
ДНК • Джеймс Трефил, энциклопедия «Двести законов мироздания»
Молекула ДНК имеет форму двойной спирали, и ее воспроизведение основано на том, что каждая цепь двойной спирали служит матрицей для сборки новых молекул.
Сегодня мы знаем, что молекула ДНК является носителем кода, который управляет химизмом всего живого (см. Центральная догма молекулярной биологии), а двойная спираль молекулы ДНК стала одним из самых известных научных символов. Открытие ДНК, как и практически все великие открытия, не было результатом работы одинокого гения, а увенчало собой длинную цепь экспериментальных работ. Так, эксперимент Херши—Чейз продемонстрировал, что носителем генетической информации в клетках является именно ДНК, а не белки. Еще в 1920-е годы американский биохимик родом из России Фибус Левин (Phoebus Levene, 1869–1940) установил, что основные кирпичики, из которых построена ДНК, — это пятиатомный сахар дезоксирибоза (она обозначена буквой Д в слове ДНК), фосфатная группа и четыре азотистых основания — тимин, гуанин, цитозин и аденин (их обычно обозначают буквами Т, Г, Ц и А).
В начале 1950-х годов стали известны два новых факта, пролившие свет на природу ДНК: американский химик Лайнус Полинг (Linus Pauling, 1901–94) показал, что в длинных молекулах, например белках, могут образовываться связи, закручивающие молекулу в спираль, а в лондонской лаборатории Морис Уилкинс и Розалинда Франклин получили данные рентгеноструктурного анализа (основанные на усовершенствованном применении закона Брэгга), позволившие предположить, что ДНК имеет спиральную структуру.
Как раз в это время молодой американский биохимик Джеймс Уотсон отправился на год в Кембриджский университет для работы с молодым английским физиком-теоретиком Фрэнсисом Криком. («Обо мне тогда практически никто не знал, — вспоминал впоследствии Крик, — а идеи Уотсона считали. .. слишком заумными».) Экспериментируя с металлическими моделями, Крик и Уотсон пытались объединить различные компоненты молекулы в трехмерную модель ДНК.
.. слишком заумными».) Экспериментируя с металлическими моделями, Крик и Уотсон пытались объединить различные компоненты молекулы в трехмерную модель ДНК.
Чтобы лучше представить себе полученные ими результаты, вообразите длинную лестницу. Вертикальные стойки этой лестницы состоят из молекул сахара, кислорода и фосфора. Важную функциональную информацию в молекуле несут ступеньки лестницы. Они состоят из двух молекул, каждая из которых крепится к одной из вертикальных стоек. Эти молекулы — четыре азотистых основания — представляют собой одиночные или двойные кольца, содержащие атомы углерода, азота и кислорода и способные образовывать две или три водородные связи (
Считывая ступеньки по одной цепи молекулы ДНК, вы получите последовательность оснований. Представьте, что это сообщение, написанное с помощью алфавита всего из четырех букв. Именно это сообщение определяет химические превращения, происходящие в клетке, и, следовательно, характеристики живого организма, частью которого является эта клетка. На другой цепи спирали никакой новой информации не содержится, ведь если вам известно основание, которое находится на одной цепи, вы знаете и то, какой должна быть вторая половина ступеньки. В некотором смысле две цепи двойной спирали относятся друг другу так же, как фотография и негатив.
Открыв двуспиральную структуру ДНК, Уотсон и Крик поняли и тот простой способ, которым осуществляется воспроизведение молекулы ДНК — как и должно происходить при делении клетки. По их собственным словам, «от нашего внимания не ускользнул тот факт, что постулированная нами специфичная парность азотистых оснований непосредственно указывает на возможный механизм копирования генетического материала».
Такой «возможный механизм копирования» определен структурой ДНК. Когда клетка приступает к делению и необходима дополнительная ДНК для дочерних клеток, ферменты (см. Катализаторы и ферменты) начинают «расстегивать» лестницу ДНК, как застежку-«молнию», обнажая индивидуальные основания. Другие ферменты присоединяют соответствующие основания, находящиеся в окружающей жидкой среде, к парным «обнажившимся» основаниям — А к Т, Г к Ц и т. д. В результате на каждой из двух разошедшихся цепей ДНК достраивается соответствующая ей цепь из компонентов окружающей среды, и исходная молекула дает начало двум двойным спиралям.
Точно так же, как каждое великое открытие основано на работе предшественников, оно дает начало новым плодотворным исследованиям, поскольку ученые используют полученную информацию для движения вперед. Можно сказать, что открытие двойной спирали дало толчок последующему полувековому развитию молекулярной биологии, завершившемуся успешным осуществлением проекта «Геном человека».
Успехи молекулярной онкологии
Том 9, № 3 (2022)
Скачать выпуск PDF
ОБЗОРНЫЕ СТАТЬИ
Значение макрофагов, ассоциированных с опухолью, в развитии рака мочевого пузыря
В. Н. Павлов, М. Ф. Урманцев, Ю. А. Корелов, М. Р. Бакеев
PDF (Rus)
8-14 36
Аннотация
Рак мочевого пузыря занимает 2-е место в структуре онкоурологических заболеваний во всем мире. выделяют мышечно-инвазивную и немышечно-инвазивную формы опухоли. в последнее время большое внимание уделяется изучению микроокружения опухоли (МО) при злокачественных новообразованиях мочевого пузыря. Согласно имеющимся на сегодняшний день данным, МО представляет собой специфическую среду, создающую оптимальные условия для канцерогенеза в неопластическом очаге.
Цель исследования — изучение роли макрофагов, ассоциированных с опухолью, в развитии злокачественных опухолей мочевого пузыря, а также их прогностической ценности.
Перспективы применения статинов в лечении нейрофиброматоза 1-го типа
Р. Н. Мустафин
PDF (Rus)
15-23 25
Аннотация
Нейрофиброматоз 1-го типа развивается вследствие герминальной мутации в гене NF1, кодирующем онкосупрессор нейрофибромин. дефицит данного белка вызывает гиперактивацию протоонкогенов Ras, что ведет к развитию опухолей. Белки Ras подвергаются пренилированию, которое подавляют ингибиторы 3-гидрокси-3-метилглутарил-коэнзим А редуктазы. поэтому они могут быть предложены как противоопухолевые препараты в комплексном лечении нейрофиброматоза 1-го типа. в клинических исследованиях была доказана эффективность статинов в терапии спорадических злокачественных новообразований, в патогенезе которых большую роль играют мутации в гене  данных о воздействии статинов на развитие и прогрессирование нейрофибром у больных нейрофиброматозом 1-го типа в научной литературе не представлено. Однако выявлено, что они усиливают действие противоопухолевых препаратов, использование которых в монорежиме при ассоциированных с нейрофиброматозом злокачественных неоплазмах нерезультативно. в связи с этим, несмотря на неэффективность статинов при когнитивных расстройствах у пациентов с нейрофиброматозом 1-го типа, внедрение этих лекарственных средств в клиническую практику в комбинации с другими препаратами могло бы обеспечить плейотропный эффект, воздействовать на различные звенья патогенеза заболевания.
данных о воздействии статинов на развитие и прогрессирование нейрофибром у больных нейрофиброматозом 1-го типа в научной литературе не представлено. Однако выявлено, что они усиливают действие противоопухолевых препаратов, использование которых в монорежиме при ассоциированных с нейрофиброматозом злокачественных неоплазмах нерезультативно. в связи с этим, несмотря на неэффективность статинов при когнитивных расстройствах у пациентов с нейрофиброматозом 1-го типа, внедрение этих лекарственных средств в клиническую практику в комбинации с другими препаратами могло бы обеспечить плейотропный эффект, воздействовать на различные звенья патогенеза заболевания.
ЭКСПЕРИМЕНТАЛЬНЫЕ СТАТЬИ
Методы детекции специфических для опухолевой ткани однонуклеотидных соматических мутаций в препаратах цДНК из плазмы крови
Л. М. Дьяков,
О. М. Кривцова,
П. А. Хесина,
И.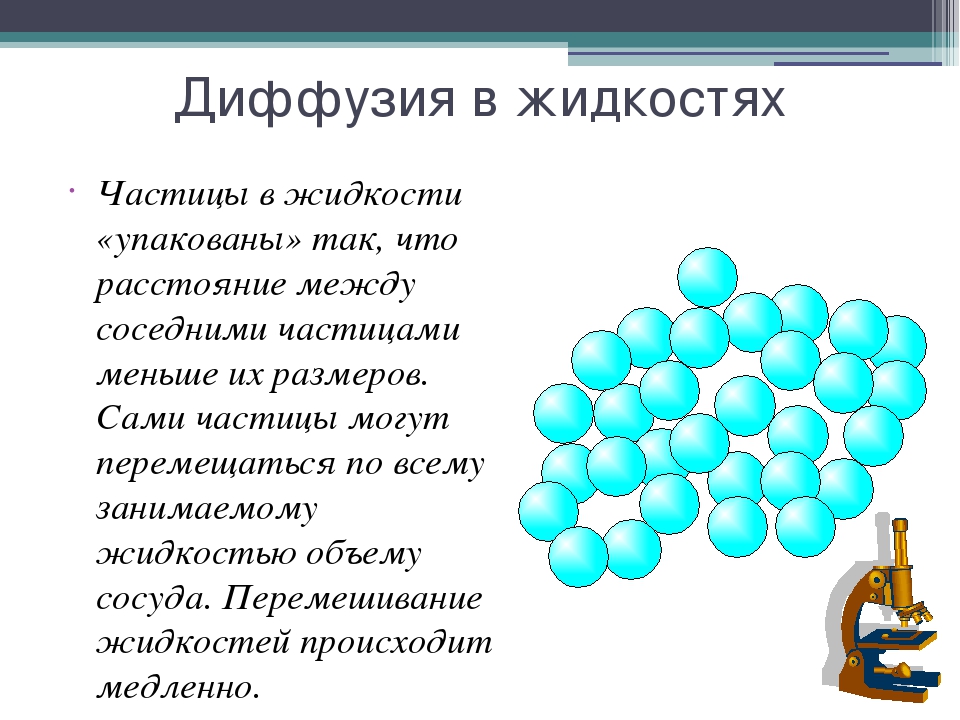 Ф. Кустова,
Н. А. Дьякова,
Н. С. Мюге,
Н. Е. Кудашкин,
Ю. И. Патютко,
Н. Л. Лазаревич
Ф. Кустова,
Н. А. Дьякова,
Н. С. Мюге,
Н. Е. Кудашкин,
Ю. И. Патютко,
Н. Л. Лазаревич
PDF (Rus)
24-37 30
Аннотация
Введение. Жидкостная биопсия рассматривается как малоинвазивный способ проведения молекулярно-генетического анализа, который может быть использован для ранней диагностики, прогноза течения заболевания, мониторинга остаточной болезни или результатов лечения, а также выбора оптимальных для пациента схем лекарственной терапии. Наряду с разработкой тестов, основанных на исследовании панелей онкологически значимых генов или их участков, для различных форм генетически гетерогенных опухолей перспективным подходом может стать использование в качестве объекта жидкостной биопсии индивидуального спектра соматических мутаций конкретного больного, которые могут быть выявлены с помощью высокопроизводительного секвенирования опухолевой ткани.
Цель исследования — определить возможность использования различных методов детекции однонуклеотидных соматических мутаций, выявленных в опухолевой ткани конкретного пациента, в препаратах циркулирующей ДНК (цДНК) из плазмы крови, полученных до хирургического удаления опухоли, и выявить возможность количественной оценки доли альтернативного варианта в общем пуле цДНК.
Материалы и методы. В работе использованы препараты нормальной и опухолевой тканей, плазмы крови пациентов с гепатоцеллюлярной карциномой, а также различные методы детекции однонуклеотидных соматических мутаций: полимеразная цепная реакция (ПЦР) в реальном времени с интеркалирующим красителем или с зондами TaqMan, капельная цифровая ПЦР и высокопроизводительное секвенирование таргетных ампликонов.
Результаты. На примере соматической мутации в гене TLN1, выявленной в опухолевой ткани пациента с гепатоцеллюлярной карциномой, разработаны и апробированы методы, каждый из которых позволяет специфично детектировать мутантный вариант в малых количествах (2 нг) цДНК из плазмы крови того же пациента.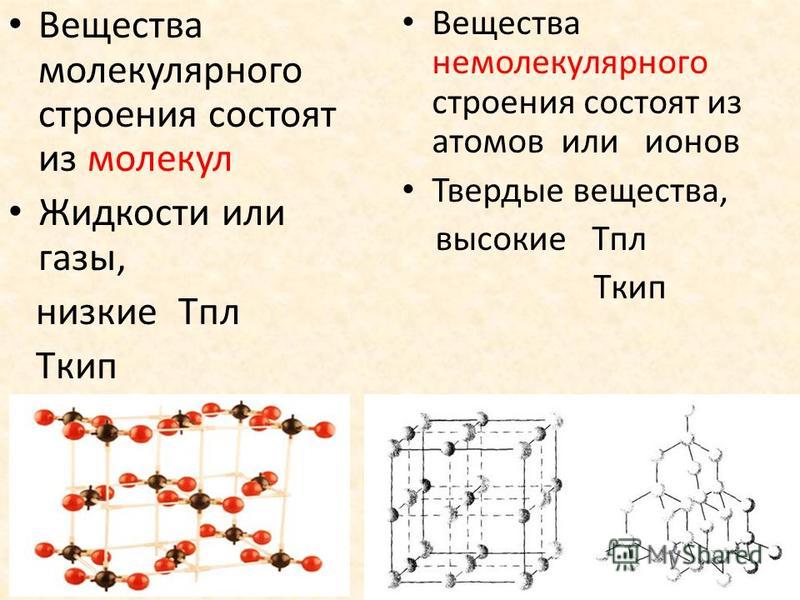 использование капельной ПЦР и секвенирования таргетных ампликонов позволило провести количественную оценку долей мутантного варианта в общем пуле цДНК, которые составили 19,7 и 23,5 % соответственно.
