последовательных задач при одновременном легком управлении долговременными зависимостями. Впервые это было предложено в статье «Внимание — это все, что вам нужно», и теперь это современная техника в области НЛП.
Прежде чем перейти к трансформаторной сети, я объясню, почему мы ее используем и откуда она взялась. Итак, история начинается с RNN, что означает рекуррентные нейронные сети.
Что такое нейронная сеть трансформатора?
Нейронная сеть-трансформер представляет собой новую архитектуру, предназначенную для решения последовательных задач, с легкостью обрабатывая долгосрочные зависимости. Впервые это было предложено в статье «Внимание — это все, что вам нужно». и в настоящее время является передовой техникой в области НЛП.
Подробнее об искусственном интеллектеЧто такое глубокое обучение и как оно работает?
RNN
Что такое RNN? Чем она отличается от простой искусственной нейронной сети (ИНС)? В чем основная разница?
RNN — это нейронные сети с прямой связью, развертываемые с течением времени.
Источник: Блог КолахаВ отличие от обычных нейронных сетей, RNN предназначены для получения серии входных данных без заранее определенного ограничения на размер. Термин «серия» здесь означает, что каждый вход этой последовательности имеет некоторую связь со своими соседями или оказывает на них некоторое влияние.
Архитектура RNN. | Источник: Блог КолахаБазовые сети прямой связи тоже «помнят» что-то, но они помнят то, чему научились во время обучения. Хотя RNN учатся аналогичным образом во время обучения, они также запоминают то, что узнали из предыдущих входных данных, при создании выходных данных.
Изображение, иллюстрирующее долгосрочные зависимости.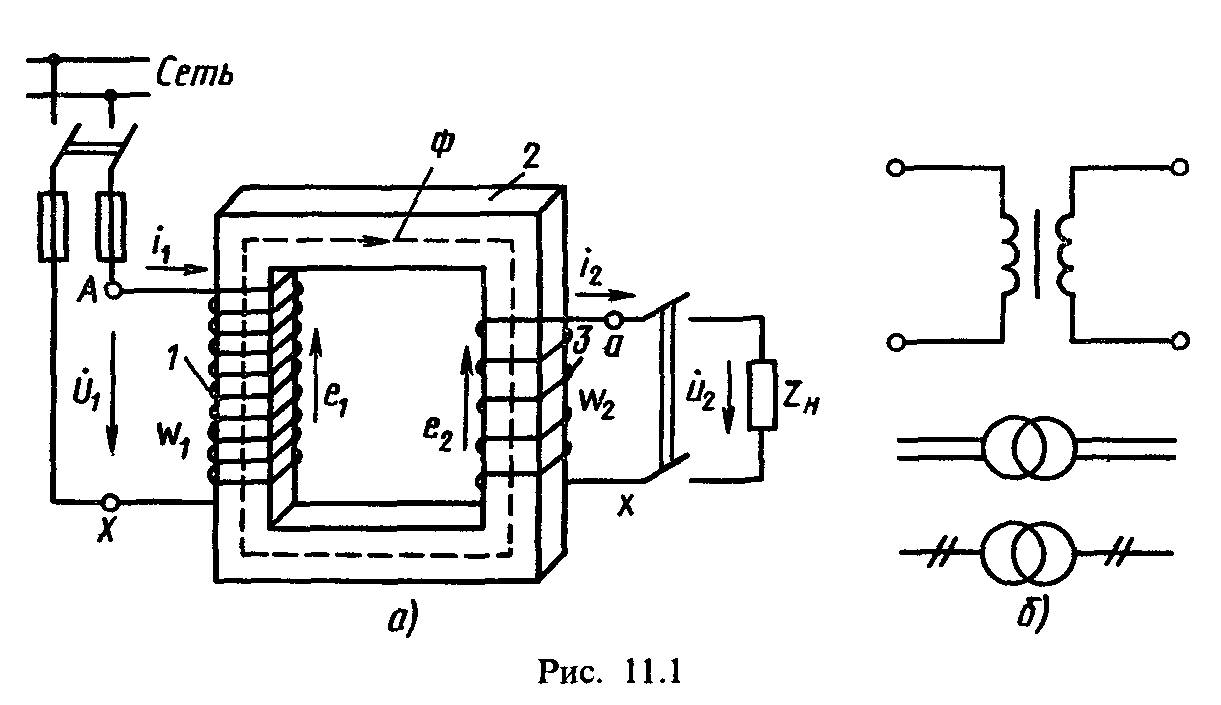 | Источник: Блог Колы
| Источник: Блог КолыRNN можно использовать в нескольких типах моделей.
1. Модели векторной последовательности — Берут векторы фиксированного размера в качестве входных и выходных векторов любого размера. Например, в подписи к изображению изображение является входом, а выход описывает изображение.
