Как и когда правильно использовать знаки R в кружке и ТМ, что они обозначают, в чем разница
Получить консультацию
Товарный знак – инструмент идентификации товара и производителя, который проходит официальную регистрацию на государственном уровне. Эксклюзивное обозначение помещают на упаковку товара, фирменные бланки, визитные карточки и т.д. Часто рядом с оригинальной символикой можно увидеть значки R или TM. Эти обозначения несут определенную смысловую нагрузку.
В статье мы рассмотрим символику охранной маркировки товарного знака, в чем ее функции, значение и правила применения символов R и ТМ, их отличия, чем грозит незаконное применение.
Функции и преимущества предупредительной маркировки товарного знака
Предупредительная символика не обязательна к исполнению. Владелец товарного знака сам принимает решение о том, маркировать ему его товары или нет. И все-таки большинство предпринимателей охотно оповещают рынок о своих исключительных правах. Наличие заветных буковок рядом со словесным обозначением идет на пользу репутации.
Наличие заветных буковок рядом со словесным обозначением идет на пользу репутации.
Компания, которая имеет право расположить рядом с названием продукта значок R или TM, выглядит более солидной в глазах покупателя, даже если он не задумывается о значении этих символов.
Предупредительный значок уведомляет участников рынка о принадлежности обозначения конкретному владельцу, а значит, его использование без ведома и разрешения хозяина будет преследоваться по закону.
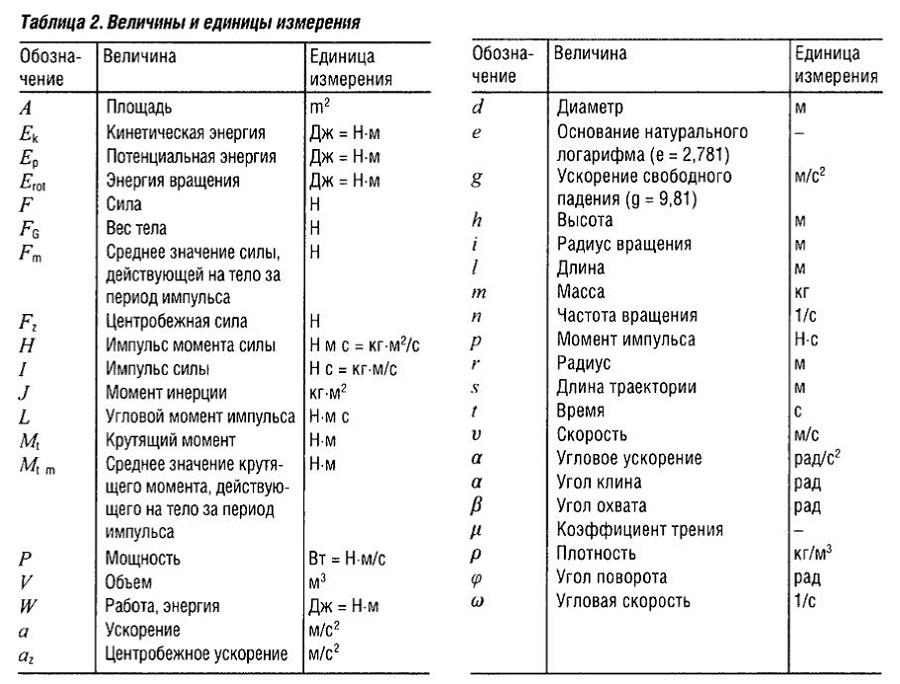
Символы и обозначения маркировки товарного знака
Существует несколько вариаций предупредительной маркировки. Производители могут выбрать один из вариантов, который будет смотреться наиболее гармонично с учетом особенностей упаковки товара (во внимание принимают размеры и цвет тары, а также другие эстетические факторы).
Какие бывают
Варианты обозначений, используемых на территории РФ, описаны в статье 1485 ГК РФ.
Какую маркировку можно использовать:
- большая буква R;
- большая буква R, обведенная кругом;
- словосочетание «товарный знак»;
- словосочетание «зарегистрированный товарный знак».


Латинская буква R означает первую букву английскогоRegistered, что в переводе на русский означает «зарегистрировано».
Где размещаются
Символика размещается по правую сторону от обозначения товарного знака. При этом ее размещают выше уровня строки и используют более мелкие шрифты. Значки могут обводиться кружком, но это необязательно.
Что такое символы маркировки R и ТМ: в чем их отличие
Маркировка R означает, что товарный знак официально зарегистрирован, а значит, имеет юридическую силу и защищен государством. Знак ТМ обладает лишь информативной функцией: с его помощью потребителя информируют о принадлежности группы товаров одному производителю. Некоторые компании используют эту маркировку как предупреждение о том, что владелец уже подал заявку на регистрацию, но она пока еще находится на одной из стадий делопроизводства.
Значок ТМ не обладает юридической силой. Незарегистрированное в ФИПС обозначение не может претендовать на правовую охрану. Если предприниматель уже подал документы в Роспатент и ожидает решения о регистрации, то его права будут защищаться как имеющие приоритет.
Если предприниматель уже подал документы в Роспатент и ожидает решения о регистрации, то его права будут защищаться как имеющие приоритет.
Ответственность за незаконное использование охранной маркировки товарного знака
Некоторые фирмы маркируют свои товары значком R, не имея на это законных оснований. Подобные деяния влекут за собой административную и уголовную ответственность.
Чаще всего таких предпринимателей наказывают штрафами, при повторном нарушении возможны санкции в виде изъятия контрактного товара или наказания в форме принудительных и исправительных работ.
Предприниматели должны отдавать себе отчет, что гораздо проще пойти официальным путем и приобрести законные права на символику, чем подвергать себя штрафным санкциям и рисковать деловой репутацией.
Значки R и TM информируют потребителя и конкурентов о принадлежности товаров к определенной торговой марке. Символ R подтверждает факт официальной регистрации в ФИПС, поэтому его незаконное использование преследуется по закону. Значок ТМ может использоваться свободно, но товарный знак, не зарегистрированный в реестрах Роспатента, на правовую защиту претендовать не может.
Значок ТМ может использоваться свободно, но товарный знак, не зарегистрированный в реестрах Роспатента, на правовую защиту претендовать не может.
Коробка передач автомат: обозначения | Расшифровка букв АКППП
Запишись на первое бесплатное занятие в Москве Написать в чат WhatsАppКогда приходит время обучение вождению, то перед многими учениками встает вопрос, на какой коробке-автомат учиться ездить. Есть АКПП и МКПП. Так что это за буквы? АКПП — что это такое, не совсем понятно. Это ни что иное, как возможность управления автомобилем в режиме автоматики. Водителю остается только научиться расшифровывать обозначения на коробке автомат, которые находятся на панели у рычага переключения режимов. Сегодня мы подробно разберем, что означают буквы на коробке автомат.
Что такое коробка автомат
Коробка-автомат, по сути является трансмиссией. АКПП расшифровка аббревиатуры следующая — Автоматическая Коробка Переключения Передач. Переключает скоростные режимы (повышение и понижение скорости) без участия водителя. Человеку за рулем остается только задавать направление и пользоваться педалями газ, тормоз (педаль сцепления отсутствует), ну и рулить.
Человеку за рулем остается только задавать направление и пользоваться педалями газ, тормоз (педаль сцепления отсутствует), ну и рулить.