использование капельной ПЦР и секвенирования таргетных ампликонов позволило провести количественную оценку долей мутантного варианта в общем пуле цДНК, которые составили 19,7 и 23,5 % соответственно.
Заключение. Капельная цифровая ПЦР и таргетное секвенирование ампликонов позволяют не только надежно детектировать мутантные варианты в малых количествах цДНК, но и адекватно проводить их количественную оценку, что особенно важно для разработки способов мониторинга опухолевого роста в процессе лечения. Близкие значения доли мутантного варианта в цДНК, детектированной этими методами, свидетельствуют о точности количественного анализа и возможности их использования для кросс-валидации получаемых результатов.
Матриксные металлопротеиназы и белки теплового шока на внеклеточных везикулах у больных колоректальным раком: связь с метаболическим статусом
Н. В. Юнусова,
Д. А. Сваровский,
Е. Э. Дандарова,
Д. Н. Костромицкий,
А. А. Димча,
О. В. Черемисина,
С. Г. Афанасьев,
А. И. Коновалов,
Ж. А. Старцева,
И. В. Кондакова,
М. Р. Патышева,
А. Е. Григорьева,
Л. В. Спирина
Э. Дандарова,
Д. Н. Костромицкий,
А. А. Димча,
О. В. Черемисина,
С. Г. Афанасьев,
А. И. Коновалов,
Ж. А. Старцева,
И. В. Кондакова,
М. Р. Патышева,
А. Е. Григорьева,
Л. В. Спирина
PDF (Rus)
38-48 36
Аннотация
Введение. У большинства больных колоректальным раком (КРР) опухоль возникает на фоне метаболически здорового ожирения, или метаболического синдрома (более чем в 60 % случаев), ключевым патогенетическим моментом которого является развивающаяся гиперинсулинемия. метаболические изменения также характерны для больных с полипами толстой кишки (ПТК), которые в настоящее время рассматриваются как наиболее значимые предраковые заболевания.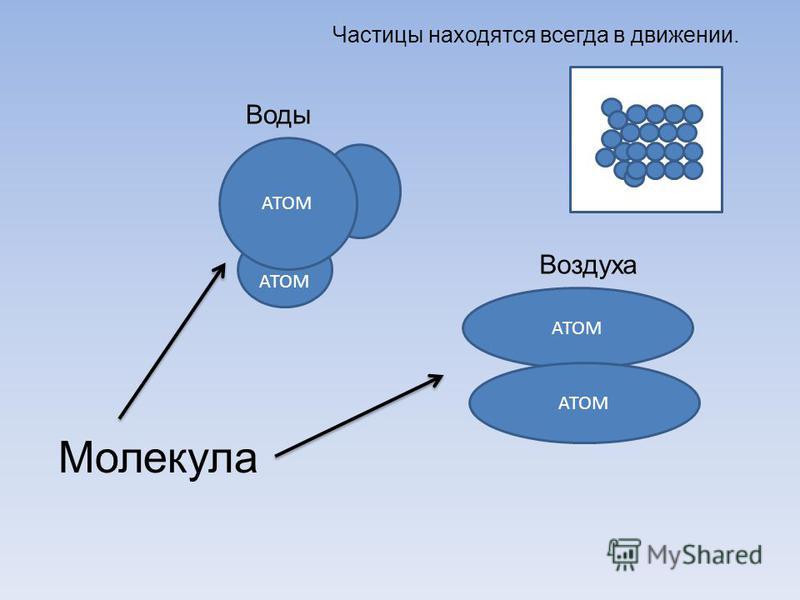 показано, что фракции малых внеклеточных везикул (ВВ) адипоцитарного происхождения специфически обогащены белками внеклеточного матрикса, включая матриксные металлопротеиназы (MMPs), шаперонами, а также некоторыми метаболическими ферментами, участвующими в синтезе липидов и углеводов. это послужило причиной выбора экзосомальных маркеров в нашем исследовании. Сравнение экспрессии протеинов на CD9-и FABP4-позитивных ВВ будет полезно для объяснения некоторых клинических моментов, например эффективности терморадиотерапии или радиотерапии у больных КРР с ожирением, а также для более обоснованного поиска везикулярных прогностических маркеров у онкологических пациентов с ожирением. цель исследования была сформулирована с учетом отсутствия в литературе данных об уровне экспрессии MMPs и белков теплового шока (HSPs) в составе тотального пула ВВ и в FABP4-позитивных ВВ у пациентов с ПТК и КРР.
показано, что фракции малых внеклеточных везикул (ВВ) адипоцитарного происхождения специфически обогащены белками внеклеточного матрикса, включая матриксные металлопротеиназы (MMPs), шаперонами, а также некоторыми метаболическими ферментами, участвующими в синтезе липидов и углеводов. это послужило причиной выбора экзосомальных маркеров в нашем исследовании. Сравнение экспрессии протеинов на CD9-и FABP4-позитивных ВВ будет полезно для объяснения некоторых клинических моментов, например эффективности терморадиотерапии или радиотерапии у больных КРР с ожирением, а также для более обоснованного поиска везикулярных прогностических маркеров у онкологических пациентов с ожирением. цель исследования была сформулирована с учетом отсутствия в литературе данных об уровне экспрессии MMPs и белков теплового шока (HSPs) в составе тотального пула ВВ и в FABP4-позитивных ВВ у пациентов с ПТК и КРР.
Цель исследования — изучение уровня MMPs и HSPs на CD9- и FABP4-позитивных ВВ у пациентов с ПТК и КРР во взаимосвязи с метаболическим статусом.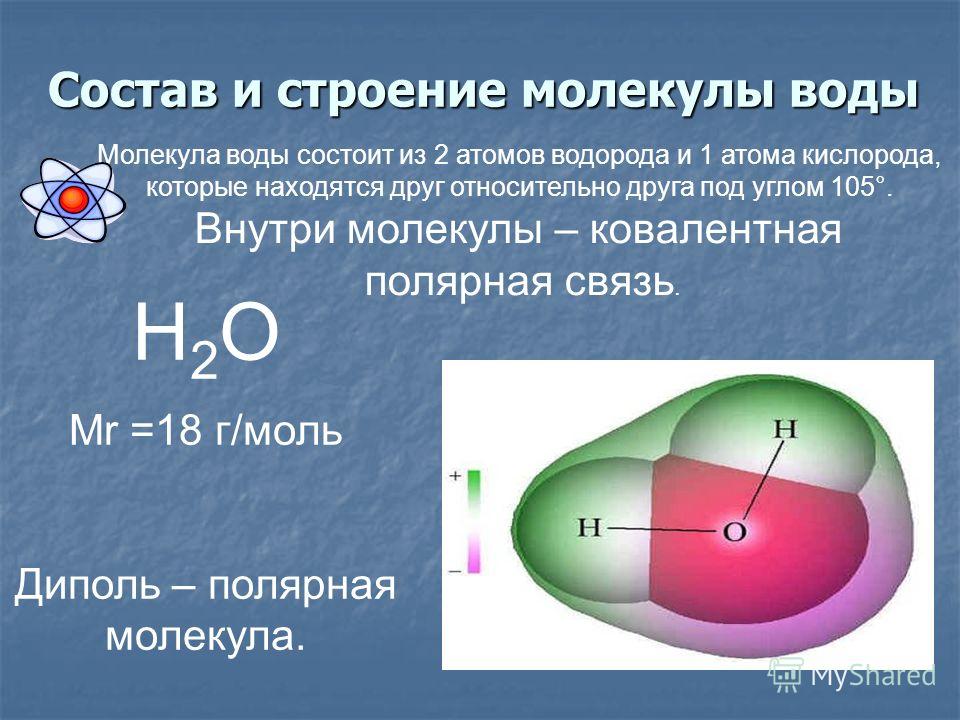
Материалы и методы. В исследование были включены 12 больных КРР (T2-4N0-2M0; средний возраст 59,6 ± 1,6 года), проходивших лечение в отделении абдоминальной онкологии Научно-исследовательского института онкологии Томского национального исследовательского медицинского центра Российской академии наук с 2019 по 2021 г. В группу сравнения вошли 10 пациентов с ПТК. Уровень белков на поверхности CD9- и FABP4-позитивных ВВ был изучен с помощью проточной цитометрии.
Результаты. ММР9-позитивные ВВ чаще выявлялись у больных КРР по сравнению с пациентами с ПТК, однако ММР9+ММР2+Т1МР-позитивные ВВ достоверно чаще обнаруживались у последних. Из изученных белков теплового шока на поверхности ВВ наиболее часто экспрессировался HSP60, причем HSP60-позитивные ВВ выявлялись на поверхности CD9-позитивных экзосом при ПТК гораздо чаще, чем при КРР. У больных КРР по сравнению с пациентами с ПТК среди FABP4-позитивных ВВ наблюдалось существенное увеличение доли трипл-позитивных ВВ и ВВ с фенотипом MMP9+MMP2-TIMP1+, что в целом может свидетельствовать о гиперэкспрессии MMP9 и TIMP1 адипоцитами или маркрофагами жировой ткани у больных КРР. Корреляционный анализ выявил множественные связи отдельных фенотипов CD9-позитивных ВВ у больных КРР с индексом массы тела и уровнем холестерина липопротеинов высокой плотности в сыворотке крови, в то время как фенотипы FABP4-позитивных ВВ были ассоциированы в основном с уровнем триглицеридов.
Корреляционный анализ выявил множественные связи отдельных фенотипов CD9-позитивных ВВ у больных КРР с индексом массы тела и уровнем холестерина липопротеинов высокой плотности в сыворотке крови, в то время как фенотипы FABP4-позитивных ВВ были ассоциированы в основном с уровнем триглицеридов.
Заключение. Фенотипы CD9-позитивных и FABP4-позитивных циркулирующих ВВ перспективны в качестве предикторов для уточнения онкологического риска у больных с полипами толстой кишки, а также в плане объяснения эффективности лечения больных КРР с ожирением или метаболическим синдромом.
Вирус Эпштейна-Барр у адыгейцев и славян в России: типы вируса, варианты LMP1 и злокачественные новообразования
К. В. Смирнова,
Н. Б. Сенюта,
А. К. Лубенская,
И. В. Ботезату,
Т. Е. Душенькина,
А. В. Лихтенштейн,
В. Э. Гурцевич
Е. Душенькина,
А. В. Лихтенштейн,
В. Э. Гурцевич
PDF (Rus)
49-59 22
Аннотация
Введение. Известно, что структурные особенности вируса Эпштейна-Барр (ВЭБ) влияют на проявление его биологических свойств. На основе различий в последовательностях генов EBNA2, EBNA3A, -B и -C идентифицированы 2 типа вируса, 1-й (ВЭБ-1) и 2-й (ВЭБ-2), обладающие разной способностью трансформировать В-клетки in vitro и, возможно, играющие определенную роль в возникновении ВЭБ-ассоциированных новообразований.
Цель исследования — изучение распространенности ВЭБ-1 и вЭБ-2 у 2 этносов, адыгейцев и славян, а также вклада ассоциированных с ВЭБ случаев в общую заболеваемость злокачественными новообразованиями определенных органов и тканей.
Материалы и методы. Из 59 смывов полости рта этнических адыгейцев Республики Адыгея и 40 таковых этнических славян Москвы экстрагировали образцы ДНК. Эти образцы использовали для амплификации ДНК ВЭБ, определения концентрации копий вирусной ДНК на 1 клетку смыва, а также для амплификации LMP1 ВЭБ с последующим секвенированием полученных образцов гена и выявления их белкового варианта (LMP1).
Эти образцы использовали для амплификации ДНК ВЭБ, определения концентрации копий вирусной ДНК на 1 клетку смыва, а также для амплификации LMP1 ВЭБ с последующим секвенированием полученных образцов гена и выявления их белкового варианта (LMP1).
Результаты. Исследования показали, что у представителей адыгейцев преобладает ВЭБ-2, а у славян — ВЭБ-1. изоляты ВЭБ у представителей 2 этносов также различались по структуре его LMP1: у славян выявлен целый набор его белковых вариантов ( В95.8/А, China, Med- и NC), а у адыгейцев — единственный вариант — B95.8 и его подтип -B95.8/A. доминирующий у представителей славян ВЭБ-1, обладающий способностью трансформировать в-клетки, проецировался на более высокую у населения Москвы, чем у населения Республики Адыгея, заболеваемость опухолями глотки, желудка, лимфомой Ходжкина и неходжкинскими лимфомами, в которых встречаются ВЭБ-ассоциированные случаи. Однако различия между показателями заболеваемости для указанных патологий (за исключением данных для желудка) были статистически недостоверными (p >0,5). Более высокий и статистически достоверно отличающийся показатель заболеваемости раком желудка у жителей Москвы по сравнению с таковым у жителей Республики Адыгея, по нашему мнению, не обусловлен ВЭБ-1 и/или вариантами LMP1, а скорее связан с генетической предрасположенностью к этой опухоли населения Москвы.
Более высокий и статистически достоверно отличающийся показатель заболеваемости раком желудка у жителей Москвы по сравнению с таковым у жителей Республики Адыгея, по нашему мнению, не обусловлен ВЭБ-1 и/или вариантами LMP1, а скорее связан с генетической предрасположенностью к этой опухоли населения Москвы.
Заключение. Факт обнаружения у 2 этносов России превалирования различных типов ВЭБ поднимает вопрос об их этногеографической ассоциации и роли в индукции ВЭБ-ассоциированных новообразований. для решения этого вопроса необходимо проведение дополнительных исследований в других географических регионах России у представителей разных этносов.