2. Модель вектора последовательности — Возьмите вектор любого размера и выведите вектор фиксированного размера. Например, анализ тональности фильма оценивает рецензию на любой фильм, положительную или отрицательную, как вектор фиксированного размера.
3. Модель «последовательность за последовательностью» — Самый популярный и наиболее часто используемый вариант, который принимает последовательность в качестве входных данных и выводит другую последовательность с вариантными размерами. Примером этого является языковой перевод данных временных рядов для прогнозирования фондового рынка.
Однако RNN имеет два основных недостатка:
- Медленно обучается.

- Длинные последовательности приводят к исчезающему градиенту или проблеме долговременных зависимостей. Проще говоря, его память не так сильна, когда дело доходит до воспоминаний о старых связях.

Например, в предложении «Облака в ____». следующим словом, очевидно, должно быть небо, так как оно связано с облаками. Если расстояние между облаками и предсказанным словом короткое, RNN может легко его предсказать.
Рассмотрим, однако, другой пример: «Я вырос в Германии с моими родителями, я провел там много лет и хорошо знаю их культуру. Вот почему я бегло говорю ____».
Здесь предсказанное слово — немецкое, что напрямую связано с Германией. Однако в этом случае расстояние между Германией и предсказанным словом больше, поэтому RNN трудно предсказать.
Так что, к сожалению, по мере того, как этот разрыв увеличивается, RNN становятся неспособными к соединению, поскольку их память тускнеет с расстоянием.
Долгая кратковременная память
Источник: блог Колаха Долгая кратковременная память — это особый вид RNN, специально созданный для решения задач исчезающего градиента. Они способны изучать долгосрочные зависимости. На самом деле запоминание информации в течение длительного периода времени практически является их поведением по умолчанию, а не тем, чему они изо всех сил пытаются научиться!
Они способны изучать долгосрочные зависимости. На самом деле запоминание информации в течение длительного периода времени практически является их поведением по умолчанию, а не тем, чему они изо всех сил пытаются научиться!
Нейроны LSTM, в отличие от обычной версии, имеют ветвь, которая позволяет передавать информацию, чтобы пропустить долгую обработку текущей ячейки. Эта ветвь позволяет сети сохранять память в течение более длительного периода времени. Это решает проблему исчезающего градиента, но не очень хорошо: он будет работать нормально до 100 слов, но около 1000 слов он начинает терять свою хватку.
Кроме того, как и простой RNN, он также очень медленно обучается, а возможно, даже медленнее. Эти системы принимают ввод последовательно один за другим, что не очень хорошо использует графические процессоры, которые предназначены для параллельных вычислений. Позже я расскажу, как мы можем распараллелить последовательные данные. На данный момент мы имеем дело с двумя проблемами:
Позже я расскажу, как мы можем распараллелить последовательные данные. На данный момент мы имеем дело с двумя проблемами:
- Исчезающий градиент
- Медленное обучение
Решение проблемы исчезающего градиента
Внимание отвечает на вопрос о том, на какой части ввода мы должны сосредоточиться. Я собираюсь объяснить внимание с помощью гипотетического сценария:
Предположим, кто-то дал нам книгу по машинному обучению и попросил собрать всю информацию о категориальной кросс-энтропии. Есть два способа выполнения такой задачи. Во-первых, мы могли бы прочитать всю книгу и вернуться с ответом. Во-вторых, мы могли бы перейти к указателю, найти главу о потерях, перейти к кросс-энтропийной части и просто прочитать соответствующую информацию о категориальной кросс-энтропии.
Как вы думаете, какой метод быстрее?
Первый подход может занять целую неделю, а второй — всего несколько минут. Кроме того, наши результаты первого метода будут более расплывчатыми и содержат слишком много информации. Второй подход более точно удовлетворит требованию.
Второй подход более точно удовлетворит требованию.
Что мы здесь сделали по-другому?
В первом случае мы не остановились ни на одной части книги. Однако в последнем методе мы сосредоточили наше внимание на главе о потерях и, более конкретно, на той части, где объясняется концепция категориальной кросс-энтропии. Эта вторая версия — способ, которым большинство из нас, людей, на самом деле выполнило бы эту задачу.
Внимание в нейронных сетях чем-то похоже на то, что мы наблюдаем у людей. Это означает, что они сосредотачиваются на определенных частях входных данных, в то время как остальным уделяется меньше внимания.
Допустим, мы делаем NMT (нейронный машинный переводчик). Эта анимация показывает, как работает простая модель seq-to-seq.
Мы видим, что для каждого шага кодера или декодера RNN обрабатывает свои входные данные и генерирует выходные данные для этого временного шага. На каждом временном шаге RNN обновляет свое скрытое состояние на основе входных и предыдущих выходных данных, которые он видел. В анимации мы видим, что скрытое состояние на самом деле является вектором контекста, который мы передаем декодеру.
В анимации мы видим, что скрытое состояние на самом деле является вектором контекста, который мы передаем декодеру.