Сцепление выполняется самой коробкой. Подходящий момент для смены скорости АКП тоже подбирает сама. Передачи переключаются без рывков, плавно. Управление автотранспортным средством значительно упрощается, в отличие от механики, которой полностью управляет водитель. МКПП расшифровка — Механическая Коробка Переключения Передач. Вариант КПП расшифровка – Коробка Переключения Передач. Переключение выполняется механическим приводом.
Режимы АКПП
В коробке-автомат, как и в механике несколько ступеней скоростей. Рычагом переключаются функциональные возможности – режимы. Как КПП расшифровывается уже выяснили, рассмотрим теперь режимы и их буквенные обозначения:
- N (Neutral) – нейтралка. Положение без скоростей. Режим используется при буксировке машины, например. Некоторые водители во время стояния в пробках ставят рычаг в нейтральное положение, потому что длительное время держать ногу на педали тормоза не совсем удобно;
- D(Drive) или A (Automat) – движение. Переводя рычаг в этот режим, водитель начинает движение, машина трогается с места и ему останется только рулить и нажимать на педали;
- R (Revers) – задняя передача. Позиция применяется для движения автомобиля задним ходом. Включается только после полной остановки. Во время движения переводить рычаг в режим D категорически запрещено;
- P (Parking) – остановка. После прекращения движения, рычаг ставится в положение Р. Это гарантия того, что машина не покатится, потому что режим блокирует колеса. Запрещено включать во время движения. В большинстве моделей двигатель не заведется, если рычаг не поставлен в режим Р;
- M (Manual) – ручное управление. Водитель может сам переключать передачи пользуясь кнопками «+», «-», находящимися на рычаге, либо на руле. В разных моделях по-разному;
- L (Low) или l; 1; 1L – медленно. В этой позиции машина будет двигаться только на первой передаче. Применяется также на скользкой дороге, крутом спуске-подъеме либо для торможения двигателем;
- L2, 2L или просто 2 – в этом режиме езда будет ограничена второй скоростью и выше не переключится;
- D3 или цифра 3 – движение не выше третьей скорости;
- D4 или 4 – машина будет переключаться до четвертой передачи. На 5 и 6 не перейдет;
- OD (Over Drive) – повышенная передача. Режим включается кнопкой на скорости не ниже 75км/ч. Обеспечивая на трассе стабильную езду, экономит топливо;
- KD (Kick Down) – пониженная передача. Включается сама если выжать газ до упора. Помогает быстро набрать скорость;
- B (Block) – блокировка дифференциала. Встречается на авто с полным приводом и джипах. Используется при движении на пересеченной местности, бездорожью;
- S (Sport) – спортивный. Режим использует мощность двигателя на всю катушку. В этом положении становится возможно резко разогнать машину. Топлива сжигается больше чем обычно;
- E – экономия. Наоборот топливо расходуется бережливо, потому что позиция обеспечивает плавность движения;
- W (Winter) или снежинка – зимний. При включенном положении исключается пробуксовка на льду. Машина трогается на 3-4 скорости, переключая их потом на меньших оборотах и выравнивая перепад ускорения. Летом использовать нельзя, во избежание перегрева гидротрансформатора.
 Переводя рычаг в этот режим, водитель начинает движение, машина трогается с места и ему останется только рулить и нажимать на педали;
Переводя рычаг в этот режим, водитель начинает движение, машина трогается с места и ему останется только рулить и нажимать на педали;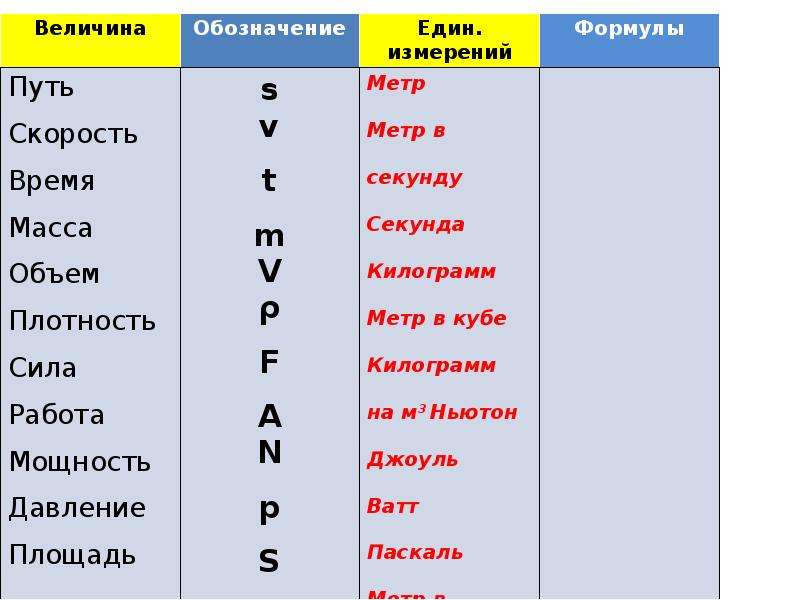 На 5 и 6 не перейдет;
На 5 и 6 не перейдет;
В разных моделях машин с коробкой передач автомат обозначения могут встречаться и другие. Всегда нужно внимательно изучать инструкции и руководства.
Как начать движение на коробке-автомат
Теория вождения такова. Движение на машине с КПП автомат начинается с:
- Сесть за руль и завести двигатель. На панели должны загореться индикаторы. Рычаг должен быть в положении Р или N. Подождать 10 секунд, включится бензонасос;
- Утопить и удерживать педаль тормоза;
- Перевести рычаг в позицию D.;
- Плавно отпускать педаль тормоза. Машина сразу начнет движение. Остается нажимать на газ.
Для заднего хода:
- Полностью остановиться. Нажать тормоз;
- Поставить рычаг в режим R;
- Отпуская тормоз начать движение.
Автоматика не терпит агрессивной езды. Рекомендуется ездить плавно. Электронике нужно время для переключения иначе двигатель будет быстрее изнашиваться. Ремонт автомата штука дорогая.
Как видите, управление автоматической коробкой передач простое, приятное и безопасное.
Услуги Автошколы
Обучение вождениюОбучении теории и практики во всех районах Москвы
Курсы экстремального вожденияПрактика вождения в экстремальных условиях
Обучение вождению автомобиляПолный курс категории Б: теория и практика
Обучение вождению мотоциклаПолный курс категории А: теория и практика
Теория в автошколеПолный курс теории по вождению категорий А и Б
Обучение уверенному вождению для женщин
6 R Обозначение | Практическое программирование с помощью R
Теперь, когда у вас есть колода карт, вам нужен способ делать с ней карточные вещи. Во-первых, вам нужно время от времени перетасовывать колоду. А затем вам нужно раздать карты из колоды (по одной карте за раз, какая бы карта ни была наверху — мы не мошенники).
Во-первых, вам нужно время от времени перетасовывать колоду. А затем вам нужно раздать карты из колоды (по одной карте за раз, какая бы карта ни была наверху — мы не мошенники).
Чтобы сделать это, вам нужно будет работать с отдельными значениями внутри вашего фрейма данных, что является важной задачей для науки о данных. Например, чтобы сдать карту с верха вашей колоды, вам нужно написать функцию, которая выбирает первую строку значений в вашем фрейме данных, например:0003
сделка(колода) ## номинальная стоимость костюма ## king spades 13
Вы можете выбирать значения в объекте R с помощью системы обозначений R.