Детерминанты ферроптоза — потенциальные терапевтические мишени стволовых клеток глиобластомы
В. Е. Шевченко,
З. Н. Никифорова,
Т. И. Кушнир,
И. A. Кудрявцев,
А. А. Митрофанов,
А. Х. Бекяшев,
Н. Е. Арноцкая
A. Кудрявцев,
А. А. Митрофанов,
А. Х. Бекяшев,
Н. Е. Арноцкая
PDF (Rus)
60-68 34
Аннотация
Введение. Терапия мультиформной глиобластомы остается малоэффективной из-за быстроразвивающихся рецидивов опухоли, обусловленных высоким туморогенным потенциалом, резистентностью к химиолучевой терапии и повышенной диссеминацией стволовых клеток глиобластомы. Актуальной становится идентификация потенциальных терапевтических мишеней, позволяющих более эффективно уничтожать данные клетки. в связи с этим большое значение приобретает изучение ферроптоза (ФП), способного вызывать гибель опухолевых клеток с высокозлокачественным фенотипом. Однако ФП и его регуляторные пути в стволовых клетках глиобластомы до конца не изучены. в настоящее время также не ясно, чем отличается ФП в стволовых и дифференцированных клетках глиобластомы.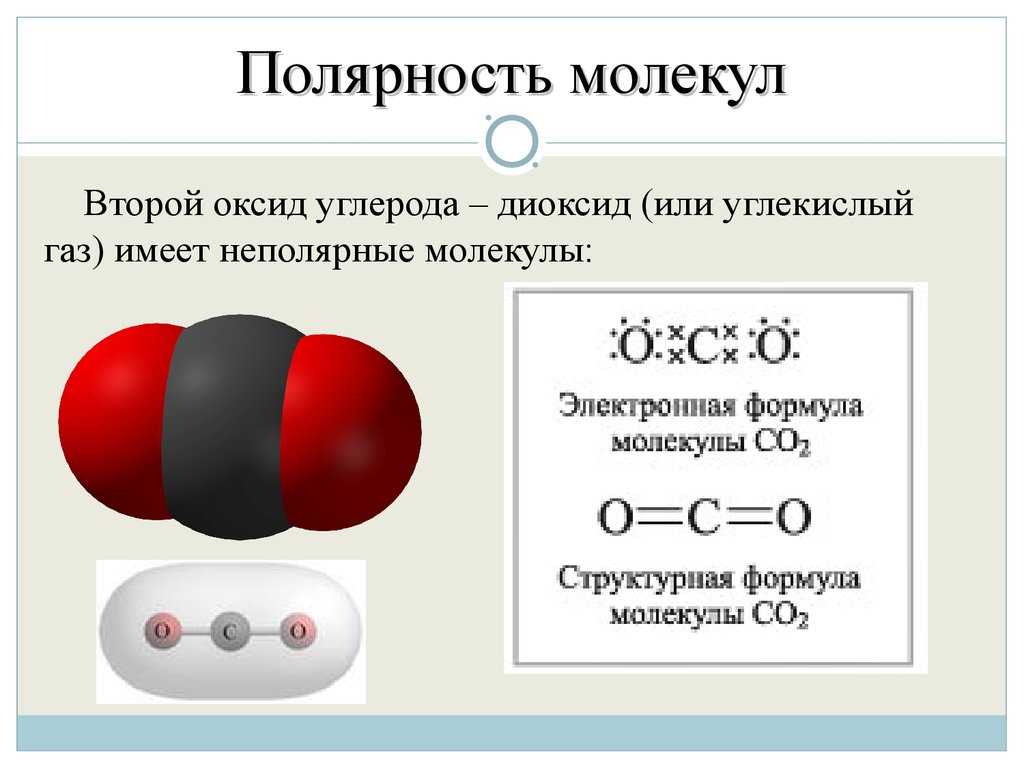
Цель исследования — методом протеомной масс-спектрометрии высокого разрешения изучить экспрессию детерминант сигнального каскада ФП в CD133+-стволовых и CD133—-дифференцированных клетках глиобластомы.
Материалы и методы. использовались протеомная масс-спектрометрия высокого разрешения и клеточные технологии.
Результаты. в целом идентифицированы 1970 белков, 15 из которых связаны с ФП и присутствуют в обеих популяциях клеток. Обнаружена положительная регуляция 12 детерминант ФП (ACSL1, ACSL3, COPZ1, FTh2, FTL, GPX1, GPX4, PCBP1, SLC3A2, TFRC, VDAC1, VDAC2) в CD133+-стволовых клетках глиобластомы по сравнению с CD133— -дифференцированными клетками глиобластомы, 10 из которых имели повышенную более чем в 2 раза экспрессию.
Заключение. Установлены важные закономерности в экспрессии детерминант ФП и протеинов, контролирующих этот процесс в стволовых клетках глиобластомы, которые могут использоваться при разработке новых подходов к обнаружению потенциальных мишеней для терапии мультиформной глиобластомы.
Мутационный профиль диффузной В-крупноклеточной лимфомы с рецидивами в центральной нервной системе
Е. Н. Воропаева, Т. И. Поспелова, В. С. Карпова, М. И. Чуркина, Ю. В. Вяткин, Т. А. Агеева, В. Н. Максимов
PDF (Rus)
69-84 29
Аннотация
Введение. Рецидив диффузной в-клеточной крупноклеточной лимфомы в центральной нервной системе в подавляющем большинстве случаев является фатальным проявлением заболевания. изучение мутационного профиля лимфомы может способствовать улучшению точности прогноза рецидива в центральной нервной системе и обоснованию отбора пациентов для профилактического лечения.
Цель исследования — изучить мутационный профиль случаев диффузной в-клеточной крупноклеточной лимфомы с рецидивами в центральной нервной системе.
Материалы и методы. На платформе Illumina выполнено полноэкзомное секвенирование диагностических образцов диффузной в-клеточной крупноклеточной лимфомы с рецидивами в центральной нервной системе. проанализирована панель, включающая более 70 генов.
Результаты. можно выделить 4 основные группы генетических событий в исследованных образцах, а именно: сочетанные мутации в генах сигнальных путей NF-кВ (MYD88, NOTCh2, CD79B, CARD11) и JAK-STAT (PIM1, STAT6), а также аберрации в главном онкосупрессоре ТР53 и генах системы ремоделирования хроматина (ARID1A, KMT2D, EP300, SMARCA4). в группе исследования выявлена рекуррентная мутация c. 794T>C, p.L265P MYD88. Среди других находок следует отметить мутации в генах CIITA и CD58, имеющих значение в уклонении опухолевых клеток от иммунного надзора.
Заключение. Несмотря на кажущуюся гетерогенность мутационного профиля диффузной в-клеточной крупноклеточной лимфомы с рецидивами в центральной нервной системе, в большинстве случаев для опухолевых клеток были характерны генетические нарушения, приводящие к продукции злокачественными лимфоцитами большого количества провоспалительных цитокинов, а также аберрации, снижающие иммуногенность и способствующие избеганию опухолью иммунного надзора.
ЮБИЛЕЙ
К 95-летию профессора Н.В. Мясищевой
PDF (Rus)
85-86 22
Аннотация
19 августа 2022 г. исполнилось 95 лет доктору медицинских наук, профессору Нине Владимировне Мясищевой — выдающемуся ученому в области патофизиологии и биохимии злокачественного роста.
Контент доступен под лицензией Creative Commons Attribution 4.0 License.
ISSN 2313-805X (Print)
ISSN 2413-3787 (Online)
Теория Бутлерова: химическое строение органических соединений
Предпосылки возникновения
В 1860 году состоялся первый Международный съезд химиков в Карлсруэ, где ученые четко обозначили разницу между привычными для нас понятиями атома и молекулы. В это же время утвердили и атомно-молекулярное учение, которое позже легло в основу теории химического строения.
Чуть раньше, в 1853 году, английский химик Эдуард Франкленд ввел понятие «валентность», а спустя пять лет Фридрих Кекуле установил, что валентность углерода в органических соединениях равна четырем. К тому же Кекуле и Купер уже в 1857 году выдвигали предположения о том, что атомы углерода могут образовывать цепочки.
Однако у великих умов еще оставались вопросы. Например, как несколько химических элементов способны образовывать такое многообразие соединений? Или как вещества, имеющие одинаковую исходную формулу, могут иметь разные физические и химические свойства? Вот здесь-то и выдвинул свою теорию химического строения Александр Михайлович Бутлеров.
Практикующий детский психолог Екатерина Мурашова
Бесплатный курс для современных мам и пап от Екатерины Мурашовой. Запишитесь и участвуйте в розыгрыше 8 уроков
А. М. Бутлеров и его идеи
Александр Михайлович Бутлеров — великий русский химик, ученик Н. Н. Зинина, лауреат Ломоносовской премии и создатель теории химического строения органических веществ.
Н. Зинина, лауреат Ломоносовской премии и создатель теории химического строения органических веществ.
Еще в 1858 году на заседании Парижского химического общества Бутлеров, выступив с первым докладом, внес ясность в определение радикалов. Он утверждал, что радикалами следует считать не только органические группы атомов, но и характерные для различных классов сочетания атомов. Например, —OH или —NH2. Позже такие сочетания атомов получили название функциональных групп. В этом же докладе Александр Михайлович впервые употребил термин «структура».
В более развернутой и доработанной форме Бутлеров представил свою теорию на суд общественности в 1861 году в химической секции Съезда немецких естествоиспытателей и врачей. В его докладе «О химическом строении вещества» говорилось, что теоретическая сторона химии на текущий момент перестала отвечать фактическому развитию химии как науки. В частности, ученый отметил нестыковки в теориях, выдвинутых ранее.
Нужно сказать, что сам Бутлеров не формулировал теорию химического строения по пунктам: мысли на этот счет он выдвигал в различных статьях, они же пронизывают все его практические эксперименты.
Основные положения теории Бутлерова
С Бутлеровым мы познакомились, теперь пришло время познакомиться с основными положениями теории химического строения органических веществ:
Атомы в молекулах соединены между собой химическими связями в соответствии с их валентностью.
Важно помнить
Валентность углерода в органических соединениях равна 4.
Атомы в молекулах органических веществ соединены в определенной последовательности, которую характеризует химическое строение молекулы.
Определенная последовательность соединений атомов в молекуле с учетом их валентностей называется химическим строением, которое, в свою очередь, отражают структурные формулы.
 А последовательное соединение атомов углерода друг с другом, образующее каркас молекулы, называется углеродным скелетом. Но есть одно но: структурные формулы не отражают пространственное расположение молекулы. Вот как можно изобразить строение одной и той же молекулы различными структурными формулами:
А последовательное соединение атомов углерода друг с другом, образующее каркас молекулы, называется углеродным скелетом. Но есть одно но: структурные формулы не отражают пространственное расположение молекулы. Вот как можно изобразить строение одной и той же молекулы различными структурными формулами:Структурные формулы чаще всего изображают в сокращенном виде, например CH3—CH2—CH2—CH3. Однако в сокращенном виде видна только связь «углерод — углерод» и не видны связи «углерод — водород» и «углерод — кислород».
Если в молекуле четыре атома углерода и более, то ее строение может быть не только линейным, но и разветвленным:
Давайте внимательно рассмотрим строение каждой молекулы. Атомы углерода одной из молекул связаны с одним или двумя соседними атомами углерода, как, например, в другой молекуле один из атомов углерода связан сразу с тремя атомами углерода.
Отсюда можно предположить, что разному порядку связывания атомов при одинаковом количестве атомов углерода и водорода в данном случае должны соответствовать различные вещества с разными свойствами. Действительно, все так и есть:Разницу в температурах кипения при одинаковом количественном и качественном составе подтверждают литературные данные.
Все это приводит нас к такому понятию, как изомеры. Изомерами называют вещества с одинаковым количественным и качественным составом, но с разными физико-химическими свойствами, которые обусловлены различным строением. Явление существования различных форм веществ или изомеров называется изомерией. Об изомерах и изомерии мы уже рассказывали в нашем блоге.
Свойства органических веществ зависят не только от числа и природы входящих в состав атомов, но и от химического строения молекулы.
Зная строение вещества, можно охарактеризовать его свойства.В молекулах существует взаимное влияние как непосредственно связанных, так и не связанных между собой атомов.
Химическое строение вещества можно определить благодаря изучению его химических превращений.
 А последовательное соединение атомов углерода друг с другом, образующее каркас молекулы, называется углеродным скелетом. Но есть одно но: структурные формулы не отражают пространственное расположение молекулы. Вот как можно изобразить строение одной и той же молекулы различными структурными формулами:
А последовательное соединение атомов углерода друг с другом, образующее каркас молекулы, называется углеродным скелетом. Но есть одно но: структурные формулы не отражают пространственное расположение молекулы. Вот как можно изобразить строение одной и той же молекулы различными структурными формулами: Отсюда можно предположить, что разному порядку связывания атомов при одинаковом количестве атомов углерода и водорода в данном случае должны соответствовать различные вещества с разными свойствами. Действительно, все так и есть:
Отсюда можно предположить, что разному порядку связывания атомов при одинаковом количестве атомов углерода и водорода в данном случае должны соответствовать различные вещества с разными свойствами. Действительно, все так и есть: Зная строение вещества, можно охарактеризовать его свойства.
Зная строение вещества, можно охарактеризовать его свойства.Бесплатные занятия по английскому с носителем
Занимайтесь по 15 минут в день. Осваивайте английскую грамматику и лексику. Сделайте язык частью жизни.
Вопросы для самопроверки
Основоположником теории химического строения является…
Зинин
Ломоносов
Менделеев
Бутлеров
Какова валентность углерода в органических молекулах?
I
V
II
IV
Определенная последовательность соединений атомов в молекуле называется…
Изомерией
Гомологами
Углеродным скелетом
Химической формулой
Способны ли структурные формулы отображать пространственное строение молекулы?
Да
Нет
Это одно и то же
Верно ли утверждение: «Наличие изомеров зависит от общего количества атомов углерода в молекуле»?
Верно
Неверно
Изомеры есть у всех веществ
Можно ли предугадать химические свойства, зная строение молекулы?