Время для внимания
Вектор контекста оказывается проблематичным для этих типов моделей, которые испытывают затруднения при работе с длинными предложениями. Или они, возможно, столкнулись с проблемой исчезающего градиента в длинных предложениях. Итак, решение появилось в статье, которая привлекла внимание. Это значительно улучшило качество машинного перевода, поскольку позволяет модели сосредоточиться на соответствующей части входной последовательности по мере необходимости.
Эта модель внимания отличается от классической последовательной модели двумя способами. Во-первых, по сравнению с простой последовательной моделью, здесь кодер передает гораздо больше данных декодеру. Раньше в декодер посылалось только конечное, скрытое состояние кодирующей части, а теперь кодировщик пропускает все скрытые состояния, даже промежуточные.
Часть декодера также выполняет дополнительный шаг перед созданием своего вывода.![]() Этот шаг выполняется следующим образом:
Этот шаг выполняется следующим образом:
- Он проверяет каждое полученное скрытое состояние, поскольку каждое скрытое состояние кодировщика в основном связано с конкретным словом входного предложения.
- Каждому скрытому состоянию присваивается оценка.
- Каждая оценка умножается на соответствующую оценку softmax, таким образом усиливая скрытые состояния с высокими оценками и заглушая скрытые состояния с низкими оценками. Здесь доступна четкая визуализация.
Это упражнение по подсчету очков происходит на каждом временном шаге на стороне декодера.
Теперь, когда мы собираем все это вместе:
- Уровень декодера внимания принимает встраивание токена
и начальное скрытое состояние декодера. RNN обрабатывает свои входные данные и создает выходные данные и новый скрытый вектор состояния (h5). - Теперь мы используем скрытые состояния кодировщика и вектор h5 для вычисления контекстного вектора C4 для этого временного шага. Именно здесь применяется концепция внимания, дав ей название шага внимания.
- Мы объединяем (h5) и C4 в один вектор.
- Теперь этот вектор передается в нейронную сеть с прямой связью. Выход нейронных сетей прямой связи указывает выходное слово этого временного шага.
- Эти шаги повторяются для следующих временных шагов. Здесь доступна четкая визуализация.
Итак, вот как работает внимание. Для дальнейшего разъяснения вы можете увидеть его применение к проблеме с субтитрами к изображениям здесь.
Помните, ранее я упоминал о распараллеливании последовательных данных? А вот и наши боеприпасы для этого.
Подробнее в AIПочему автоматизация превратит великую отставку в великую модернизацию
Трансформеры
авторы назвали трансформером.
Одно из основных отличий состоит в том, что входную последовательность можно передавать параллельно, что позволяет эффективно использовать графический процессор и увеличить скорость обучения. Он также основан на многоголовом слое внимания, поэтому он легко преодолевает проблему исчезающего градиента. В статье трансформатор применяется к NMT.
Он также основан на многоголовом слое внимания, поэтому он легко преодолевает проблему исчезающего градиента. В статье трансформатор применяется к NMT.
Итак, обе проблемы, о которых мы говорили ранее, здесь частично решены.
Например, в переводчике, состоящем из простой RNN, мы непрерывно вводим нашу последовательность или предложение, по одному слову за раз, для создания встраивания слов. Поскольку каждое слово зависит от предыдущего слова, его скрытое состояние действует соответствующим образом, поэтому мы должны вводить его шаг за шагом.
Однако в преобразователе мы можем передать все слова предложения и одновременно определить вложение слова. Итак, давайте посмотрим, как это работает на самом деле:
Источник: arXiv:1706.03762
Блок кодировщика
Источник: arXiv:1706.03762 Компьютеры не понимают слов. Вместо этого они работают с числами, векторами или матрицами. Итак, нам нужно преобразовать наши слова в вектор. Но как это возможно? Вот где в игру вступает концепция встраивания пространства. Это как открытое пространство или словарь, где сгруппированы слова с похожими значениями. Это называется пространством вложения, и здесь каждое слово, в соответствии с его значением, отображается и ему присваивается определенное значение. Таким образом, мы конвертируем наши слова в векторы.
Это как открытое пространство или словарь, где сгруппированы слова с похожими значениями. Это называется пространством вложения, и здесь каждое слово, в соответствии с его значением, отображается и ему присваивается определенное значение. Таким образом, мы конвертируем наши слова в векторы.
Еще одна проблема, с которой мы столкнемся, заключается в том, что в разных предложениях каждое слово может иметь разные значения. Итак, чтобы решить эту проблему, мы используем позиционные энкодеры. Это векторы, которые задают контекст в соответствии с положением слова в предложении.
Word → Встраивание → Позиционное встраивание → Конечный вектор, оформленный как Контекст.
Итак, теперь, когда наш ввод готов, он поступает в блок энкодера.
Мультиголовка Внимание, часть
Источник: arXiv:1706.03762Теперь самое главное в трансформере: внимание к себе.