6.1 Выбор значений
R имеет систему обозначений, позволяющую извлекать значения из объектов R. Чтобы извлечь значение или набор значений из фрейма данных, напишите имя фрейма данных, а затем пару жестких скобок:
колода[ , ]
Между скобками будут два индекса, разделенные запятой. Индексы сообщают R, какие значения возвращать.
Когда дело доходит до написания индексов, у вас есть выбор. Существует шесть различных способов написания индекса для R, и каждый делает что-то свое. Все они очень просты и довольно удобны, поэтому давайте рассмотрим каждый из них. Вы можете создавать индексы с:
- Положительными целыми числами
- Отрицательные целые числа
- Ноль
- Пробелы
- Логические значения
- Имена
Простейшим из них являются положительные целые числа.
6.1.1 Положительные целые числа
R обрабатывает положительные целые числа точно так же, как Deck[i,j] вернет значение Deck , которое находится в -й -й строке и 9 0039 j-й столбец , рис. 6.1. Обратите внимание, что i и j должны быть целыми числами только в математическом смысле. Их можно сохранить как числовые значения в R
Их можно сохранить как числовые значения в R
головке (колоде). ## номинальная стоимость костюма ## король пик 13 ## пиковая дама 12 ## валет пик 11 ## десять пик 10 ## девять пик 9## восемь пик 8 колода[1, 1] ## "king"
Чтобы извлечь более одного значения, используйте вектор положительных целых чисел. Например, вы можете вернуть первую строку колодой[1, c(1, 2, 3)] или колодой[1, 1:3] :
колодой[1, c(1 , 2, 3)] ## номинальная стоимость костюма ## king spades 13
R вернет значения колоды , которые находятся как в первой строке, так и в первом, втором и третьем столбцах. Обратите внимание, что R на самом деле не удалит эти значения из 9.0041 палуба . R предоставит вам новый набор значений, которые являются копиями исходных значений. Затем вы можете сохранить этот новый набор в объект R с помощью оператора присваивания R:
new <- deck[1, c(1, 2, 3)] новый ## номинальная стоимость костюма ## king spades 13
Повторение
Если вы повторите число в своем индексе, R вернет соответствующее значение (я) более одного раза в вашем «подмножестве». Этот код вернет первую строку
Этот код вернет первую строку колоды дважды:
колода[c(1, 1), c(1, 2, 3)] ## номинальная стоимость костюма ## король пик 13 ## король пик 13
Рисунок 6.1: R использует систему обозначений ij линейной алгебры. Команды на этом рисунке вернут заштрихованные значения.
Система обозначений R не ограничивается фреймами данных. Вы можете использовать тот же синтаксис для выбора значений в любом объекте R, если вы указываете один индекс для каждого измерения объекта. Так, например, вы можете подмножить вектор (который имеет одно измерение) с одним индексом:
vec <- c(6, 1, 3, 6, 10, 5) век[1:3] ## 6 1 3
Индексация начинается с 1
В некоторых языках программирования индексация начинается с 0. Это означает, что 0 возвращает первый элемент вектора, 1 возвращает второй элемент и так далее.
Это не относится к R. Индексирование в R ведет себя так же, как индексирование в линейной алгебре. Первый элемент всегда имеет индекс 1. Почему R отличается? Может быть потому, что она была написана для математиков. Те из нас, кто изучал индексирование из курса линейной алгебры, недоумевают, почему программисты начинают с 0.
Почему R отличается? Может быть потому, что она была написана для математиков. Те из нас, кто изучал индексирование из курса линейной алгебры, недоумевают, почему программисты начинают с 0.drop = FALSE
Если вы выберете два или более столбца из фрейма данных, R вернет новый фрейм данных:
колода [1:2, 1:2] ## костюм для лица ## король пик ## queen spades
Однако, если вы выберете один столбец, R вернет вектор:
колода[1:2, 1] ## "король" "королева"
Если вместо этого вы предпочитаете фрейм данных, вы можете добавить необязательный аргумент drop = FALSE между скобками:
deck[1:2, 1, drop = FALSE] ## лицо ## король ## королеваЭтот метод также работает для выбора одного столбца из матрицы или массива.
6.1.2 Отрицательные целые числа
Отрицательные целые числа делают полную противоположность положительным целым числам при индексации. R вернет каждый элемент , кроме элементов в отрицательном индексе. Например,
Например, колода[-1, 1:3] вернет все , но — первую строку колоды . колода[-(2:52), 1:3] вернет первую строку (и исключит все остальное):
дека[-(2:52), 1:3] ## номинальная стоимость костюма ## king spades 13
Отрицательные целые числа являются более эффективным способом создания подмножества, чем положительные целые числа, если вы хотите включить большинство строк или столбцов фрейма данных.
R вернет ошибку, если вы попытаетесь соединить отрицательное целое число с положительным целым числом в том же индексе :
колода[c(-1, 1), 1] ## Ошибка в xj[i] : только 0 могут быть смешаны с отрицательными нижними индексами
Однако вы можете использовать как отрицательные, так и положительные целые числа для подмножества объекта, если вы используете их в различных индексов (например, если вы используете один в индексе строк и один в индексе столбцов, например deck[-1, 1] ).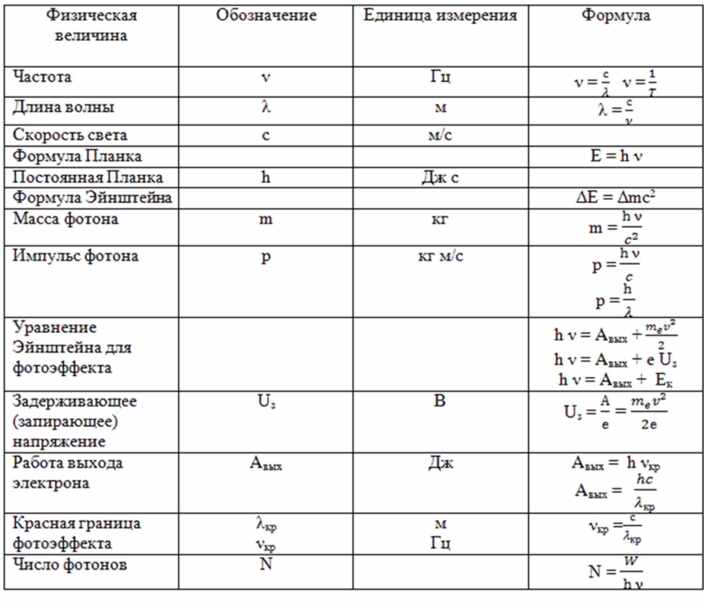
6.1.3 Ноль
Что произойдет, если использовать ноль в качестве индекса? Ноль не является ни положительным целым числом, ни отрицательным целым числом, но R все равно будет использовать его для создания подмножества. R ничего не вернет из измерения, если вы используете ноль в качестве индекса. Это создает пустой объект:
колода [0, 0] ## кадр данных с 0 столбцами и 0 строками
Честно говоря, нулевая индексация не очень полезна.