Это невозможно
Можно, так как свойства зависят от строения
Только зная свойства, можно рассказать о строении молекулы
Глубже разобраться в положениях и значении теории Бутлерова можно на уроках химии в онлайн-школе Skysmart. Мы учим понимать химические явления на примерах из окружающей ученика реальности, показываем межпредметные связи и помогаем ответить на вопрос «Зачем все это учить?». Оставьте заявку и пройдите бесплатное тестирование, а мы подберем подходящий курс и рекомендации для самостоятельного обучения!
Мы учим понимать химические явления на примерах из окружающей ученика реальности, показываем межпредметные связи и помогаем ответить на вопрос «Зачем все это учить?». Оставьте заявку и пройдите бесплатное тестирование, а мы подберем подходящий курс и рекомендации для самостоятельного обучения!
Ответы на вопросы
d
d
c
b
a
b
Великолепная «молекула сообщения» — Creation.com
Эта статья из
Creation 17 (4):10–13, сентябрь 1995 г.
Просмотрите наш последний цифровой выпуск Подписывайся
Фейсбук Твиттер Пинтерест Реддит LinkedIn Gmail Приложение электронной почты Распечатать
Примечание редактора: Поскольку журнал Creation непрерывно издается с 1978 года, мы
публикуем некоторые статьи из архивов для исторического интереса, такие как эта. Для обучения и
в целях обмена, читателям рекомендуется дополнять эти исторические статьи более современными статьями, доступными с помощью поиска на сайте creative.com.
Для обучения и
в целях обмена, читателям рекомендуется дополнять эти исторические статьи более современными статьями, доступными с помощью поиска на сайте creative.com.
Карла Виланда
Когда кто-то отправляет сообщение, передается что-то довольно увлекательное и таинственное
вместе. Скажем, Альфонс из Эльзаса хочет послать сообщение: «Нед, война
над. Ал’. Он диктует его другу; сообщение началось как узоры воздуха
сжатие (разговорные слова). Его друг записывает это чернилами на бумаге и отправляет по почте.
другому, который помещает его в факсимильный аппарат. Машина передает сообщение в
закодированная последовательность электрических импульсов, которые посылаются по телефонной линии и принимаются
на отдаленном индийском аванпосте, где оно снова напечатано буквами. Здесь
человек, который читает факс, разжигает костер и отправляет то же сообщение в виде шаблона
дымовых сигналов. Старый Нед в Неваде, за много миль отсюда, смотрит вверх и получает точное сообщение
это было предназначено для него. Ничего физического не было передано; ни одного атома
или молекула любого вещества переместилась из Эльзаса в Неваду, но это очевидно
что что-то проехал весь путь.
Ничего физического не было передано; ни одного атома
или молекула любого вещества переместилась из Эльзаса в Неваду, но это очевидно
что что-то проехал весь путь.
Это неуловимое нечто называется информация . это явно не материал вещь, так как это не было передано. Тем не менее, кажется, нужен вопрос, на котором «ехать» во время своего путешествия. Это правда, если сообщение на турецком, тамильском или тагальский. Материя, по которой распространяется информация, может измениться без информации. приходится менять. Молекулы воздуха сжимаются в звуковых волнах; чернила и бумага; электроны, путешествующие по телефонным проводам, семафорные сигналы — что угодно — все включают материальные среды, используемые для передачи информации, но среда не является Информация.
Эта увлекательная вещь, называемая информацией, является ключом к пониманию того, что делает
жизнь отличается от мертвой материи. Это ахиллесова пята всех материалистических объяснений.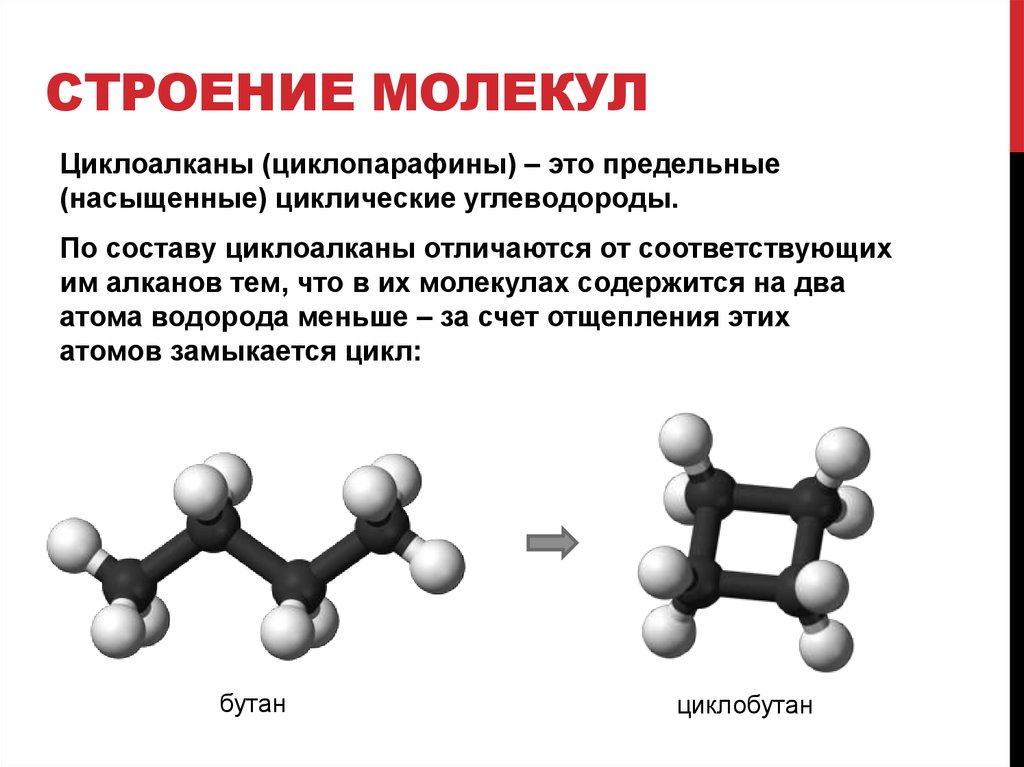 жизни, которые говорят, что жизнь есть не что иное, как материя, подчиняющаяся законам физики
и химия. Жизнь — это больше, чем просто физика и химия; живые существа несут
огромные объемы информации.
жизни, которые говорят, что жизнь есть не что иное, как материя, подчиняющаяся законам физики
и химия. Жизнь — это больше, чем просто физика и химия; живые существа несут
огромные объемы информации.
Кто-то может возразить, что лист бумаги с письменным сообщением — не что иное, как чем чернила и бумага, подчиняющиеся законам физики и химии. Но чернила и бумага без посторонней помощи сообщения не пишут — это делает разум. Алфавитные буквы в Scrabble® Набор не представляет собой информацию, пока кто-то не поставит их в специальную последовательность — ум необходимо для получения информации. Вы можете запрограммировать машину, чтобы устроить Scrabble® письма в сообщение, но надо было написать программу для машины.
Как переносится информация для жизни? Как сообщение, в котором излагается
рецепт, который делает лягушку, а не дерево франжипани, отправленное из одного поколения
к следующему? Как он хранится? На чем он «ездит»? Ответ
чудесная «молекула сообщения», называемая ДНК. Эта молекула похожа на длинную веревку или нить.
бусинок, которые туго свернуты внутри центра каждой клеточки вашего тела.
Это молекула, несущая программы жизни, информацию, которая
передается от каждого поколения к следующему. *
Эта молекула похожа на длинную веревку или нить.
бусинок, которые туго свернуты внутри центра каждой клеточки вашего тела.
Это молекула, несущая программы жизни, информацию, которая
передается от каждого поколения к следующему. *
Некоторые люди думают, что ДНК живая — это неправильно. ДНК — мертвая молекула. Он не может копировать сам себя — вам нужен механизм живой клетки, чтобы делать копии. молекулы ДНК. Может показаться, что ДНК — это информация в твое тело. Это не так — ДНК является просто носителем сообщения, «посредником». на котором написано сообщение. Точно так же буквы Scrabble® не информации до тех пор, пока сообщение не будет «навязано» им «извне». Думать о ДНК как цепочка таких букв алфавита, связанных вместе, с большим разнообразием разными путями, как это может произойти. Если они не соединены в правильной последовательности, никакого полезного сообщения не получится, даже если это все еще ДНК.
Теперь, чтобы прочитать сообщение, вам нужен уже существующий языковой код или соглашение, как
а также машины для его перевода. Весь этот механизм существует в клетке. Нравиться
искусственных машин, оно не возникает само по себе из свойств сырья.
Если вы просто соедините основные сырьевые ингредиенты для живой клетки, не
информации ничего не будет. Машины и программы не исходят из законов
физики и химии сами по себе. Почему? Поскольку они отражают информацию и
никогда не наблюдалось, чтобы информация появлялась без посторонней помощи, из сырой материи и времени.
и шанс. Информация — полная противоположность случайности: если вы хотите организовать
буквы в последовательность для написания сообщения, должен быть установлен определенный порядок
по вопросу.
Весь этот механизм существует в клетке. Нравиться
искусственных машин, оно не возникает само по себе из свойств сырья.
Если вы просто соедините основные сырьевые ингредиенты для живой клетки, не
информации ничего не будет. Машины и программы не исходят из законов
физики и химии сами по себе. Почему? Поскольку они отражают информацию и
никогда не наблюдалось, чтобы информация появлялась без посторонней помощи, из сырой материи и времени.
и шанс. Информация — полная противоположность случайности: если вы хотите организовать
буквы в последовательность для написания сообщения, должен быть установлен определенный порядок
по вопросу.
Когда живые существа размножаются, они передают информацию от одного поколения к другому.
следующий. Эта информация, путешествующая по ДНК от матери и отца, является
«руководство по эксплуатации», которое позволяет механизму в оплодотворенной яйцеклетке конструировать,
из сырья новый живой организм — фантастический подвиг. Это в
новую комбинацию, так что дети не совсем похожи на своих родителей, хотя
сама информация, которая выражается в облике этих детей, была там
все время у обоих родителей. То есть колода была перетасована, но новых карт не было.
добавлен.
То есть колода была перетасована, но новых карт не было.
добавлен.
Сколько места нужно ДНК для хранения информации? Технологические достижения человечества в хранении информации кажутся сенсационными. Представьте, сколько информации хранится, например, на видеокассете с фильмом — вы можете хранить все это в одном рука. Но по сравнению с этим подвиг миниатюризации информации, совершенный ДНК просто ошеломляет. При заданном объеме информации комната Для хранения информации на ДНК требуется примерно одна триллионная часть информации на видеопленке, т.е. он в миллион миллионов раз эффективнее хранит информацию. 1
Сколько информации содержится в коде ДНК, который вас описывает? оценки
широко варьироваться. Используя простые аналогии, основанные на пространстве для хранения в ДНК, они варьируются
от 500 больших библиотечных книг мелкой информации до более 100 полных
Комплекты энциклопедий из 30 томов. Если подумать, даже это, вероятно, не
достаточно, чтобы описать сложную конструкцию даже человеческого мозга с его триллионами
точных связей. Вероятно, существуют хранилища информации более высокого уровня и
системы размножения в организме, о которых мы еще и не мечтали, — есть
еще много удивительных тайн, ожидающих своего открытия о Творце».
ручная работа.
Вероятно, существуют хранилища информации более высокого уровня и
системы размножения в организме, о которых мы еще и не мечтали, — есть
еще много удивительных тайн, ожидающих своего открытия о Творце».
ручная работа.
Мало того, что способ кодирования ДНК очень эффективен — еще больше места спасает то, как он туго свернут. По мнению генетика Профессор Жером Лежен, всю информацию, необходимую для уточнения точный состав каждого уникального человека на Земле можно было бы хранить в объеме ДНК не больше пары таблеток аспирина! 2 Если вы возьмете ДНК из одной-единственной клетки вашего тела (количество материи настолько маленькое, надо бы в микроскоп увидеть) и распутал, растянулся бы на два метров!
Это становится поистине сенсационным, если учесть, что существует от 75 до 100 трлн.
клеток в организме. Если взять нижнюю цифру, то это означает, что если мы вытянем все
ДНК в одном организме человека 3 и
соединив его встык, он протянулся бы на расстояние 150 миллиардов километров (около
94 миллиарда миль). Как долго это? Он протянулся бы прямо вокруг экватора Земли.
три с половиной миллиона раз! Это в тысячу раз дальше, чем от Земли
к солнцу. Если бы вы посветили фонариком на такое расстояние, это заняло бы
легкий, путешествуя со скоростью 300 000 километров (186 000 миль) каждую секунду, пять с половиной
дней, чтобы добраться туда.
Как долго это? Он протянулся бы прямо вокруг экватора Земли.
три с половиной миллиона раз! Это в тысячу раз дальше, чем от Земли
к солнцу. Если бы вы посветили фонариком на такое расстояние, это заняло бы
легкий, путешествуя со скоростью 300 000 километров (186 000 миль) каждую секунду, пять с половиной
дней, чтобы добраться туда.
Но по-настоящему сенсационно то, как распространялась информация. ДНК всех живых существ прямо указывает на разумное, сверхъестественное творение, по простой научной логике следующим образом:
Наблюдения
1. Закодированная информация, используемая при построении живых существ, передается из ранее существовавших сообщений (программ), которые сами передаются из ранее существовавших Сообщения.
2. Во время этой передачи судьба информации следует диктату сообщения/информации.