Это фокусируется на том, насколько релевантно конкретное слово по отношению к другим словам в предложении. Он представлен в виде вектора внимания. Для каждого слова мы можем создать сгенерированный вектор внимания, который фиксирует контекстуальные отношения между словами в этом предложении.
Он представлен в виде вектора внимания. Для каждого слова мы можем создать сгенерированный вектор внимания, который фиксирует контекстуальные отношения между словами в этом предложении.
Единственная проблема сейчас заключается в том, что для каждого слова оно имеет намного большее значение, чем само по себе в предложении, но мы хотим знать его взаимодействие с другими словами этого предложения. Итак, мы определяем несколько векторов внимания для каждого слова и берем средневзвешенное значение, чтобы вычислить окончательный вектор внимания для каждого слова.
Поскольку мы используем несколько векторов внимания, этот процесс называется блоком внимания с несколькими головками.
Сеть прямой связи
Источник: arXiv:1706.03762 Теперь второй шаг — нейронная сеть прямой связи. Простая нейронная сеть с прямой связью применяется к каждому вектору внимания для преобразования векторов внимания в форму, приемлемую для следующего уровня кодера или декодера.
Сеть прямой связи принимает векторы внимания по одному. И самое лучшее здесь то, что, в отличие от RNN, каждый из этих векторов внимания не зависит друг от друга. Итак, здесь мы можем применить распараллеливание, и в этом вся разница.
Выход энкодера. | Источник: arXiv:1706.03762Теперь мы можем передавать все слова одновременно в блок кодировщика и одновременно получать набор закодированных векторов для каждого слова.
Блок декодера
Источник: arXiv:1706.03762Теперь, если мы обучаем переводчика с английского на французский, для обучения нам нужно дать английское предложение вместе с его переведенной французской версией, чтобы модель могла научиться. Итак, наши английские предложения проходят через блок кодировщика, а французские предложения проходят через блок декодера.
Источник: arXiv:1706.03762 Во-первых, у нас есть слой внедрения и часть позиционного кодировщика, которая превращает слова в соответствующие векторы. Это похоже на то, что мы видели в части кодировщика.
Это похоже на то, что мы видели в части кодировщика.
Маскированная многоголовая часть внимания
Источник: arXiv:1706.03762Теперь он пройдет через блок самоконтроля, где векторы внимания генерируются для каждого слова во французских предложениях, чтобы представить, насколько каждое слово связано к каждому слову в одном предложении, как мы видели в части кодировщика.
Но этот блок называется замаскированным многоголовым блоком внимания, который я объясню простыми словами. Во-первых, нам нужно знать, как работает механизм обучения. Когда мы предоставляем английское слово, оно будет переведено на французский язык с использованием предыдущих результатов. Затем он сопоставляется и сравнивается с фактическим французским переводом, который мы ввели в блок декодера. После сравнения обоих он обновит значение своей матрицы. Вот как он научится после нескольких итераций.
Мы наблюдаем, что нам нужно скрыть следующее французское слово, чтобы сначала оно само предсказывало следующее слово, используя предыдущие результаты, не зная реального переведенного слова. Для обучения не было бы смысла, если бы он уже знал следующее французское слово. Поэтому нам нужно его скрыть (или замаскировать).
Для обучения не было бы смысла, если бы он уже знал следующее французское слово. Поэтому нам нужно его скрыть (или замаскировать).
Мы можем взять любое слово из английского предложения, но для обучения мы можем взять только предыдущее слово из французского предложения. Итак, выполняя распараллеливание с матричной операцией, нам нужно убедиться, что матрица будет маскировать слова, появляющиеся позже, преобразовывая их в нули, чтобы сеть внимания не могла их использовать.
Источник: arXiv:1706.03762Теперь результирующие векторы внимания из предыдущего уровня и векторы из блока кодировщика передаются в другой блок внимания с несколькими головками. Здесь также появляются результаты блока кодировщика. На схеме сюда же явно приходят результаты работы блока энкодера. Вот почему он называется блоком внимания кодер-декодер.
Поскольку у нас есть один вектор каждого слова для каждого английского и французского предложений, этот блок фактически выполняет сопоставление английских и французских слов и выясняет отношения между ними. Итак, это та часть, где происходит основное сопоставление английских и французских слов.
Итак, это та часть, где происходит основное сопоставление английских и французских слов.
Результатом этого блока являются векторы внимания для каждого слова в английских и французских предложениях. Каждый вектор представляет связь с другими словами в обоих языках.
Источник: arXiv:1706.03762Теперь, если мы передадим каждый вектор внимания в модуль прямой связи, он придаст выходным векторам форму, которая будет легко принята другим блоком декодера или линейным уровнем. Линейный слой — это еще один уровень прямой связи, который расширяет измерения до количества слов на французском языке после перевода.