6.1.4 Пробелы
Вы можете использовать пробел, чтобы указать R извлекать каждые значений в измерении. Это позволяет подмножить объект в одном измерении, но не в других, что полезно для извлечения целых строк или столбцов из фрейма данных:
колода[1, ] ## номинальная стоимость костюма ## king spades 13
6.1.5 Логические значения
Если указать вектор TRUE s и FALSE s в качестве вашего индекса, R будет сопоставлять каждый TRUE и FALSE со строкой в вашем фрейме данных (или столбцом, в зависимости от того, где вы поместите индекс). Затем R вернет каждую строку, соответствующую
Затем R вернет каждую строку, соответствующую TRUE , рис. 6.2.
Можно представить, что R читает фрейм данных и спрашивает: «Должен ли я вернуть _i_th строку структуры данных?» а затем обратиться к _i_th значению индекса для своего ответа. Чтобы эта система работала, ваш вектор должен быть такой же длины, как измерение, которое вы пытаетесь подмножить:
колода[1, c(ИСТИНА, ИСТИНА, ЛОЖЬ)] ## костюм для лица ## король пик строки <- c(ИСТИНА, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ф, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж, Ж) колода [ряды, ] ## номинальная стоимость костюма ## король пик 13
Рисунок 6.2: Вы можете использовать векторы TRUE и FALSE, чтобы указать R, какие именно значения вы хотите извлечь, а какие нет. Команда вернет только числа 1, 6 и 5.
Эта система может показаться странной — кому нужно набирать так много TRUE и FALSE ? — но она станет очень эффективной при изменении значений.
6.1.6 Имена
Наконец, вы можете запросить нужные вам элементы по имени — если у вашего объекта есть имена (см. Имена). Это распространенный способ извлечения столбцов фрейма данных, поскольку столбцы почти всегда имеют имена:
колода[1, c("лицо", "масть", "значение")]
## номинальная стоимость костюма
## король пик 13
# весь столбец значений
колода [ , "значение"]
## 13 12 11 10 98 7 6 5 4 3 2 1 13 12 11 10 9 8
## 7 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2
## 1 13 12 11 10 9 8 7 6 5 4 3 2 1 6.2 Сдать карту
Теперь, когда вы знаете основы системы обозначений R, давайте применим ее.
Упражнение 6.1 (Сдача карты) Завершите следующий код, чтобы создать функцию, возвращающую первую строку фрейма данных:
Deal <- function(cards) {
# ?
} Решение. Вы можете использовать любую из систем, которые возвращают первую строку вашего фрейма данных, для записи сделка функция. Я буду использовать положительные целые числа и пробелы, потому что думаю, что их легко понять: сделка <- функция (карты) {
карты[1, ]
} Функция делает именно то, что вам нужно: она сдает верхнюю карту из вашего набора данных. Однако функция становится менее впечатляющей, если вы запускаете
Однако функция становится менее впечатляющей, если вы запускаете сделку снова и снова:
сделка(колода) ## номинальная стоимость костюма ## король пик 13 сделка (колода) ## номинальная стоимость костюма ## король пик 13 сделка (колода) ## номинальная стоимость костюма ## король пик 13
сделка всегда возвращает пикового короля, потому что колода не знает, что мы сдали карту. Следовательно, пиковый король остается там, где он есть, наверху колоды, готовый к новой сдаче. Это трудная для решения проблема, и мы разберемся с ней в Окружающей среде. А пока вы можете решить эту проблему, перетасовывая колоду после каждой раздачи. Тогда новая карта всегда будет сверху.
Перетасовка — это временный компромисс: вероятность игры в вашей колоде не будет соответствовать вероятности, возникающей при игре с одной колодой карт. Например, все равно будет вероятность того, что пиковый король выпадет два раза подряд. Однако все не так плохо, как может показаться. Большинство казино используют пять или шесть колод одновременно в карточных играх, чтобы предотвратить подсчет карт. Вероятности, с которыми вы столкнетесь в таких ситуациях, очень близки к тем, которые мы создадим здесь.
Большинство казино используют пять или шесть колод одновременно в карточных играх, чтобы предотвратить подсчет карт. Вероятности, с которыми вы столкнетесь в таких ситуациях, очень близки к тем, которые мы создадим здесь.
6.3 Перетасовка колоды
Когда вы перемешиваете реальную колоду карт, вы случайным образом меняете порядок карт. В вашей виртуальной колоде каждая карта представляет собой строку во фрейме данных. Чтобы перетасовать колоду, вам нужно случайным образом переупорядочить строки во фрейме данных. Можно ли это сделать? Вы держите пари! И вы уже знаете все, что нужно для этого.
Это может звучать глупо, но начните с извлечения каждой строки вашего фрейма данных:
колода2 <- колода[1:52, ] голова (палуба2) ## номинальная стоимость костюма ## король пик 13 ## пиковая дама 12 ## валет пик 11 ## десять пик 10 ## девять пик 9## восемь пик 8
Что получится? Новый фрейм данных, порядок которого не изменился вообще. Что, если вы попросите R извлечь строки в другом порядке? Например, вы можете запросить ряд 2, , затем ряд 1, а затем остальные карты:
колода3 <- колода[c(2, 1, 3:52), ] голова (палуба3) ## номинальная стоимость костюма ## пиковая дама 12 ## король пик 13 ## валет пик 11 ## десять пик 10 ## девять пик 9 ## восемь пик 8
R соответствует. Вы получите все строки обратно, и они будут в том порядке, в котором вы их запрашиваете. Если вы хотите, чтобы строки шли в случайном порядке, вам нужно отсортировать целые числа от 1 до 52 в случайном порядке и использовать результаты в качестве индекса строки. Как вы могли сгенерировать такой случайный набор целых чисел? С нашим дружелюбным соседством
Вы получите все строки обратно, и они будут в том порядке, в котором вы их запрашиваете. Если вы хотите, чтобы строки шли в случайном порядке, вам нужно отсортировать целые числа от 1 до 52 в случайном порядке и использовать результаты в качестве индекса строки. Как вы могли сгенерировать такой случайный набор целых чисел? С нашим дружелюбным соседством образец функция:
случайный <- образец (1:52, размер = 52) случайный ## 35 28 39 9 18 29 26 45 47 48 23 22 21 16 32 38 1 15 20 ## 11 2 4 14 49 34 25 8 6 10 41 46 17 33 5 7 44 3 27 ## 50 12 51 40 52 24 19 13 42 37 43 36 31 30 колода4 <- колода[случайная, ] голова (палуба4) ## номинальная стоимость костюма ## пять бубнов 5 ## бубновая королева 12 ## бубновый туз 1 ## пять пик 5 ## девять треф 9 ## jack diamonds 11
Теперь новый набор действительно перетасован. Вы закончите, как только завершите эти шаги в функцию.