теории и здравого смысла. То есть она либо остается прежней, либо уменьшается (мутационная
потери, генетический дрейф, вымирание видов), но редко, а может, и никогда, не наблюдается
увеличиваться в любом информационно значимом смысле.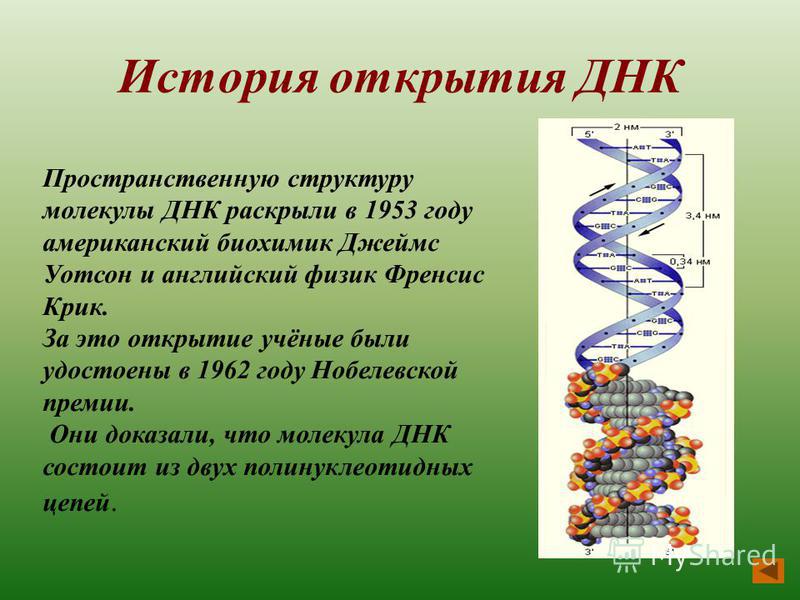
Вывод из наблюдения №2
3. Если бы мы оглянуться назад во времени по линии любого живого населения, т.е. люди (информация в их генетических программах), мы увидели бы общий образец постепенного увеличивайте дальше назад мы идем.
Аксиома
4. Никакая популяция не может быть бесконечно старой или содержать бесконечную информацию. Следовательно:
Вычет из пунктов 3 и 4
5. Должен был быть момент времени, когда первая программа возникла без предшествующей программа — т.е. у первого из этого типа не было родителей.
Дальнейшее наблюдение
6. Информация и сообщения возникают только в уме или в уже существующих сообщениях. Никогда, никогда не видно, чтобы они возникали из спонтанных, неуправляемых законов природы и естественных процессы.
Программы у этих первых представителей каждого типа организмов должны были возникнуть
не в естественном законе, а в уме.
Это полностью согласуется с книгой Бытия, которая учит нас, что программы для каждая из первоначальных «добрых» популяций со всем их огромным вариационным потенциалом, возник из разума Бога в определенный момент времени особым сверхъестественным творением. Эти сообщения, написанные сложным закодированным языком, не могли быть написаны сами по себе. насколько реальная, наблюдательная наука может нам сказать.
Когда первые сообщения были написаны, они также содержали инструкции по созданию механизмов. с помощью которого можно передавать эти сообщения «вниз по линии». ДНК, это чудесное «послание молекула», несет это особое, нематериальное нечто, называемое информацией, вниз через многие поколения, от своего зарождения в разуме Бога.
Точно так же в нашем примере в начале Нед мог прочитать сообщение, которое было отправлено в уме Ала, даже не видя его.
Есть еще один набор посланий от Создателя Бытия, а именно Библия. В
Послание к Римлянам, глава 1, читаем (ст. 18-20),
18-20),
«Ибо открывается гнев Божий с неба на всякое нечестие и неправедность людей, утверждающих истину в неправде; Потому что то, что можно узнать о Боге, проявляется в них; ибо Бог явил это им. Ибо невидимое Его от сотворения мира ясно видно, будучи понятым вещами, которые сделаны, даже его вечная сила и Божество; так что они не имеют оправдания».
Эти стихи кажутся еще более уместными в наши дни, когда мы получили чтобы быть в состоянии расшифровать некоторые биологические языки, написанные на ДНК живыми Слово, Иисус Христос, Логос Творец, в течение тех шести дней творения. Большинство чудесное послание от Логоса, несомненно, Иоанна 3:16, «Ибо так возлюбил Бог мир, что отдал Сына Своего Единородного, дабы всякий верующий в Него не погибнет, но будет иметь жизнь вечную».
Ссылки и примечания
- New Scientist , 26 ноября 1994 г., с. 17. Вернуться к тексту.
- Jérôme Lejeune, Anthropotes (Revista di
studi sulfa persona e la famiglia), Институт Джованни Паоло 11, Рим, 1989, стр. 269-270. Вернуться к тексту.
- Помните, что каждая ячейка содержит общую информацию, т.е. есть несколько копий одного и того же чертежа, по одной в каждой ячейке. двухметровый расстояние достаточно, чтобы указать вас. Вернуться к тексту.
 269-270. Вернуться к тексту.
269-270. Вернуться к тексту.* На самом деле это как если бы были две «нитки бус», идущие параллельно — информация по одному от вашей матери, по другому от вашего отца. Теперь подумайте из этих двух параллельных нитей, разрезанных на 23 части, — это ваши хромосомы. Бусины подобны буквам алфавита, а особый порядок бусинок — это то, что дает информацию. Отдельные фрагменты (или «предложения») информации называются генами. Теоретически каждая ячейка содержит все информация, которая указывает на вас.
(Я в долгу перед Полом Маклафлином из Кентукки за вдохновение и информацию для этой статьи.)
Фейсбук Твиттер Пинтерест Реддит LinkedIn Gmail Приложение электронной почты Распечатать
Нейронная сеть передачи сообщений на основе самоконтроля для прогнозирования молекулярной липофильности и растворимости в воде | Журнал химинформатики
- Научная статья
- Открытый доступ
- Опубликовано:
- Bowen Tang 1,2 ,
- Skyler T. Kramer 2 ,
- Meijuan Fang 1 ,
- Yingkun Qiu 1 ,
- Zhen Wu 1 &
- …
- Донг Сюй ORCID: orcid.org/0000-0002-4809-0514 2
Журнал химинформатики том 12 , Номер статьи: 15 (2020) Процитировать эту статью
9473 Доступы
32 Цитаты
16 Альтметрический
Сведения о показателях
Abstract
Эффективное и точное предсказание молекулярных свойств, таких как липофильность и растворимость, очень желательно для рационального дизайна соединений в химической и фармацевтической промышленности. С этой целью мы создаем и применяем структуру графовой нейронной сети, называемую нейронной сетью передачи сообщений на основе самоконтроля (SAMPN), для изучения взаимосвязи между химическими свойствами и структурами интерпретируемым способом. Основные преимущества SAMPN заключаются в том, что он напрямую использует химические графы и ломает стереотипы многих методов машинного/глубокого обучения. В частности, его механизм внимания указывает степень вклада каждого атома молекулы в интересующее свойство, и эти результаты легко визуализировать. Кроме того, SAMPN превосходит случайные леса и среду глубокого обучения MPN от Deepchem. Кроме того, другая формулировка SAMPN (Multi-SAMPN) может одновременно предсказывать несколько химических свойств с более высокой точностью и эффективностью, чем другие модели, которые предсказывают одно конкретное химическое свойство. Кроме того, SAMPN может генерировать химически видимые и интерпретируемые результаты, которые могут помочь исследователям открывать новые фармацевтические препараты и материалы.
С этой целью мы создаем и применяем структуру графовой нейронной сети, называемую нейронной сетью передачи сообщений на основе самоконтроля (SAMPN), для изучения взаимосвязи между химическими свойствами и структурами интерпретируемым способом. Основные преимущества SAMPN заключаются в том, что он напрямую использует химические графы и ломает стереотипы многих методов машинного/глубокого обучения. В частности, его механизм внимания указывает степень вклада каждого атома молекулы в интересующее свойство, и эти результаты легко визуализировать. Кроме того, SAMPN превосходит случайные леса и среду глубокого обучения MPN от Deepchem. Кроме того, другая формулировка SAMPN (Multi-SAMPN) может одновременно предсказывать несколько химических свойств с более высокой точностью и эффективностью, чем другие модели, которые предсказывают одно конкретное химическое свойство. Кроме того, SAMPN может генерировать химически видимые и интерпретируемые результаты, которые могут помочь исследователям открывать новые фармацевтические препараты и материалы. Исходный код конвейера прогнозирования SAMPN находится в свободном доступе на Github (https://github.com/tbwxmu/SAMPN).
Исходный код конвейера прогнозирования SAMPN находится в свободном доступе на Github (https://github.com/tbwxmu/SAMPN).
Введение
Точное и надежное предсказание молекулярных свойств является важным компонентом проектов по разработке лекарств и химических материалов [1,2,3]. Характеристика количественных взаимосвязей структура-биоактивность/структура-свойство (QSAR/QSPR) соединений всегда была горячей темой в медицинской химии и химии материалов [2, 4], но такие взаимосвязи обычно трудно объяснить с помощью эвристических правил или эмпирических измерений. Методы машинного обучения (ML), такие как случайные леса (RF) и машины опорных векторов (SVM), помогли в процессе открытия новых химических препаратов и материалов [2, 5, 6]. Например, модели случайных лесов с дескрипторами пар атомов использовались многими фармацевтическими компаниями для построения моделей QSAR [7], а модели байесовской оптимизации использовались для проектирования наноструктур для переноса фононов [8]. Однако в последнее время методы, основанные на нейронных сетях, значительно ускорили эту область и будут кратко обсуждены ниже.
Однако в последнее время методы, основанные на нейронных сетях, значительно ускорили эту область и будут кратко обсуждены ниже.
Многие методы машинного обучения сначала преобразуют химические молекулы в интерпретируемое компьютером представление, используя физико-химические свойства из экспериментальных/вычислительных измерений [9] или используя молекулярные отпечатки пальцев. Физико-химические свойства включают массу, заряд, преломление и многие другие физические характеристики молекул. Однако наиболее широко используемым молекулярным преобразованием является молекулярный отпечаток пальца, который кодирует молекулярную структуру в серию двоичных цифр (битовый вектор) [10] на основе субструктур, которые могут быть или не быть заранее определенными, в зависимости от класса. используемых отпечатков пальцев. Например, отпечатки пальцев с расширенным подключением (ECFP) могут разделить одну молекулу на множество подструктур (не заранее определенных) и закодировать их все в один битовый вектор с разными идентификаторами [11]. ENREF_10 В качестве альтернативы битовые векторы могут быть расширены до счетных векторов, которые указывают количество каждой субструктуры, обнаруженной в молекуле, а не только ее присутствие/отсутствие.
ENREF_10 В качестве альтернативы битовые векторы могут быть расширены до счетных векторов, которые указывают количество каждой субструктуры, обнаруженной в молекуле, а не только ее присутствие/отсутствие.
По сравнению с ранее упомянутыми традиционными методами искусственные нейронные сети (ИНС) становятся все более популярными для предсказания молекулярных свойств. Например, трехслойная ИНС с индексами Е-состояния использовалась для предсказания растворимости органических молекул в воде [15]. Совсем недавно для предсказания липофильности и растворимости стали применять сети на основе графов [16]. Эти сетевые модели показали впечатляющие результаты и внесли большой вклад в разработку новых методов.
Правила извлечения фиксированных отпечатков молекул полезны для точного отражения лежащих в их основе химических субструктур, хотя они могут быть не лучшим представлением для всех задач. Следовательно, исследователям приходится тратить много времени и усилий, чтобы тщательно определить, какие функции наиболее важны для их моделей. Это особенно проблематично при использовании физических признаков, для чего могут потребоваться передовые методы выбора переменных или высокий уровень эмпирических знаний. Напротив, некоторые сети глубокого обучения, основанные на кодах упрощенной системы молекулярного ввода (SMILES) [12], могут автоматически изучать молекулярные особенности [13, 14]. Однако это может привести к тому, что модель сосредоточится на грамматике SMILES, а не на предполагаемой молекулярной структуре. Этого ограничения моделей глубокого обучения на основе SMILES трудно избежать, поскольку представление SMILES не предназначено для фиксации молекулярного сходства. Как правило, молекулы с похожей химической структурой могут быть закодированы в очень разные строки SMILES. Как показано на рис. 1A, даже для одной и той же молекулярной структуры часто встречаются неуникальные строки SMILES. Хотя процесс создания канонических SMILES хорошо известен, этот процесс не соответствует набору химических инструментов. Например, «канонический» код SMILES для кофеина: CN1C=NC2=C1C(=O)N(C)C(=O)N2C согласно RDKit, Cn1cnc2c1c(=O)n(C)c(=O)n2C.
Это особенно проблематично при использовании физических признаков, для чего могут потребоваться передовые методы выбора переменных или высокий уровень эмпирических знаний. Напротив, некоторые сети глубокого обучения, основанные на кодах упрощенной системы молекулярного ввода (SMILES) [12], могут автоматически изучать молекулярные особенности [13, 14]. Однако это может привести к тому, что модель сосредоточится на грамматике SMILES, а не на предполагаемой молекулярной структуре. Этого ограничения моделей глубокого обучения на основе SMILES трудно избежать, поскольку представление SMILES не предназначено для фиксации молекулярного сходства. Как правило, молекулы с похожей химической структурой могут быть закодированы в очень разные строки SMILES. Как показано на рис. 1A, даже для одной и той же молекулярной структуры часто встречаются неуникальные строки SMILES. Хотя процесс создания канонических SMILES хорошо известен, этот процесс не соответствует набору химических инструментов. Например, «канонический» код SMILES для кофеина: CN1C=NC2=C1C(=O)N(C)C(=O)N2C согласно RDKit, Cn1cnc2c1c(=O)n(C)c(=O)n2C. согласно Обабелю, и CN1C=NC2=C1C(=O)N(C(=O)N2C)C согласно PubChem.
согласно Обабелю, и CN1C=NC2=C1C(=O)N(C(=O)N2C)C согласно PubChem.