Теперь оно проходит через слой softmax, который преобразует входные данные в распределение вероятностей, которое может быть интерпретировано человеком, и результирующее слово создается с наибольшей вероятностью после перевода.
Вот пример из блога Google AI. В анимации преобразователь начинает с создания начальных представлений или вложений для каждого слова, представленного незакрашенными кружками. Затем, используя само-внимание, он собирает информацию из всех других слов, создавая новое представление для каждого слова, основанное на всем контексте, представленном закрашенными шариками. Затем этот шаг повторяется несколько раз параллельно для всех слов, последовательно создавая новые представления.
Затем, используя само-внимание, он собирает информацию из всех других слов, создавая новое представление для каждого слова, основанное на всем контексте, представленном закрашенными шариками. Затем этот шаг повторяется несколько раз параллельно для всех слов, последовательно создавая новые представления.
Декодер работает аналогично, но генерирует по одному слову слева направо. Он обращает внимание не только на другие ранее сгенерированные слова, но и на окончательные представления, сгенерированные кодировщиком.
Более интеллектуальный мирВы уверены, что можете доверять этому ИИ?
Вывод
Итак, вот как работает преобразователь, и теперь это современная техника НЛП. Его результаты с использованием механизма самоконтроля являются многообещающими, и он также решает проблему распараллеливания. Даже Google использует BERT, который использует преобразователь для предварительной подготовки моделей для распространенных приложений НЛП.
Как работают трансформаторы.
 Трансформеры — это тип нейронных… | by Giuliano Giacaglia
Трансформеры — это тип нейронных… | by Giuliano GiacagliaНейронная сеть, используемая Open AI и DeepMind
Giuliano Giacaglia
·Follow
Published in·
14 min читать·
11 марта 2019Если вам понравилось этот пост и хотите узнать, как работают алгоритмы машинного обучения, как они возникли и куда идут, я рекомендую следующее:
Заставить вещи думать: как искусственный интеллект и глубокое обучение улучшают продукты, которые мы используем — Холлоуэй
Это очевидное, что так трудно увидеть большую часть времени. Люди говорят: «Это так же просто, как нос на вашем лице».…
www.holloway.com
Трансформеры — это тип архитектуры нейронной сети, который набирает популярность. Трансформеры недавно использовались OpenAI в своих языковых моделях, а также недавно использовались DeepMind для AlphaStar — их программы для победы над лучшим профессиональным игроком в Starcraft.
Преобразователи были разработаны для решения проблемы преобразования последовательности , или нейронного машинного перевода. Это означает любую задачу, которая преобразует входную последовательность в выходную последовательность. Это включает в себя распознавание речи, преобразование текста в речь и т. д.
Это означает любую задачу, которая преобразует входную последовательность в выходную последовательность. Это включает в себя распознавание речи, преобразование текста в речь и т. д.
Для моделей, выполняющих трансдукцию последовательности , надо иметь какую то память. Например, предположим, что мы переводим следующее предложение на другой язык (французский):
«Трансформеры» — японская [[хардкор-панк]] группа. Группа была создана в 1968 году, на пике истории японской музыки».
В этом примере слово «группа» во втором предложении относится к группе «Трансформеры», представленной в первом предложении. Когда вы читаете о группе во втором предложении, вы знаете, что это относится к группе «Трансформеры». Это может быть важно для перевода. Есть много примеров, когда слова в некоторых предложениях относятся к словам в предыдущих предложениях.
Для перевода таких предложений модель должна определить такого рода зависимости и связи. Рекуррентные нейронные сети (RNN) и сверточные нейронные сети (CNN) использовались для решения этой проблемы из-за их свойств. Давайте рассмотрим эти две архитектуры и их недостатки.
Рекуррентные нейронные сети содержат петли, позволяющие сохранять информацию.
Вход представлен как x_tНа рисунке выше мы видим часть нейронной сети, A, обрабатывает некоторые входные данные x_t и выводит h_t. Цикл позволяет передавать информацию от одного шага к другому.
Циклы можно представить по-разному. Рекуррентную нейронную сеть можно рассматривать как несколько копий одной и той же сети, A , каждая сеть передает сообщение преемнику. Рассмотрим, что произойдет, если развернуть цикл:
Развернутая рекуррентная нейронная сеть Эта цепная природа показывает, что рекуррентные нейронные сети явно связаны с последовательностями и списками. Таким образом, если мы хотим перевести какой-то текст, мы можем установить каждый ввод как слово в этом тексте. Рекуррентная нейронная сеть передает информацию о предыдущих словах в следующую сеть, которая может использовать и обрабатывать эту информацию.
Рекуррентная нейронная сеть передает информацию о предыдущих словах в следующую сеть, которая может использовать и обрабатывать эту информацию.
На следующем рисунке показано, как обычно работает модель последовательности для последовательности с использованием рекуррентных нейронных сетей. Каждое слово обрабатывается отдельно, и результирующее предложение генерируется путем передачи скрытого состояния на этап декодирования, который затем генерирует выходные данные.