Упражнение 6.2 (Перетасовка колоды) Используйте предыдущие идеи, чтобы написать функцию перетасовки .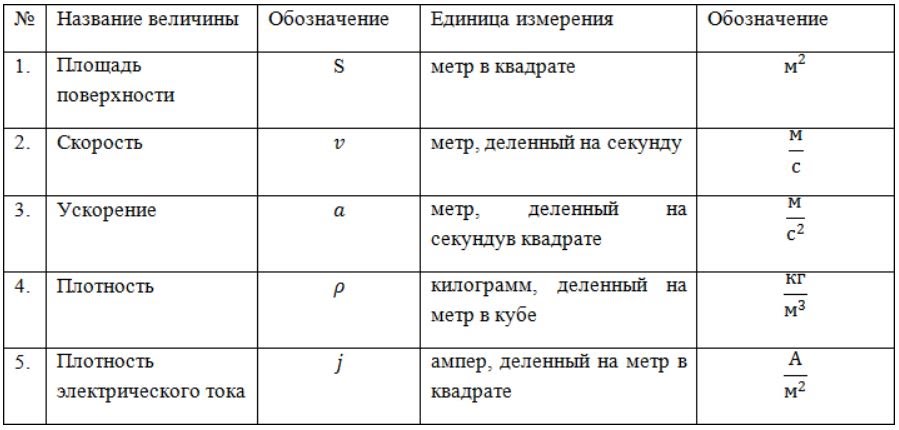
перемешивание должно принимать фрейм данных и возвращать перетасованную копию фрейма данных. Раствор. Ваша функция перемешивания будет выглядеть следующим образом: перемешивание <- функция (карты) {
случайный <- образец (1:52, размер = 52)
карты[случайные, ]
} Отличная работа! Теперь вы можете перетасовывать свои карты между каждой раздачей:
сделка(колода) ## номинальная стоимость костюма ## король пик 13 колода2 <- перетасовать(колода) сделка (палуба2) ## номинальная стоимость костюма ## jack clubs 11
6.4 Знаки доллара и двойные скобки
Два типа объектов в R подчиняются необязательной второй системе обозначений. Вы можете извлекать значения из фреймов данных и списков с помощью синтаксиса $ . Вы будете снова и снова сталкиваться с синтаксисом $ как программист R, поэтому давайте рассмотрим, как он работает.
Чтобы выбрать столбец из фрейма данных, напишите имя фрейма данных и имя столбца, разделенные цифрой 9. 0041 $ . Обратите внимание, что имя столбца не должно заключаться в кавычки:
0041 $ . Обратите внимание, что имя столбца не должно заключаться в кавычки:
deck$value ## 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8 7 ## 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2 1 13 ## 12 11 10 9 8 7 6 5 4 3 2 1
R вернет все значения в столбце в виде вектора. Эта нотация $ невероятно полезна, потому что вы часто будете хранить переменные ваших наборов данных в виде столбцов во фрейме данных. Время от времени вам может понадобиться запустить функцию, например 9.0041 означает или медиану значений в переменной. В R эти функции ожидают вектор значений в качестве входных данных, и deck$value предоставляет ваши данные в правильном формате:
mean(deck$value) ## 7 медиана (стоимость колоды) ## 7
Вы можете использовать ту же нотацию $ с элементами списка, если они имеют имена. Эта нотация имеет преимущество и со списками. Если вы подмножите список обычным способом, R вернет новых списков, содержащих запрошенные вами элементы. Это верно, даже если вы запрашиваете только один элемент.
Это верно, даже если вы запрашиваете только один элемент.
Чтобы увидеть это, составьте список:
lst <- list(numbers = c(1, 2), logical = TRUE, strings = c("a", "b", "c"))
лст
## $числа
## [1] 1 2
## $логический
## [1] ИСТИНА
## $строки
## [1] "a" "b" "c" И затем подмножество:
lst[1] ## $числа ## [1] 1 2
Результатом является меньший список с одним элементом. Этим элементом является вектор c(1, 2) . Это может раздражать, поскольку многие функции R не работают со списками. Например, сумма(lst[1]) вернет ошибку. Было бы ужасно, если бы вы сохранили вектор в списке, а получить его можно было бы только в виде списка:
sum(lst[1]) ## Ошибка в сумме (lst[1]): неверный тип (список) аргумента
Когда вы используете нотацию $ , R вернет выбранные значения как есть, без структуры списка вокруг них:
lst$номера ## 1 2
Затем вы можете сразу передать результаты функции:
sum(lst$numbers) ## 3
Если элементы в вашем списке не имеют имен (или вы не хотите использовать имена), вы можете использовать две скобки вместо одной для подмножества списка. Это обозначение будет делать то же самое, что и
Это обозначение будет делать то же самое, что и $ обозначение:
lst[[1]] ## 1 2
Другими словами, если вы подмножествуете список с записью в одну скобку, R вернет меньший список. Если вы подмножите список с нотацией с двойными скобками, R вернет только значения, которые были внутри элемента списка. Вы можете комбинировать эту функцию с любым из методов индексации R:
lst["numbers"] ## $числа ## [1] 1 2 лст[["числа"]] ## 1 2
Это различие тонкое, но важное. В сообществе R есть популярный и полезный способ думать об этом, рис. 6.3. Представьте, что каждый список — это поезд, а каждый элемент — вагон поезда. Когда вы используете одиночные скобки, R выбирает отдельные вагоны поезда и возвращает их как новый поезд. Каждый вагон сохраняет свое содержимое, но это содержимое все еще находится внутри вагона поезда (т. е. список). Когда вы используете двойные скобки, R фактически разгружает машину и возвращает вам содержимое.
Рисунок 6. 3. Может быть полезно представить свой список как поезд. Используйте одинарные скобки для выбора вагонов поезда, двойные скобки для выбора содержимого внутри вагона.
3. Может быть полезно представить свой список как поезд. Используйте одинарные скобки для выбора вагонов поезда, двойные скобки для выбора содержимого внутри вагона.
Никогда не присоединять
На заре R стало популярным использовать attach() для набора данных после его загрузки. Не делай этого! attach воссоздает вычислительную среду, аналогичную той, которая используется в других статистических приложениях, таких как Stata и SPSS, которые понравились пользователям кроссовера. Однако R — это не Stata или SPSS. R оптимизирован для использования в вычислительной среде R и работает на attach() может вызвать путаницу с некоторыми функциями R.
attach() ? На первый взгляд, прикрепить избавит вас от необходимости печатать. Если вы присоедините набор данных колоды , вы сможете ссылаться на каждую из его переменных по имени; вместо того, чтобы набирать deck$face , вы можете просто ввести face . Но печатать не плохо. Это дает вам возможность быть явным, а в компьютерном программировании явное — это хорошо. Присоединение набора данных создает вероятность того, что R перепутает имена двух переменных. Если это происходит внутри функции, вы, скорее всего, получите непригодные для использования результаты и бесполезное сообщение об ошибке, объясняющее, что произошло.
Но печатать не плохо. Это дает вам возможность быть явным, а в компьютерном программировании явное — это хорошо. Присоединение набора данных создает вероятность того, что R перепутает имена двух переменных. Если это происходит внутри функции, вы, скорее всего, получите непригодные для использования результаты и бесполезное сообщение об ошибке, объясняющее, что произошло.Теперь, когда вы стали экспертом в извлечении значений, хранящихся в R, давайте подведем итоги того, что вы сделали.
6.5 Резюме
Вы узнали, как получить доступ к значениям, которые были сохранены в R. Вы можете получить копию значений, которые находятся внутри фрейма данных, и использовать эти копии для новых вычислений.