Преобразование химической структуры в математический график. a Химическая структура обычно имеет уникальный график, но несколько строк SMILES. b Список взаимосвязей между индексами узлов и индексами ребер, преобразованными из химического графа. c Списки Node2Edge, Edge2Node, Edge2Revedge и Node2NeiNode, полученные из ( b )
Полноразмерное изображение
Использование естественного химического графика вместо представления SMILES может быть более подходящим для предсказания химических свойств. Вкратце, граф состоит из узлов и ребер, которые соединяют два или более узлов друг с другом. Аналогично химический граф рассматривает атомы как узлы, а связи — как ребра, соединяющие атомы друг с другом. В нашей формулировке эти ребра рассматриваются как двунаправленные, а это означает, что связь, соединяющая атом A с атомом B, такая же, как связь, соединяющая атом B с атомом A.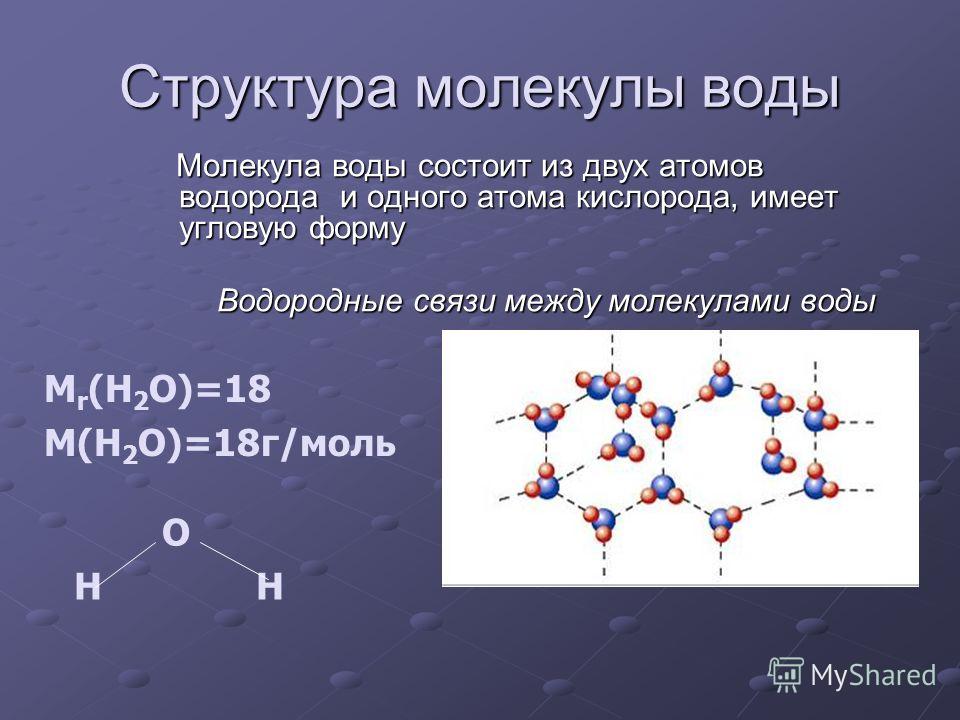 Пример химического графика можно увидеть на рис. 1a.
Пример химического графика можно увидеть на рис. 1a.
Важнейшие химические свойства, такие как молекулярная достоверность, легче представить на двумерных химических графиках, чем на линейных SMILES. В отличие от кодов SMILES, химические графы инвариантны к перестановкам молекул, т. Е. Одна молекулярная структура имеет один граф, но несколько представлений SMILES. Недавно в исследованиях QSAR и QSPR сообщалось о моделях глубокого обучения на основе графов [7, 17, 18, 19, 20, 21]. Однако, согласно этим ссылкам, предсказания трудно интерпретировать, поскольку большинство нейронных сетей действуют как черные ящики [22].
В этой статье мы описываем модель нейронной сети с передачей сообщений на основе самоконтроля (SAMPN), которая является модификацией MPN от Deepchem [16] и является последним словом в области глубокого обучения. Он напрямую изучает наиболее важные особенности каждой задачи QSAR/QSAPR в процессе обучения и присваивает степень важности подструктурам для улучшения интерпретируемости прогноза. Наша графовая сеть SAMPN использует структуру химического графа, описанную выше, где каждое ребро является производным от химической связи, а каждый атом является узлом. Как нашу нейронную сеть передачи сообщений (MPN), так и модель SAMPN можно использовать в качестве многоцелевых моделей (Multi-MPN или Multi-SAMPN), которые могут изучать не только взаимосвязь между химическими структурами и свойствами, но и взаимосвязь между внутренними атрибутами. молекул. Чтобы продемонстрировать наши вычислительные методы, мы выбрали липофильность и растворимость в воде в качестве целевых свойств, поскольку они были очень важными химическими дескрипторами, которые проникают во все аспекты биологической активности, метаболизма лекарств и фармакокинетических (DMPK) профилей [23].
Наша графовая сеть SAMPN использует структуру химического графа, описанную выше, где каждое ребро является производным от химической связи, а каждый атом является узлом. Как нашу нейронную сеть передачи сообщений (MPN), так и модель SAMPN можно использовать в качестве многоцелевых моделей (Multi-MPN или Multi-SAMPN), которые могут изучать не только взаимосвязь между химическими структурами и свойствами, но и взаимосвязь между внутренними атрибутами. молекул. Чтобы продемонстрировать наши вычислительные методы, мы выбрали липофильность и растворимость в воде в качестве целевых свойств, поскольку они были очень важными химическими дескрипторами, которые проникают во все аспекты биологической активности, метаболизма лекарств и фармакокинетических (DMPK) профилей [23].
Насколько нам известно, такая модель, как SAMPN, впервые использовалась для предсказания химических свойств на основе экспериментальных данных для исследований QSPR. Результаты наших экспериментов показывают, что наша сеть SAMPN обеспечивает превосходную производительность по сравнению с традиционными моделями на основе машинного обучения и предыдущими моделями глубокого обучения (например, MPN от Deepchem [16]). Кроме того, прогнозы SAMPN легко понять и визуализировать, поскольку механизм интегрированного внимания может окрашивать атомы молекулы в зависимости от их вклада в интересующее свойство.
Кроме того, прогнозы SAMPN легко понять и визуализировать, поскольку механизм интегрированного внимания может окрашивать атомы молекулы в зависимости от их вклада в интересующее свойство.
Методы и материалы
Наборы данных и обработка данных
Наборы данных молекулярной липофильности и растворимости в воде использовались для разработки и тестирования нашего метода. Липофильность обычно количественно определяется коэффициентом распределения n -октанол/вода P и предпочтительно отображается в логарифмической форме как logP. Необработанные данные о липофильности были загружены из CHEMBL3301361, депонированного AstraZeneca [24], и включают 4200 молекул. Растворимость в воде — это насыщенная концентрация химического вещества в водной фазе, которая обычно отображается в единицах log (моль/л) и представляется как logS. Этот набор данных был загружен из онлайн-базы данных химических веществ и среды моделирования (OCHEM) [25] и включает 1311 экспериментальных записей. Распределения наборов данных представлены в дополнительном файле 1: рис. S1.
Распределения наборов данных представлены в дополнительном файле 1: рис. S1.
Поскольку оба набора данных малы по сравнению с типичными требованиями к размеру моделей глубокого обучения, мы используем десятикратную стратифицированную перекрестную проверку [13, 23, 35], где каждый набор данных был случайным образом разделен на набор для обучения и проверки (80% и 10 % соответственно) для выбора параметров и тестового набора данных (10%) для сравнения моделей. Затем мы повторили все эксперименты три раза с разными случайными начальными значениями. Этот процесс гарантирует, что модель не просто запоминает обучение, а способна обобщать новые молекулы.
Для предварительной обработки исходных данных были удалены повторяющиеся молекулы, чтобы каждая химическая структура в данных была уникальной, при этом максимально одно из связанных свойств было сохранено. Молекулы, не распознаваемые RDkit (версия 2019.3) [26], набором инструментов для хемоинформатики, реализованным на Python, также были удалены. Только два столбца («улыбки» и «экспериментальное значение») были сохранены в качестве входных данных для наших моделей. Каждое загруженное представление SMILES затем преобразовывалось в ориентированный граф перед обучением модели SAMPN с использованием кодировщика MPN, адаптированного из Deepchem и Chemprop [27, 28]. Ориентированные графы в основном состояли из индексных списков узлов и ребер, показанных на рис. 1c. Возьмем в качестве примера подструктуру N–C: химическая связь между атомами N и C может дать два ребра (C:0 → N:1 и N:0 → C:1). Количество узлов равно количеству атомов, а количество ребер всегда удвоено количеством связей, поскольку мы считаем ребра двунаправленными.
Только два столбца («улыбки» и «экспериментальное значение») были сохранены в качестве входных данных для наших моделей. Каждое загруженное представление SMILES затем преобразовывалось в ориентированный граф перед обучением модели SAMPN с использованием кодировщика MPN, адаптированного из Deepchem и Chemprop [27, 28]. Ориентированные графы в основном состояли из индексных списков узлов и ребер, показанных на рис. 1c. Возьмем в качестве примера подструктуру N–C: химическая связь между атомами N и C может дать два ребра (C:0 → N:1 и N:0 → C:1). Количество узлов равно количеству атомов, а количество ребер всегда удвоено количеством связей, поскольку мы считаем ребра двунаправленными.
Сетевой кодировщик передачи сообщений
Впервые вместо ручного выбора признаков прямое использование структур молекулярного графа было сообщено в 1994 году [29]. В последние годы методы на основе графов используются для анализа различных аспектов химических систем [14, 30] и сравнения с отпечатками пальцев [31]. Модели на основе графов обеспечивают естественный способ описания химических молекул, где атомы в молекуле эквивалентны узлам, а химические связи — ребрам графа. Сеть передачи сообщений представляет собой вариант теоретико-графового подхода, который постепенно объединяет информацию от удаленных атомов, расширяясь радиально через связи, как показано на рис. 2. Эти передаваемые сообщения использовались для кодирования всех подструктур молекулы с помощью адаптивного обучения. подход, который извлекает полезные представления молекул, подходящие для целевых прогнозов.
Модели на основе графов обеспечивают естественный способ описания химических молекул, где атомы в молекуле эквивалентны узлам, а химические связи — ребрам графа. Сеть передачи сообщений представляет собой вариант теоретико-графового подхода, который постепенно объединяет информацию от удаленных атомов, расширяясь радиально через связи, как показано на рис. 2. Эти передаваемые сообщения использовались для кодирования всех подструктур молекулы с помощью адаптивного обучения. подход, который извлекает полезные представления молекул, подходящие для целевых прогнозов.
Представление архитектуры SAMPN. Основная часть кодировщика MPN преобразует соседние признаки в молекулярную матрицу, затем следует уровень самоконтроля и полностью подключенные сети для окончательного прогноза . (1–3). Прохождение сообщения M от атома x до атома y в d -й итерации (глубина прохождения сообщения) рассчитывается следующим образом: 9{d — 1} } } \right)$$
(2)
Здесь Re — функция активации (Relu). в нейронной сети, как описано нейронной сетью. уравнение (1). Полноразмерная таблица В химическом графе атомы обозначают набор узлов x∈V, , а связи обозначают набор ребер (x,y)∈E. Каждое ребро имеет свое направление в модели SAMPN. N(x) или N(y) обозначает группу соседних узлов x или y соответственно. (3) где \(h_{y}\) фиксирует особенности локальной химической структуры на основе глубины прохождения, а \(W_{o} \) и \(W_{ah}\) — изученные весовые матрицы. Более подробную информацию об алгоритме SAMPN можно найти в дополнительном файле 1: таблица S1 во вспомогательных материалах. Все скрытые состояния узла напрямую объединяются в единый вектор, что может не объяснять разницу между изученными признаками [32]. Лучший способ — применить механизм внимания для получения вектора контекста для целевого узла, сосредоточив внимание на его соседях и локальной среде. Возьмем в качестве примера узел 2 (синий узел на рис. 2). После нескольких шагов передачи сообщений узел 2 имеет скрытое состояние h 9.0296 2  \(W_{inp}\) и \(W_{h}\) — матрицы изученных весов. Поскольку для передачи сообщения мы используем зависимую от ребра нейронную сеть, функция узла f x объединяется с функцией ребра f xy для формирования объединенной функции узла-ребра f 3 x f xy . Функция узла 9{d = 1}\), который x отправляет на y , генерируется из объединенной функции узла-ребра f x f xy
\(W_{inp}\) и \(W_{h}\) — матрицы изученных весов. Поскольку для передачи сообщения мы используем зависимую от ребра нейронную сеть, функция узла f x объединяется с функцией ребра f xy для формирования объединенной функции узла-ребра f 3 x f xy . Функция узла 9{d = 1}\), который x отправляет на y , генерируется из объединенной функции узла-ребра f x f xy \(z \in N\left( x \right)\backslash y\) означает, что соседи x не содержат y . Узлу x разрешено отправлять сообщение соседнему узлу y только после того, как узел x получил сообщения от всех соседних узлов, кроме y . Мы используем пропущенное соединение на этапах передачи сообщений, как показано на рис. 2 (отображается между соседними функциями и собственными функциями). Это соединение с пропуском позволяет сообщению проходить очень большое расстояние без устранения проблемы градиента при использовании обратного распространения. Сгенерированные сообщения обмениваются и обновляются на основе объединенной функции узла и края и предыдущего шага передачи сообщений, как в уравнении. (2) определено. 9{d} } } \right)} \right)$$
\(z \in N\left( x \right)\backslash y\) означает, что соседи x не содержат y . Узлу x разрешено отправлять сообщение соседнему узлу y только после того, как узел x получил сообщения от всех соседних узлов, кроме y . Мы используем пропущенное соединение на этапах передачи сообщений, как показано на рис. 2 (отображается между соседними функциями и собственными функциями). Это соединение с пропуском позволяет сообщению проходить очень большое расстояние без устранения проблемы градиента при использовании обратного распространения. Сгенерированные сообщения обмениваются и обновляются на основе объединенной функции узла и края и предыдущего шага передачи сообщений, как в уравнении. (2) определено. 9{d} } } \right)} \right)$$ Применяя приведенные выше уравнения. (1–3) на химическом графе генерирует окончательное представление графа G = { h 1 … h i … h n }, который в сочетании с механизмом самоконтроля и полностью подключенными нейронными сетями позволяет сделать окончательный прогноз.