GIF from 3Проблема долговременных зависимостей
Рассмотрим языковую модель, пытающуюся предсказать следующее слово на основе предыдущих. Если мы пытаемся предсказать следующее слово предложения «облака в небе» , нам не нужен дополнительный контекст. Совершенно очевидно, что следующим словом будет небо.
В этом случае, когда разница между релевантной информацией и местом, которое необходимо, невелика, RNN могут научиться использовать прошлую информацию и выяснить, какое следующее слово для этого предложения.
Но бывают случаи, когда нам нужно больше контекста. Например, предположим, что вы пытаетесь предсказать последнее слово текста: «Я вырос во Франции… свободно говорю…». Недавняя информация предполагает, что следующее слово, вероятно, является языком, но если мы хотим сузить выбор языка, нам нужен контекст Франции, который находится дальше по тексту.
Изображение из 6RNN становится очень неэффективным, когда разрыв между релевантной информацией и точкой, где она необходима, становится очень большим. Это связано с тем, что информация передается на каждом шагу, и чем длиннее цепочка, тем больше вероятность потери информации по цепочке.
Теоретически RNN могут изучить эти долгосрочные зависимости. На практике кажется, что они их не учат. LSTM, особый тип RNN, пытается решить эту проблему.
При составлении календаря на день мы расставляем приоритеты в наших встречах. Если есть что-то важное, мы можем отменить некоторые встречи и договориться о том, что важно.
РНС так не делают. Всякий раз, когда он добавляет новую информацию, он полностью преобразует существующую информацию, применяя функцию. Вся информация модифицируется, и нет рассмотрения того, что важно, а что нет.
LSTM вносят небольшие изменения в информацию путем умножения и добавления. В LSTM информация проходит через механизм, известный как состояния ячеек. Таким образом, LSTM могут выборочно запоминать или забывать важные и не очень важные вещи.
Внутренне LSTM выглядит следующим образом:
Изображение из 6Каждая ячейка принимает в качестве входных данных x_t (слово в случае перевода предложения в предложение), предыдущее состояние ячейки и вывод предыдущей ячейки . Он манипулирует этими входными данными и на их основе генерирует новое состояние ячейки и выходные данные. Я не буду вдаваться в детали механики каждой ячейки. Если вы хотите понять, как работает каждая ячейка, я рекомендую запись в блоге Кристофера:
Понимание сетей LSTM — блог Колы
Из-за этих циклов рекуррентные нейронные сети кажутся загадочными.
 Однако, если немного подумать, оказывается, что…
Однако, если немного подумать, оказывается, что…colah.github.io
В состоянии ячейки информация в предложении, важная для перевода слова, может передаваться от одного слова к другому при переводе.
Проблема с LSTM
Та же проблема, которая обычно возникает с RNN, возникает и с LSTM, т. е. когда предложения слишком длинные, LSTM по-прежнему не слишком хороши. Причина этого в том, что вероятность сохранения контекста слова, находящегося далеко от текущего обрабатываемого слова, экспоненциально уменьшается с удалением от него.
Это означает, что при длинных предложениях модель часто забывает содержание удаленных позиций в последовательности. Другая проблема с RNN и LSTM заключается в том, что трудно распараллелить работу по обработке предложений, поскольку вам приходится обрабатывать слово за словом. Не только это, но и отсутствие модели долгосрочных и краткосрочных зависимостей. Подводя итог, LSTM и RNN представляют 3 проблемы:
- Последовательные вычисления препятствуют распараллеливанию
- Отсутствие явного моделирования длинных и коротких зависимостей
- «Расстояние» между позициями является линейным
Чтобы решить некоторые из этих проблем, исследователи создали методику концентрации внимания на конкретных словах.
При переводе предложения я уделяю особое внимание слову, которое сейчас перевожу. Когда я расшифровываю аудиозапись, я внимательно слушаю фрагмент, который активно записываю. И если вы попросите меня описать комнату, в которой я сижу, я буду оглядываться на объекты, которые описываю.
Нейронные сети могут добиться такого же поведения, используя внимание , фокусируясь на части подмножества информации, которую они получают. Например, RNN может следить за выходом другой RNN. На каждом временном шаге он фокусируется на разных позициях в другой RNN.
Чтобы решить эти проблемы, Внимание — это метод, который используется в нейронной сети. Для RNN вместо того, чтобы просто кодировать все предложение в скрытом состоянии, каждое слово имеет соответствующее скрытое состояние, которое передается на всем пути к этапу декодирования. Затем скрытые состояния используются на каждом этапе RNN для декодирования. Следующий gif показывает, как это происходит.
Идея заключается в том, что в каждом слове предложения может быть важная информация. Таким образом, чтобы декодирование было точным, оно должно учитывать каждое слово ввода, используя внимания.