Фактически, вы можете использовать систему обозначений R для доступа к значениям в любом объекте R. Чтобы использовать его, напишите имя объекта, за которым следуют скобки и индексы. Если ваш объект одномерный, например вектор, вам нужно указать только один индекс.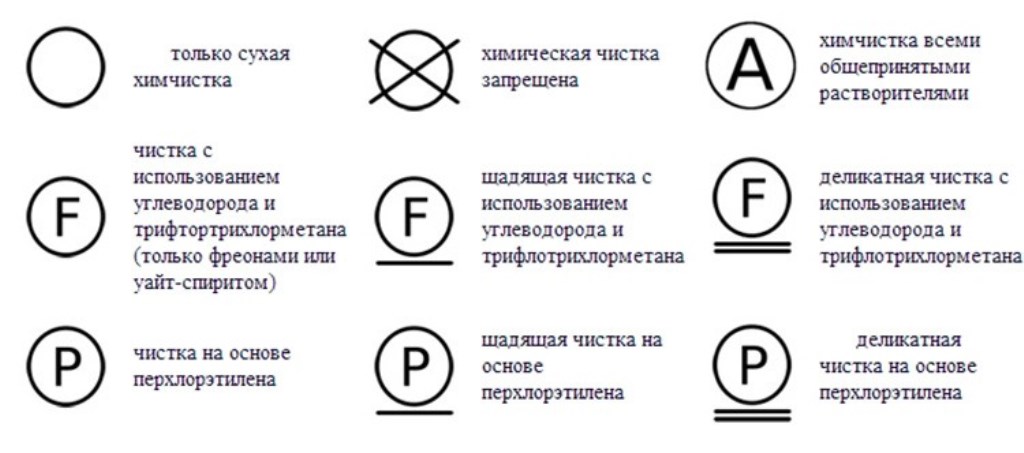 Если он двумерный, как фрейм данных, вам нужно указать два индекса, разделенных запятой. А если n -размерный, необходимо указать n индексов, разделенных запятой.
Если он двумерный, как фрейм данных, вам нужно указать два индекса, разделенных запятой. А если n -размерный, необходимо указать n индексов, разделенных запятой.
В разделе «Изменение значений» вы сделаете еще один шаг в этой системе и узнаете, как изменить фактические значения, хранящиеся внутри вашего фрейма данных. Все это приводит к чему-то особенному: полный контроль над вашими данными. Теперь вы можете хранить свои данные на своем компьютере, извлекать отдельные значения по желанию и использовать свой компьютер для выполнения правильных расчетов с этими значениями.
Звучит банально? Это может быть, но это также мощно и необходимо для эффективной науки о данных. Вам больше не нужно запоминать все в уме и не беспокоиться о том, что вы неправильно считаете в уме. Этот низкоуровневый контроль над вашими данными также является необходимым условием для более эффективных программ R, являющихся предметом Проекта 3: Игровой автомат.
4.
 Нотация R — Практическое программирование с помощью R [Книга]
Нотация R — Практическое программирование с помощью R [Книга]Глава 4. Нотация R
Теперь, когда у вас есть колода карт, вам нужен способ делать с ней карточные вещи. Во-первых, вам нужно время от времени перетасовывать колоду. А затем вам нужно раздать карты из колоды (по одной карте за раз, какая бы карта ни была наверху — мы не мошенники).
Чтобы сделать это, вам нужно будет работать с отдельными значениями внутри вашего фрейма данных, что является важной задачей для науки о данных. Например, чтобы сдать карту с верха колоды, вам нужно написать функцию, которая выбирает первую строку значений во фрейме данных, например:
сделка(колода)## номинал масти## king spades 13
Вы можете выбирать значения в объекте R с помощью системы обозначений R.
Выбор значений
R имеет систему обозначений, позволяющую извлекать значения из объектов R. Чтобы извлечь значение или набор значений из фрейма данных, напишите имя фрейма данных, а затем пару жестких скобок:
колода[,]
В скобках будут два индекса, разделенные запятой. Индексы сообщают R, какие значения возвращать. R будет использовать первый индекс для подмножества строк фрейма данных, а второй индекс — для подмножества столбцов.
Индексы сообщают R, какие значения возвращать. R будет использовать первый индекс для подмножества строк фрейма данных, а второй индекс — для подмножества столбцов.
Когда дело доходит до написания индексов, у вас есть выбор. Существует шесть различных способов написания индекса для R, и каждый делает что-то свое. Все они очень просты и весьма удобны, так что давайте рассмотрим каждый из них. Вы можете создавать индексы с помощью:
- Положительные целые числа
- Отрицательные целые числа
- Нуль
- Пустые места
- Логические значения
- Имена
Простейшим из них являются положительные целые числа.
Положительные целые числа
R обрабатывает положительные целые числа точно так же, как ij в линейной алгебре: й колонка, рисунок 4-1. Обратите внимание, что i и j должны быть целыми числами только в математическом смысле. Их можно сохранить как числа в R:
голова(дека)## номинал масти## король пик 13## пиковая дама 12## валетные лопаты 11## десять пик 10## девять пик 9## восемь пик 8дека[1,1]## "король"
Чтобы извлечь более одного значения, используйте вектор положительных целых чисел. Например, вы можете вернуть первую строку колоды
Например, вы можете вернуть первую строку колоды с помощью колоды [1, c(1, 2, 3)] или колоды[1, 1:3] :
колоды[1,c(1,2,3)]## номинал масти## king spades 13
R вернет значения колода , которые находятся как в первой строке, так и в первом, втором и третьем столбцах. Обратите внимание, что R фактически не удалит эти значения из колоды . R предоставит вам новый набор значений, которые являются копиями исходных значений. Затем вы можете сохранить этот новый набор в объект R с помощью оператора присваивания R:
новый<-колода041 ,2,3)]новый## номинал масти## king spades 13
Повторение
Если вы повторите число в своем индексе, R вернет соответствующее значение (значения) более одного раза в вашем «подмножестве». Этот код вернет первую строку из
Этот код вернет первую строку из колода дважды:
колода[c(1,1),c( 9 00421,2,3)]## номинал масти## король пик 13## король пик 13
Рис. 4-1. В R используется система обозначений ij линейной алгебры. Команды на этом рисунке вернут заштрихованные значения.
Система обозначений R не ограничивается фреймами данных. Вы можете использовать тот же синтаксис для выбора значений в любом объекте R, если вы указываете один индекс для каждого измерения объекта. Так, например, вы можете подмножить вектор (который имеет одно измерение) с одним индексом:
vec<-c(6,1,3, 9 00426,10,5)век[1:3]## 6 1 3
Индексация начинается с 1
В некоторых языках программирования индексация начинается с 0.![]() Это означает, что 0 возвращает первый элемент вектора, 1 возвращает второй элемент и так далее.
Это означает, что 0 возвращает первый элемент вектора, 1 возвращает второй элемент и так далее.
Это не относится к R. Индексация в R ведет себя так же, как индексация в линейной алгебре. Первый элемент всегда имеет индекс 1. Почему R отличается? Может быть потому, что она была написана для математиков. Те из нас, кто изучал индексирование из курса линейной алгебры, недоумевают, почему компьютерные программисты начинают с 0.
drop = FALSE
Если вы выберете два или более столбца из фрейма данных, R вернет новый фрейм данных:
колода[1:2,1:2]## костюм для лица## Пиковый король## пиковая дама
Однако, если вы выберете один столбец, R вернет вектор: 0042 1 ] ## "король" "королева"
Если вместо этого вы предпочитаете фрейм данных, вы можете добавить необязательный аргумент drop = FALSE между скобками:
колода[1:2,19004 1 , падение=ЛОЖЬ]## лицо## король## queen
Этот метод также работает для выбора одного столбца из матрицы или массива.