Применяя приведенные выше уравнения. (1–3) на химическом графе генерирует окончательное представление графа G = { h 1 … h i … h n }, который в сочетании с механизмом самоконтроля и полностью подключенными нейронными сетями позволяет сделать окончательный прогноз. Механизм внутреннего внимания
 Поскольку разные субструктуры вносят разный вклад в молекулярное свойство, мы можем использовать механизм внимания, чтобы зафиксировать различное влияние субструктур на целевое молекулярное свойство.
Поскольку разные субструктуры вносят разный вклад в молекулярное свойство, мы можем использовать механизм внимания, чтобы зафиксировать различное влияние субструктур на целевое молекулярное свойство.
Затем добавляется слой самоконтроля для определения взаимосвязи между вкладом подструктуры в целевое свойство молекулы. Алгоритм внимания с точечным произведением был реализован для получения всего представления молекулярного графа G в качестве входных данных. Вложение графа взвешенной молекулы с автоматическим вниманием может быть сформировано следующим образом: 9{T} } \right)$$
(4)
$$E_{G} = W_{att} \cdot G$$
(5)
где W att оценка собственного внимания, которая неявно указывает на вклад локального химического графа в целевое свойство. As G = { h 1 … h i … h n }, each row of W att is the attention weight between i -й атом и остальные атомы в молекуле. E G — матрица внимательного вложения, где каждая строка соответствует взвешенному по вниманию скрытому вектору узла. Затем глобальное среднее объединение используется для суммы G и E G , чтобы получить скрытый вектор молекулы, как показано на рис. 2 в фиолетовом прямоугольнике. Наконец, скрытый вектор объединяется с несколькими слоями полносвязных сетей для предсказания целевого свойства.
E G — матрица внимательного вложения, где каждая строка соответствует взвешенному по вниманию скрытому вектору узла. Затем глобальное среднее объединение используется для суммы G и E G , чтобы получить скрытый вектор молекулы, как показано на рис. 2 в фиолетовом прямоугольнике. Наконец, скрытый вектор объединяется с несколькими слоями полносвязных сетей для предсказания целевого свойства.
Обучение модели и оптимизация гиперпараметров
Код для кодировщика MPN был в основном адаптирован из Deepchem и Chemprop [27, 28]. И кодировщик MPN, и механизм самоконтроля были реализованы с помощью Python и Pytorch версии 1.0, фреймворка с открытым исходным кодом для глубокого обучения [33]. Модели MPN, Multi-MPN, SAMPN и Multi-SAMPN обучались с помощью оптимизатора Adam с использованием того же графика скорости обучения, что и в [34].
Для оценки эффективности наших моделей использовались несколько показателей: средняя абсолютная ошибка (MAE), среднеквадратическая ошибка (RMSE), среднеквадратическая ошибка (MSE), коэффициент детерминации (R 2 ) и коэффициент корреляции Пирсона (ПК). Более низкие значения MAE, MSE и RMSE указывают на лучшую прогностическую эффективность. И наоборот, более высокие значения для PC и R 2 указывают на лучшие модели или лучшее соответствие данным. Хотя некоторые из этих метрик говорят об одном и том же, включение всех этих значений может стать хорошим эталоном для будущих исследований.
Более низкие значения MAE, MSE и RMSE указывают на лучшую прогностическую эффективность. И наоборот, более высокие значения для PC и R 2 указывают на лучшие модели или лучшее соответствие данным. Хотя некоторые из этих метрик говорят об одном и том же, включение всех этих значений может стать хорошим эталоном для будущих исследований.
Алгоритм поиска по сетке использовался для настройки гиперпараметров с помощью пакета Hyperopt версии 0.1.2 [35]. В таблице 2 показаны гиперпараметры, которые необходимо оптимизировать, и область поиска. Мы выбрали RMSE в проверочном наборе в качестве метрики, чтобы найти наиболее подходящую комбинацию гиперпараметров в пространстве поиска. В задаче липофильность-QSPR одной из лучших комбинаций гиперпараметров была {‘активация’: ‘ReLU’; «глубина»: 4; «выпадение»: 0,25; «уровни полносвязных сетей»: 2; «скрытый размер»: 384}. Все модели нейронных сетей с передачей сообщений (MPN, SAMPN, Multi-MPN и Multi-SAMPN) использовали вышеуказанные гиперпараметры для проверки окончательной производительности с использованием десятикратной стратифицированной перекрестной проверки всего набора данных.
Полноразмерная таблица
В дополнение к использованию опубликованных результатов MPN Deepchem мы также построили чистую модель MPN, чтобы установить базовый уровень без собственного внимания, и все остальные конфигурации были сохранил то же самое для SAMPN. Чтобы сравнить однозадачную и многоцелевую сеть глубокого обучения, мы создали мульти-MPN и мульти-SAMPN. В многоцелевой модели использовался объединенный набор молекулярных данных из разделов «Липофильность» и «Растворимость в воде», как описано во вспомогательных материалах. Все используемые параметры оставались одинаковыми между MPN и SAMPN.
Случайный лес
Чтобы сравнить наш метод SAMPN с традиционными методами машинного обучения, мы выбрали модель случайного леса в качестве основы. Случайный лес (RF) [36] — это контролируемый алгоритм обучения с ансамблем деревьев решений, сгенерированных из бутстрепной (пакетной) выборки соединений и признаков. Он широко используется в традиционных исследованиях связи структура-свойство [37] и считается «золотым стандартом» благодаря своей надежности, простоте использования и высокой точности прогнозирования в исследованиях связи структура-свойство [38]. Здесь использовалась ECFP с фиксированной длиной 1024 [12] с моделью RF, которая была реализована в Python 3.6.3 [39].] с пакетом Scikit-learn, версия 0.21.2 [40]. Для модели RF большее количество деревьев обычно повышает производительность и делает прогнозы более стабильными, но также сильно замедляет вычисления. Мы установили 500 деревьев для хорошей точки баланса, как это было предложено в [16] для большинства исследований QSPR.
Он широко используется в традиционных исследованиях связи структура-свойство [37] и считается «золотым стандартом» благодаря своей надежности, простоте использования и высокой точности прогнозирования в исследованиях связи структура-свойство [38]. Здесь использовалась ECFP с фиксированной длиной 1024 [12] с моделью RF, которая была реализована в Python 3.6.3 [39].] с пакетом Scikit-learn, версия 0.21.2 [40]. Для модели RF большее количество деревьев обычно повышает производительность и делает прогнозы более стабильными, но также сильно замедляет вычисления. Мы установили 500 деревьев для хорошей точки баланса, как это было предложено в [16] для большинства исследований QSPR.
Результаты и обсуждение
Предсказание липофильности и растворимости
В каждой задаче QSPR мы построили модели RF, MPN, SAMPN, мульти-MPN и мульти-SAMPN для изучения взаимосвязи между целевым свойством и молекулярной структурой. Для предсказания липофильности как модель, основанная на одной цели, так и модель, основанная на множестве целей, имеют хорошую производительность в соответствии с RMSE (SAMPN: 0,579). ± 0,036; Мульти-SAMPN: 0,571 ± 0,032). Без механизма внутреннего внимания производительность MPN снизилась, как показано в таблице 3 и на рис. 3a. Тем не менее, результат нашей новой формулировки MPN или Multi-MPN был все еще намного лучше, чем результат MPN версии Deepchem (0,719 ± 0,031) [16], а производительность увеличилась еще больше с включением механизма внимания. Наша модель MPN отличается от Deepchem тем, что мы не использовали рекуррентные нейронные сети (RNN) в нашей сетевой архитектуре, что повысило скорость нашей модели MPN при обучении.
± 0,036; Мульти-SAMPN: 0,571 ± 0,032). Без механизма внутреннего внимания производительность MPN снизилась, как показано в таблице 3 и на рис. 3a. Тем не менее, результат нашей новой формулировки MPN или Multi-MPN был все еще намного лучше, чем результат MPN версии Deepchem (0,719 ± 0,031) [16], а производительность увеличилась еще больше с включением механизма внимания. Наша модель MPN отличается от Deepchem тем, что мы не использовали рекуррентные нейронные сети (RNN) в нашей сетевой архитектуре, что повысило скорость нашей модели MPN при обучении.
Полноразмерная таблица
Рис. 3 , d ) с той же десятикратной стратифицированной перекрестной проверкой. Столбики погрешностей представляют собой стандартные отклоненияПолноразмерное изображение
Для предсказания растворимости сети на основе передачи сообщений также значительно улучшили производительность по сравнению с традиционной моделью (RF), как показано в таблице 3 и на рис. 3b. MPN от Deepchem также продемонстрировал хорошую производительность (0,580 ± 0,030 RMSD) при прогнозировании растворимости в воде [16]; однако они использовали небольшой набор данных о растворимости в воде (1128 молекул). В целях сравнения мы использовали их настройку MPN по умолчанию (Deepchem) для наших данных о растворимости в воде (1311 молекул) с нашим протоколом стратифицированной перекрестной проверки. Скрипты процесса расчета деталей были доступны в нашем репозитории Github. После этого MPN (Deepchem) показывает аналогичные показатели (0,676 ± 0,022) с нашим MPN (0,694 ± 0,050). Основываясь на результатах нашей модели (производительность: SAMPN > MPN; Multi-SAMPN > Multi-MPN), механизм самоконтроля может повысить производительность нейронных сетей передачи сообщений как в прогнозировании липофильности, так и растворимости. И многоцелевые модели имеют лучшую производительность, чем модели, основанные на одной задаче (производительность: Multi-SAMPN > SAMPN; Multi-MPN > MPN). В нашем исследовании, независимо от того, какой показатель показан на рис.
3b. MPN от Deepchem также продемонстрировал хорошую производительность (0,580 ± 0,030 RMSD) при прогнозировании растворимости в воде [16]; однако они использовали небольшой набор данных о растворимости в воде (1128 молекул). В целях сравнения мы использовали их настройку MPN по умолчанию (Deepchem) для наших данных о растворимости в воде (1311 молекул) с нашим протоколом стратифицированной перекрестной проверки. Скрипты процесса расчета деталей были доступны в нашем репозитории Github. После этого MPN (Deepchem) показывает аналогичные показатели (0,676 ± 0,022) с нашим MPN (0,694 ± 0,050). Основываясь на результатах нашей модели (производительность: SAMPN > MPN; Multi-SAMPN > Multi-MPN), механизм самоконтроля может повысить производительность нейронных сетей передачи сообщений как в прогнозировании липофильности, так и растворимости. И многоцелевые модели имеют лучшую производительность, чем модели, основанные на одной задаче (производительность: Multi-SAMPN > SAMPN; Multi-MPN > MPN). В нашем исследовании, независимо от того, какой показатель показан на рис. 3, мы можем сделать тот же вывод, что и выше. Более высокая прогностическая эффективность модели с несколькими мишенями, вероятно, обусловлена тем преимуществом, что Multi-SAMPN или Multi-MPN могут использовать изученную функцию липофильности, чтобы помочь в прогнозировании растворимости, и наоборот. Стоит отметить, что Multi-SAMPN или Multi-MPN могут прогнозировать липофильность и растворимость в воде одновременно, а не пошагово, как SAMPN или MPN. Хотя наш случай показывает, что модель с несколькими мишенями работает лучше, чем модель с одной целью, требуются дополнительные исследования, чтобы показать, является ли это общим, поскольку в нашем случае использовался только один набор данных липофильности и растворимости в воде.
3, мы можем сделать тот же вывод, что и выше. Более высокая прогностическая эффективность модели с несколькими мишенями, вероятно, обусловлена тем преимуществом, что Multi-SAMPN или Multi-MPN могут использовать изученную функцию липофильности, чтобы помочь в прогнозировании растворимости, и наоборот. Стоит отметить, что Multi-SAMPN или Multi-MPN могут прогнозировать липофильность и растворимость в воде одновременно, а не пошагово, как SAMPN или MPN. Хотя наш случай показывает, что модель с несколькими мишенями работает лучше, чем модель с одной целью, требуются дополнительные исследования, чтобы показать, является ли это общим, поскольку в нашем случае использовался только один набор данных липофильности и растворимости в воде.
Визуализация внимания
Хотя всегда желательна более высокая точность предсказания, также важна способность интерпретировать модель QSPR. Сравнение и интерпретация моделей могут быть облегчены с помощью метода визуализации, позволяющего идентифицировать изученные функции, которые определяют предсказания составных свойств. В модели SAMPN мы можем получить оценки веса внимания из механизма само-внимания. Для конкретной молекулы мы получаем разницу между весом каждого атома и средним весом внимания молекулы. Мы определяем вышеуказанную разницу как коэффициент внимания каждого атома, и эти весовые коэффициенты внимания очень полезны для понимания того, какие части молекулы увеличивают целевое молекулярное свойство, а какие уменьшают его.
В модели SAMPN мы можем получить оценки веса внимания из механизма само-внимания. Для конкретной молекулы мы получаем разницу между весом каждого атома и средним весом внимания молекулы. Мы определяем вышеуказанную разницу как коэффициент внимания каждого атома, и эти весовые коэффициенты внимания очень полезны для понимания того, какие части молекулы увеличивают целевое молекулярное свойство, а какие уменьшают его.
Используя цветовую карту интенсивности для каждой молекулы (например, на рис. 4a–f), легко увидеть, какие части молекулы играют более важную роль в липофильности или растворимости молекулы в воде. Тепловые карты липофильности и растворимости помогают химикам оптимизировать липофильность и растворимость конкретной молекулы. Рассмотрим рис. 4b, изображение 1H-индазола после использования нашей модели. Эта молекула обладает относительно высокой липофильностью, поскольку она имеет большую π-электронно-сопряженную систему в своем конденсированном ароматическом кольце. Однако азотсодержащий участок молекулы проявляет сильные антилипофильные свойства по сравнению с остальной частью молекулы. Частично это может быть связано с вкладом азота (как «N» или «NH») в сеть водородных связей с его окружением. Таким образом, изменение 1H-индазола для разрушения этой потенциальной сети может увеличить липофильность молекулы. Чтобы проверить эту гипотезу, мы использовали SAMPN для предсказания липофильности бензо[ d ]изотиазол (дополнительный файл 1: рис. S2), молекула, полученная путем замены «NH» 1H-индазола на «S» (сера). Как и ожидалось, это изменение действительно увеличило липофильность молекулы. Другим примером является первичная аминогруппа на рис. 4f, которая может легко образовывать водородные связи с молекулами воды. Это отражено красным цветом для прогнозируемого растворимого признака.