Чтобы привлечь внимание к RNN в трансдукции последовательности, мы разделяем кодирование и декодирование на 2 основных этапа. Один шаг представлен в зеленый и другой фиолетовый . Шаг зеленого цвета называется этапом кодирования , а этап фиолетового цвета — этапом декодирования .
GIF from 3 Зеленый шаг, отвечающий за создание скрытых состояний из ввода. Вместо того, чтобы передавать декодерам только одно скрытое состояние, как мы делали до использования внимание , мы передаем все скрытые состояния, генерируемые каждым «словом» предложения, на этап декодирования.![]() Каждое скрытое состояние используется в декодировании этап , чтобы выяснить, на что сеть должна обратить внимание .
Каждое скрытое состояние используется в декодировании этап , чтобы выяснить, на что сеть должна обратить внимание .
Например, при переводе предложения « Je suis étudiant» на английский требуется, чтобы при переводе шаг декодирования учитывал разные слова.
Этот gif показывает, какой вес придается каждому скрытому состоянию при переводе предложения «Je suis étudiant» на английский язык. Чем темнее цвет, тем больший вес придается каждому слову. GIF от 3Или, например, когда вы переводите предложение «L’accord sur la zone économique européenne a été signé en août 1992». с французского на английский, и сколько внимания уделяется каждому вводу.
Перевод предложения «L’accord sur la zone économique européenne a été signé en août 1992». на английский. Изображение из 3 Но некоторые из проблем, которые мы обсуждали, до сих пор не решены с помощью RNN, использующих внимание . Например, параллельная обработка входных данных (слов) невозможна. Для большого корпуса текста это увеличивает время, затрачиваемое на перевод текста.
Для большого корпуса текста это увеличивает время, затрачиваемое на перевод текста.
Сверточные нейронные сети помогают решить эти проблемы. С ними мы можем
- Простота параллелизации (по слоям)
- Использует локальные зависимости
- Расстояние между позициями логарифмическое
Некоторые из наиболее популярных нейронных сетей для преобразования последовательности, Wavenet и Bytenet, представляют собой сверточные нейронные сети.
Wavenet, модель — сверточная нейронная сеть (CNN). Изображение из 10 Причина, по которой сверточные нейронные сети могут работать параллельно, заключается в том, что каждое слово на входе может обрабатываться одновременно и не обязательно зависит от предыдущих переводимых слов. Мало того, «расстояние» между выходным словом и любым входом для CNN составляет порядка log(N) — это размер высоты дерева, сгенерированного от выхода до входа (вы можете видеть это на GIF выше. Это намного лучше, чем расстояние между выходом RNN и входом , что порядка N .
Проблема в том, что Сверточные Нейронные Сети не обязательно помогают с проблемой выяснения проблемы зависимостей при переводе предложений. сочетание обоих CNN с вниманием.
Чтобы решить проблему распараллеливания, Transformers пытаются решить проблему, используя кодировщики и декодеры вместе с моделями внимания . Внимание повышает скорость перевода модели из одной последовательности в другую.
Давайте посмотрим, как работает Transformer . Трансформер — это модель, которая использует внимание для увеличения скорости. В частности, он использует внимания к себе.
Трансформер. Изображение с 4Внутри Transformer имеет такую же архитектуру, как и предыдущие модели, описанные выше. А вот Transformer состоит из шести энкодеров и шести декодеров.
Изображение из 4 Каждый энкодер очень похож друг на друга. Все кодировщики имеют одинаковую архитектуру. Декодеры имеют одно и то же свойство, то есть они также очень похожи друг на друга. Каждый кодер состоит из двух слоев: Самостоятельное внимание и нейронная сеть прямой передачи.
Каждый кодер состоит из двух слоев: Самостоятельное внимание и нейронная сеть прямой передачи.
Входы энкодера сначала проходят через уровень внимания к себе . Это помогает кодировщику смотреть на другие слова во входном предложении, поскольку он кодирует конкретное слово. У декодера есть оба этих слоя, но между ними находится слой внимания, который помогает декодеру сосредоточиться на соответствующих частях входного предложения.
Изображение из 4Примечание: Этот раздел взят из сообщения в блоге Джея Алламара
Давайте начнем рассматривать различные векторы/тензоры и то, как они перетекают между этими компонентами, чтобы превратить ввод обученной модели в вывод. Как и в случае с приложениями НЛП в целом, мы начинаем с преобразования каждого входного слова в вектор с помощью алгоритма встраивания.
Изображение взято из 4 Каждое слово встроено в вектор размером 512. Мы будем представлять эти векторы с помощью этих простых прямоугольников.
Встраивание происходит только в самом нижнем кодировщике. Абстракция, общая для всех кодировщиков, заключается в том, что они получают список векторов размером 512 каждый.
прямо внизу. После встраивания слов в нашу входную последовательность каждое из них проходит через каждый из двух слоев кодировщика.