Отрицательные целые числа
Отрицательные целые числа делают полную противоположность положительным целым числам при индексации. R вернет каждый элемент , кроме элементов в отрицательном индексе. Например, колода[-1, 1:3] вернет все , но — первую строку колоды . колода[-(2:52), 1:3] вернет первую строку (и исключит все остальное):
колода[-(2:9004 1 52) ,1:3]## номинал масти## король пик 13
Отрицательные целые числа являются более эффективным способом создания подмножества, чем положительные целые числа, если вы хотите включить большую часть строк или столбцов фрейма данных.
R вернет ошибку, если вы попытаетесь соединить отрицательное целое число с положительным целым числом в том же index:
deck[c(-1,1),1]## Ошибка в xj[i]: только 0 могут быть смешаны с отрицательными нижними индексами
Однако вы можете использовать как отрицательные, так и положительные целые числа для подмножества объекта, если вы используете их в различных индексах (например, если вы используете одно в индексе строк и одно в индексе столбцов, например колода[-1 , 1] ).
Что произойдет, если использовать ноль в качестве индекса? Ноль не является ни положительным целым числом, ни отрицательным целым числом, но R все равно будет использовать его для создания подмножества. R ничего не вернет из измерения, если вы используете ноль в качестве индекса. Это создает пустой объект:
дека[0,0]## фрейм данных с 0 столбцами и 0 строками
Честно говоря, нулевая индексация не очень полезна.
Пробелы
Вы можете использовать пробел, чтобы указать R извлекать каждые значений в измерении. Это позволяет создавать подмножества объекта в одном измерении, но не в других, что полезно для извлечения целых строк или столбцов из фрейма данных:
колода[1,]## номинал масти## king spades 13
Логические значения
Если вы укажете вектор из TRUE и FALSE в качестве индекса, R будет соответствовать каждому TRUE и 900 41 FALSE в строку ваших данных кадр (или столбец в зависимости от того, где вы поместите индекс). Затем R вернет каждую строку, соответствующую
Затем R вернет каждую строку, соответствующую TRUE , рис. 4-2.
Можно представить, что R читает фрейм данных и спрашивает: «Должен ли я вернуть i -я строка структуры данных?», а затем сверяясь с i -м значением индекса для своего ответа. Чтобы эта система работала, длина вашего вектора должна соответствовать измерению, которое вы пытаетесь подмножить:
колода[1,c(ИСТИНА,900 41 ИСТИНА,ЛОЖЬ)]## костюм для лица## Пиковый корольстроки<-c(ИСТИНА,F,F,F,F,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф9 0041,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф,Ф)колода[строки,]## номинал масти## king spades 13
Рисунок 4-2. Вы можете использовать векторы TRUE и FALSE, чтобы указать R, какие именно значения вы хотите извлечь, а какие нет. Команда вернет только числа 1, 6 и 5.
Вы можете использовать векторы TRUE и FALSE, чтобы указать R, какие именно значения вы хотите извлечь, а какие нет. Команда вернет только числа 1, 6 и 5.
Эта система может показаться странной — кто хочет набирать так много ИСТИНА s и FALSE s? — но он станет очень мощным в главе 5.
Наконец, вы можете запросить нужные вам элементы по имени — если у вашего объекта есть имена (см. Имена). Это распространенный способ извлечения столбцов фрейма данных, поскольку столбцы почти всегда имеют имена:
колода[1,c("лицо",900 41 "костюм","значение")]## номинал масти## король пик 13# весь столбец значенийколода[,"значение"]## 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8## 7 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2## 1 13 12 11 10 9 8 7 6 5 4 3 2 1
Сдайте карту
Теперь, когда вы знаете основы системы обозначений R, давайте применим ее.
Вы можете использовать любую из систем, чтобы написать Deal Функция, которая возвращает первую строку вашего фрейма данных. Я буду использовать положительные целые числа и пробелы, потому что я думаю, что их легко понять:
сделка<-функция(карты){карты[1,]}
Функция делает именно то, что вам нужно: она сдает верхнюю карту из вашего набора данных. Однако функция становится менее впечатляющей, если вы запускаете сделка снова и снова:
сделка(колода)## номинал масти## король пик 13сделка(колода)## номинал масти## король пик 13сделка(колода)## номинал масти## пиковый король 13
сделка всегда возвращает пикового короля, потому что колода не знает, что мы сдали карту. Следовательно, пиковый король остается там, где он есть, наверху колоды, готовый к новой сдаче. Это трудная задача, и мы разберитесь с ним в Главе 6. А пока вы можете решить проблему, перетасовывая колоду после каждой раздачи. Тогда новая карта всегда будет сверху.
Следовательно, пиковый король остается там, где он есть, наверху колоды, готовый к новой сдаче. Это трудная задача, и мы разберитесь с ним в Главе 6. А пока вы можете решить проблему, перетасовывая колоду после каждой раздачи. Тогда новая карта всегда будет сверху.
Перетасовка — это временный компромисс: вероятность игры в вашей колоде не будет соответствовать вероятности, возникающей при игре с одной колодой карт. Например, все равно будет вероятность того, что пиковый король выпадет два раза подряд. Однако все не так плохо, как может показаться. Большинство казино используют пять или шесть колод одновременно в карточных играх, чтобы предотвратить подсчет карт. Вероятности, с которыми вы столкнетесь в таких ситуациях, очень близки к тем, которые мы создадим здесь.
Перетасовать колоду
Когда вы перемешиваете настоящую колоду карт, вы случайным образом меняете порядок карт. В вашей виртуальной колоде каждая карта представляет собой строку во фрейме данных. Чтобы перетасовать колоду, вам нужно случайным образом переупорядочить строки во фрейме данных. Можно ли это сделать? Вы держите пари! И вы уже знаете все, что нужно для этого.
Чтобы перетасовать колоду, вам нужно случайным образом переупорядочить строки во фрейме данных. Можно ли это сделать? Вы держите пари! И вы уже знаете все, что нужно для этого.
Это может звучать глупо, но начните с извлечения каждой строки вашего фрейма данных:
колода2<-колода[1:52,]головка(дека2)## номинал масти## король пик 13## пиковая дама 12## валетные лопаты 11## десять пик 10## девять пик 9## восемь пик 8
Что получится? Новый фрейм данных, порядок которого совсем не изменился. Что, если вы попросите R извлечь строки в другом порядке? Например, вы можете запросить ряд 2, затем ряд 1, а затем остальные карты:
колода 3<-колода[c(2,1,3:52),]головка(дека3)## номинал масти## пиковая дама 12## король пик 13## валетные лопаты 11## десять пик 10## девять пик 9## восемь пик 8
R соответствует. Вы получите все ряды обратно, и они будут в том порядке, в котором вы их запрашиваете. Если вы хотите, чтобы строки шли в случайном порядке, вам нужно отсортировать целые числа от 1 до 52 в случайном порядке и использовать результаты в качестве индекса строки. Как вы могли сгенерировать такой случайный набор целых чисел? С нашим дружелюбным соседством
Вы получите все ряды обратно, и они будут в том порядке, в котором вы их запрашиваете. Если вы хотите, чтобы строки шли в случайном порядке, вам нужно отсортировать целые числа от 1 до 52 в случайном порядке и использовать результаты в качестве индекса строки. Как вы могли сгенерировать такой случайный набор целых чисел? С нашим дружелюбным соседством образец функция:
случайный<-образец(1:52,размер=52)случайный## 35 28 39 9 18 29 26 45 47 48 23 22 21 16 32 38 1 15 20## 11 2 4 14 49 34 25 8 6 10 41 46 17 33 5 7 44 3 27## 50 12 51 40 52 24 19 13 42 37 43 36 31 30колода4<-колода[случайное,]головка(дека4)## номинал масти## пять бриллиантов 5## бубновая дама 12## бубновый туз 1## пять пик 5## девять треф 9## бубны валета 11
Теперь новый набор действительно перетасован. Вы закончите, как только завершите эти шаги в функцию.