Изображение из 4Здесь мы начинаем видеть одно ключевое свойство Преобразователя, а именно то, что слово в каждой позиции проходит в кодировщике по своему пути. Между этими путями на уровне внимания к себе существуют зависимости. Однако уровень прямой связи не имеет таких зависимостей, и поэтому различные пути могут выполняться параллельно при прохождении через уровень прямой связи.
Далее мы переключим пример на более короткое предложение и посмотрим, что происходит на каждом подуровне кодировщика.
Само-внимание
Давайте сначала посмотрим, как рассчитать само-внимание с помощью векторов, а затем перейдем к тому, как это на самом деле реализуется — с помощью матриц.
Первый шаг в вычислении собственного внимания заключается в создании трех векторов из каждого из входных векторов кодировщика (в данном случае встраивания каждого слова). Итак, для каждого слова мы создаем вектор запроса, вектор ключа и вектор значения. Эти векторы создаются путем умножения вложения на три матрицы, которые мы обучали в процессе обучения.
Обратите внимание, что эти новые векторы меньше по размеру, чем вектор вложения. Их размерность равна 64, в то время как векторы ввода/вывода встраивания и кодирования имеют размерность 512. Они НЕ ДОЛЖНЫ быть меньше, это выбор архитектуры, чтобы сделать вычисление многоголового внимания (в основном) постоянным.
Изображение взято из 4 Умножение x1 на весовую матрицу WQ дает q1, вектор «запроса», связанный с этим словом. В итоге мы создаем «запрос», «ключ» и «значение» проекции каждого слова во входном предложении.
Что такое векторы «запрос», «ключ» и «значение»?
Это абстракции, полезные для расчета внимания и размышлений о нем. Как только вы продолжите читать ниже, как рассчитывается внимание, вы узнаете почти все, что вам нужно знать о роли, которую играет каждый из этих векторов.
Второй шаг в подсчете внимания к самому себе заключается в подсчете балла. Скажем, мы вычисляем само-внимание для первого слова в этом примере «Думаю». Нам нужно сопоставить каждое слово входного предложения с этим словом. Оценка определяет, сколько внимания нужно уделять другим частям входного предложения, когда мы кодируем слово в определенной позиции.
Оценка рассчитывается путем скалярного произведения вектора запроса на ключевой вектор соответствующего слова, которое мы оцениваем. Итак, если мы обрабатываем самовнимание для слова в позиции № 1, первая оценка будет скалярным произведением q1 и k1. Вторая оценка будет скалярным произведением q1 и k2.
Изображение из 4 третий и четвертый шаги заключаются в делении баллов на 8 (квадратный корень из размерности ключевых векторов, используемых в статье — 64. Это приводит к более стабильным градиентам. Могут быть и другие возможные значения здесь, но это значение по умолчанию), затем передайте результат через операцию softmax. Softmax нормализует оценки, чтобы все они были положительными и в сумме составляли 1,9.0003 Изображение из 4
Это приводит к более стабильным градиентам. Могут быть и другие возможные значения здесь, но это значение по умолчанию), затем передайте результат через операцию softmax. Softmax нормализует оценки, чтобы все они были положительными и в сумме составляли 1,9.0003 Изображение из 4
Этот показатель softmax определяет, насколько сильно каждое слово будет выражено в этой позиции. Очевидно, что слово в этой позиции будет иметь самый высокий балл softmax, но иногда полезно обратить внимание на другое слово, имеющее отношение к текущему слову.
Пятый шаг заключается в умножении каждого вектора значений на оценку softmax (при подготовке к их суммированию). Интуиция здесь состоит в том, чтобы сохранить нетронутыми значения слов, на которых мы хотим сосредоточиться, и заглушить нерелевантные слова (например, умножив их на крошечные числа, такие как 0,001).
Шестой шаг заключается в суммировании взвешенных векторов значений. Это производит вывод слоя внутреннего внимания в этой позиции (для первого слова).
На этом расчет собственного внимания завершен. Результирующий вектор — это тот, который мы можем отправить в нейронную сеть с прямой связью. Однако в реальной реализации этот расчет выполняется в матричной форме для более быстрой обработки. Итак, давайте посмотрим на это теперь, когда мы увидели интуицию расчета на уровне слов.
Мультиголовное внимание
Трансформеры в основном работают так. Есть еще несколько деталей, которые улучшают их работу. Например, вместо того, чтобы обращать внимание друг на друга только в одном измерении, Трансформеры используют концепцию многоголового внимания.
Идея заключается в том, что всякий раз, когда вы переводите слово, вы можете уделять разное внимание каждому слову в зависимости от типа вопроса, который вы задаете. Изображения ниже показывают, что это означает. Например, всякий раз, когда вы переводите «ударил ногой» в предложении «Я ударил по мячу», вы можете спросить «Кто ударил». В зависимости от ответа перевод слова на другой язык может меняться.