Вы закончите, как только завершите эти шаги в функцию.
Ваша функция перетасовки будет выглядеть следующим образом:0042
случайный <- выборка ( 1 : 52 , размер = 52 ) карты [ случайные , ] }
Отличная работа! Теперь вы можете перетасовывать свои карты между каждой раздачей:
раздача(колода)## номинал масти## король пик 13колода2<-перемешивание(колода)сделка(колода2)## номинал масти## валет треф 11
Два типа объектов в R подчиняются необязательной второй системе обозначений. Вы можете извлекать значения из фреймов данных и списков с помощью синтаксиса $ . Вы будете сталкиваться с синтаксисом
Вы будете сталкиваться с синтаксисом $ снова и снова как программист R, так что давайте рассмотрим, как он работает.
Чтобы выбрать столбец из фрейма данных, напишите имя фрейма данных и имя столбца, разделенные цифрой 9.0041 $ . Обратите внимание, что имя столбца не должно заключаться в кавычки:
колода$значение## 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8 7## 6 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2 1 13## 12 11 10 9 8 7 6 5 4 3 2 1
R вернет все значения в столбце в виде вектора. Эта нотация $ невероятно полезна, потому что вы часто будете хранить переменные ваших наборов данных в виде столбцов во фрейме данных. Время от времени вам может понадобиться запустить функцию, например 9.0041 означает или медиану значений в переменной. В R эти функции ожидают вектор значений в качестве входных данных, и deck$value предоставляет ваши данные в правильном формате:
означает(колода$значение)## 7медиана(колода$стоимость)## 7
Вы можете использовать ту же нотацию $ с элементами списка, если они имеют имена. Эта нотация имеет преимущество и со списками. Если вы подмножаете список обычным способом, R вернет число 9.0039 новый список , содержащий запрошенные вами элементы. Это верно, даже если вы запрашиваете только один элемент.
Эта нотация имеет преимущество и со списками. Если вы подмножаете список обычным способом, R вернет число 9.0039 новый список , содержащий запрошенные вами элементы. Это верно, даже если вы запрашиваете только один элемент.
Чтобы увидеть это, составьте список:
lst<-список(числа=c(1,900 41 2),логический=ИСТИНА,строки=c("a","b","c"))лст## $номера## [1] 1 2## $логический## [1] ИСТИНА## $строки## [1] "a" "b" "c"
И затем подмножество:
lst[1]## $номера## [1] 1 2
Результатом является меньший список с одним элементом. Этим элементом является вектор
Этим элементом является вектор c(1, 2) . Это может раздражать, поскольку многие функции R не работают со списками. Например, sum(lst[1]) вернет ошибку. Было бы ужасно, если бы вы сохранили вектор в списке, а получить его можно было бы только в виде списка: ## Ошибка в сумме (lst[1]): недопустимый «тип» (список) аргумента
Когда вы используете нотацию $ , R вернет выбранные значения такими, какие они есть, без структуры списка вокруг них :
lst$номера## 1 2
Затем вы можете сразу передать результаты функции:
сумма(lst$числа)## 3
Если элементы в вашем списке не имеют имен (или вы не хотите использовать имена), вы можете использовать две скобки вместо одной для подмножества списка. Это обозначение будет делать то же самое, что и обозначение $ :
lst[[1]]## 1 2
Другими словами, если вы подмножествуете список с нотацией с одной скобкой, R вернет меньший список. Если вы подмножите список с нотацией с двойными скобками, R вернет только значения, которые были внутри элемента списка. Вы можете комбинировать эту функцию с любым из методов индексации R’s:
Если вы подмножите список с нотацией с двойными скобками, R вернет только значения, которые были внутри элемента списка. Вы можете комбинировать эту функцию с любым из методов индексации R’s:
lst["цифры"]## $номера## [1] 1 2lst[["числа"]]## 1 2
Это различие тонкое, но важное. В сообществе R есть популярный и полезный способ думать об этом, рис. 4-3. Представьте, что каждый список — это поезд, а каждый элемент — вагон поезда. Когда вы используете одиночные скобки, R выбирает отдельные вагоны поезда и возвращает их как новый поезд. Каждый вагон сохраняет свое содержимое, но это содержимое все еще находится внутри вагона поезда (т. е. список). Когда вы используете двойные скобки, R фактически разгружает машину и возвращает вам содержимое.
Рисунок 4-3. Может быть полезно думать о своем списке как о поезде. Используйте одинарные скобки для выбора вагонов поезда, двойные скобки для выбора содержимого внутри вагона.
Никогда не прикреплять
В ранние дни R стало популярным использовать attach() для набора данных после его загрузки. Не делай этого! attach воссоздает вычислительную среду, аналогичную той, которая используется в других статистических приложениях, таких как Stata и SPSS, которые понравились пользователям кроссовера. Однако R — это не Stata или SPSS. R оптимизирован для использования в вычислительной среде R и работает на attach() может вызвать путаницу с некоторыми функциями R.
Что делает attach() ? На первый взгляд, прикрепить избавит вас от необходимости печатать. Если вы присоедините набор данных колоды , вы сможете ссылаться на каждую из его переменных по имени; вместо того, чтобы набирать deck$face , вы можете просто ввести face . Но печатать не плохо. Это дает вам возможность быть явным, а в компьютерном программировании явное — это хорошо. Присоединение набора данных создает вероятность того, что R перепутает имена двух переменных. Если это происходит внутри функции, вы, скорее всего, получите непригодные для использования результаты и бесполезное сообщение об ошибке, объясняющее, что произошло.
Присоединение набора данных создает вероятность того, что R перепутает имена двух переменных. Если это происходит внутри функции, вы, скорее всего, получите непригодные для использования результаты и бесполезное сообщение об ошибке, объясняющее, что произошло.
Теперь, когда вы стали экспертом в извлечении значений, хранящихся в R, давайте подведем итоги того, что вы сделали.
Сводка
Вы узнали, как получить доступ к значениям, которые были сохранены в R. Вы можете получить копию значений, которые находятся внутри фрейма данных, и использовать эти копии для новых вычислений.
Фактически, вы можете использовать систему обозначений R для доступа к значениям в любом объекте R. Чтобы использовать его, напишите имя объекта, за которым следуют скобки и индексы. Если ваш объект одномерный, например вектор, вам нужно указать только один индекс. Если он двумерный, как фрейм данных, вам нужно указать два индекса, разделенных запятой. А если n -размерный, необходимо указать n индексов, разделенных запятой.