Частично это может быть связано с вкладом азота (как «N» или «NH») в сеть водородных связей с его окружением. Таким образом, изменение 1H-индазола для разрушения этой потенциальной сети может увеличить липофильность молекулы. Чтобы проверить эту гипотезу, мы использовали SAMPN для предсказания липофильности бензо[ d ]изотиазол (дополнительный файл 1: рис. S2), молекула, полученная путем замены «NH» 1H-индазола на «S» (сера). Как и ожидалось, это изменение действительно увеличило липофильность молекулы. Другим примером является первичная аминогруппа на рис. 4f, которая может легко образовывать водородные связи с молекулами воды. Это отражено красным цветом для прогнозируемого растворимого признака.
Окраска молекул тепловой карты на липофильность ( a – c ) и растворимость ( d – ф ). a – c Красный цвет указывает на прогнозируемое антилипофильное свойство, а синий цвет указывает на прогнозируемое липофильное свойство. d – f Красный цвет указывает на прогнозируемую разрешимую функцию, а синий указывает на прогнозируемую антирастворимую функцию
d – f Красный цвет указывает на прогнозируемую разрешимую функцию, а синий указывает на прогнозируемую антирастворимую функцию
Изображение в натуральную величину выявление взаимосвязи между молекулярной липофильностью/растворимостью и структурой. Наша модель SAMPN превосходит обычные случайные леса и предыдущую модель на основе графовой нейронной сети. Применяя механизм внимания, SAMPN может дать некоторое представление об атомарных источниках липофильности/растворимости, что отличается от подходов черного ящика, используемых в большинстве методов машинного обучения и глубокого обучения. Результаты SAMPN легко понять, раскрасив баллы внимания непосредственно на молекулярном графике, что полезно в качестве ориентира для настройки липофильности или растворимости одной молекулы. Кроме того, наши нейронные сети, передающие сообщения, можно легко обучить как многоцелевую модель, что повышает ее вычислительную эффективность и производительность прогнозирования. Мы считаем, что с помощью этого подхода и нашего тематического исследования наш метод может быть применен к другим количественным исследованиям взаимосвязей между структурой и свойствами и поможет химикам оптимизировать молекулярные свойства непосредственно из химических структур.
Наличие данных и материалов
Все наборы данных и код доступны на GitHub: https://github.com/tbwxmu/SAMPN.
Ссылки
Хансен К., Биглер Ф., Рамакришнан Р., Пронобис В., фон Лилиенфельд О.А., Мюллер К.Р., Ткатченко А. (2015) Прогнозирование молекулярных свойств с помощью машинного обучения: точные многочастичные потенциалы и нелокальность в химическом пространстве . J Phys Chem Lett 6:2326–2331
Статья КАС пабмед ПабМед Центральный Google ученый
Черкасов А., Муратов Е.Н., Фурш Д., Варнек А., Баскин И.И., Кронин М., Дирден Дж., Граматика П., Мартин Ю.С., Тодескини Р. (2014) Моделирование Qsar: где ты был? Куда вы собираетесь? J Med Chem 57:4977–5010
Статья КАС пабмед ПабМед Центральный Google ученый
Le T, Epa VC, Burden FR, Winkler DA (2012) Количественное моделирование взаимосвязи структура-свойство свойств различных материалов. Chem Rev 112:2889–2919
Статья КАС пабмед Google ученый
Гомес-Бомбарелли Р., Агилера-Ипаррагирре Дж., Хирзель Т.Д., Дювено Д., Маклорен Д., Блад-Форсайт М.А., Чае Х.С., Айнзингер М., Ха Д.Г., Ву Т. (2016) Разработка эффективного молекулярно-органического светоизлучающего диоды с помощью высокопроизводительного виртуального скрининга и экспериментального подхода. Нат Матер 15:1120
Артикул пабмед Google ученый
Манноди-Канаккитоди А.
, Пилания Г., Хуан Т.Д., Лукман Т., Рампрасад Р. (2016)Стратегия машинного обучения для ускоренного проектирования полимерных диэлектриков. Научный представитель 6:20952Статья пабмед ПабМед Центральный Google ученый
Файнберг Э.Н., Шеридан Р., Джоши Э., Панде В.С., Ченг А.С. (2019) Ступенчатое улучшение прогнозирования Admet с помощью глубокой функционализации Potentialnet. Препринт arXiv arXiv: 1789
Джу С., Шига Т., Фэн Л., Хоу З., Цуда К., Шиоми Дж. (2017) Проектирование наноструктур для переноса фононов с помощью байесовской оптимизации. Физическая версия X 7:021024
Google ученый
Hansch C, Maloney PP, Fujita T, Muir RM (1962) Корреляция биологической активности феноксиуксусных кислот с константами заместителей Гаммета и коэффициентами распределения. Природа 194:178
Артикул КАС Google ученый
Роджерс Д., Хан М. (2010) Отпечатки пальцев с расширенными возможностями подключения. J Chem Inf Model 50:742–754
Артикул КАС пабмед Google ученый
Weininger D (1988) Smiles, химический язык и информационная система. 1. Введение в методологию и правила кодирования. J Chem Inf Comput Sci. 28:31–36
Статья КАС Google ученый
Оливекрона М., Блашке Т., Энгквист О., Чен Х. (2017) Молекулярный дизайн de novo с помощью глубокого обучения с подкреплением. Журнал химинформатики 9:48
Статья пабмед ПабМед Центральный Google ученый
Тетко И.В., Танчук В.Ю., Кашева Т.Н., Вилла А.Е. (2001) Оценка растворимости химических соединений в воде с использованием индексов Е-состояния. J Chem Inf Comput Sci 41:1488–1493
Статья КАС пабмед Google ученый
Ву З., Рамсундар Б., Файнберг Э.Н., Гомес Дж., Джениесс С., Паппу А.С., Лесвинг К., Панде В. (2018) Moleculenet: эталон для молекулярного машинного обучения. Chem Sci 9:513–530
Статья КАС пабмед Google ученый
Рети Т., Шарафдини Р., Дрегели-Кисс А., Хагбин Х. (2018) Индексы неравномерности графика, используемые в качестве молекулярных дескрипторов в исследованиях qspr.
MATCH Commun Math Comput Chem 79: 509–524Google ученый
Саркар Д., Шарма С., Мухопадхьяй С., Ботра А.К. (2016) Qsar Исследования ингибиторов Fabh с использованием теоретико-графовых и квантово-химических дескрипторов. Pharmacophore 7
Shao Z, Hirayama Y, Yamanishi Y, Saigo H (2015) Извлечение дискриминационных шаблонов из графических данных с несколькими метками и их применение к моделям количественного соотношения структура-активность (Qsar). J Chem Inf Model 55:2519–2527
Артикул КАС пабмед Google ученый
Wang X, Li Z, Jiang M, Wang S, Zhang S, Wei Z (2019) Прогноз свойств молекулы на основе встраивания пространственного графа. J Chem Inf Model 59:3817–3828
Артикул КАС пабмед Google ученый
Liu K, Sun X, Jia L, Ma J, Xing H, Wu J, Gao H, Sun Y, Boulnois F, Fan J (2019) Chemi-Net: сверточная сеть на молекулярном графе для точного прогнозирования свойств лекарств .
Int J Mol Sci 20: 3389Артикул КАС ПабМед Центральный Google ученый
Гулон А., Пико Т., Дюпра А., Дрейфус Г. (2007) Прогнозирование действий без вычислительных дескрипторов: графовые машины для Qsar. SAR QSAR Environ Res 18:141–153
Статья КАС пабмед Google ученый
Arnott JA, Planey SL (2012) Влияние липофильности на открытие и разработку лекарств. Экспертное заключение по наркотикам Discov 7:863–875
Артикул КАС пабмед Google ученый
АстраЗенека. Экспериментальные in vitro Dmpk и физико-химические данные по ряду общедоступных соединений (2016 г.) https://doi.org/10.6019/Chembl3301361
Сушко И., Новотарский С., Кёрнер Р., Пандей А.К., Рупп М., Титц В., Брандмайер С.
, Абдельазиз А., Прокопенко В.В., Танчук В.Ю. и др. (2011) Онлайн-среда химического моделирования (Ochem): веб-платформа для данных хранение, разработка моделей и публикация химической информации. J Computed Aided Mol Des 25: 533–554Артикул КАС пабмед ПабМед Центральный Google ученый
Landrum G. Rdkit: cheminformatics с открытым исходным кодом (2006)
Ramsundar B, Eastman P, Walters P, Pande V (2019) Глубокое обучение для наук о жизни: применение глубокого обучения к геномике, микроскопии, лекарствам открытие и многое другое. O’Reilly Media, Inc., Ньютон
Google ученый
Ян К., Суонсон К., Джин В., Коли К.В., Эйден П., Гао Х., Гусман-Перес А., Хоппер Т., Келли Б., Матеа М. (2019) Анализ изученных молекулярных представлений для прогнозирования свойств. Модель J Chem Inf.
59:3370–3388Статья КАС пабмед ПабМед Центральный Google ученый
Киреев Д.Б. (1995) Chemnet: новый метод на основе нейронных сетей для сопоставления графов/свойств. J Chem Inf Comput Sci 35:175–180
Статья КАС Google ученый
Coley CW, Jin W, Rogers L, Jamison TF, Jaakkola TS, Green WH, Barzilay R, Jensen KF (2019) Модель графовой сверточной нейронной сети для прогнозирования химической реактивности. Chem Sci 10:370–377
Статья КАС пабмед Google ученый
Кернс С., Макклоски К., Берндл М., Панде В., Райли П. (2016)Свертки молекулярного графа: выход за рамки отпечатков пальцев. J Computed Aided Mol Des 30: 595–608
Артикул КАС пабмед ПабМед Центральный Google ученый
Пашке А., Гросс С., Чинтала С., Чанан Г. (2017) Pytorch: тензоры и динамические нейронные сети в питоне с сильным ускорением графического процессора. PyTorch: тензоры и динамические нейронные сети на питоне с сильным ускорением графического процессора. 6
Васвани А., Шазир Н., Пармар Н., Ушкорейт Дж., Джонс Л., Гомес А.Н., Кайзер Л., Полосухин И. (2017) Внимание — это все, что вам нужно. В: Достижения в нейронных системах обработки информации. стр. 5998–6008.
Бергстра Дж., Комер Б., Элиасмит С., Яминс Д., Кокс Д.Д. (2015) Hyperopt: библиотека Python для выбора модели и оптимизации гиперпараметров. Comput Sci Discov 8:014008
Статья Google ученый
Полищук П. (2017) Интерпретация моделей количественных отношений структура-активность: прошлое, настоящее и будущее. J Chem Inf Model 57:2618–2639
Артикул КАС пабмед Google ученый
Ма Дж., Шеридан Р.П., Лиав А., Даль Г.Э., Светник В. (2015)Глубокие нейронные сети как метод количественных взаимосвязей структура-активность. J Chem Inf Model 55:263–274
Артикул КАС пабмед Google ученый
Oliphant TE (2007) Python для научных вычислений. Comput Sci Eng 9:10–20
Статья КАС Google ученый
Педрегоса Ф., Вароко Г., Грамфор А., Мишель В., Тирион Б., Гризель О.
, Блондель М., Преттенхофер П., Вайс Р., Дюбург В. (2011)Scikit-learn: машинное обучение в Python. J Mach Learn Res 12: 2825–2830Google ученый
 «>
«>Чен Х., Энгквист О., Ван Ю., Оливекрона М., Блашке Т. (2018) Развитие глубокого обучения при открытии лекарств. Наркотики Discov Сегодня 23: 1241–1250
ПабМед Google ученый
 , Пилания Г., Хуан Т.Д., Лукман Т., Рампрасад Р. (2016)Стратегия машинного обучения для ускоренного проектирования полимерных диэлектриков. Научный представитель 6:20952
, Пилания Г., Хуан Т.Д., Лукман Т., Рампрасад Р. (2016)Стратегия машинного обучения для ускоренного проектирования полимерных диэлектриков. Научный представитель 6:20952 «>
«>Riniker S, Landrum GA (2013) Платформа с открытым исходным кодом для сравнительного анализа отпечатков пальцев для виртуального скрининга на основе лигандов. Ж Хеминформ 5:26
Статья КАС пабмед ПабМед Центральный Google ученый
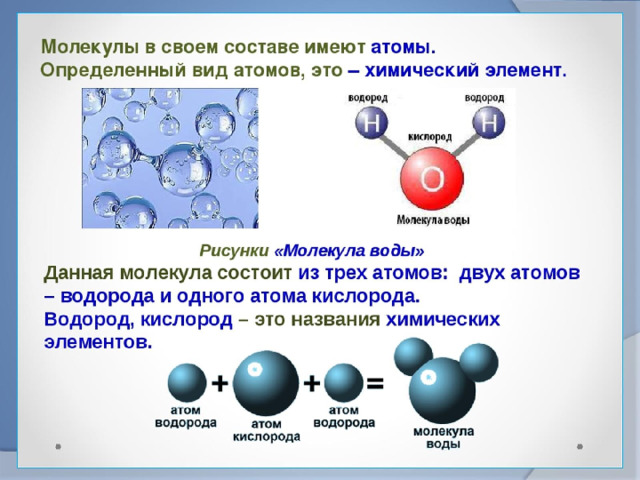 «>
«>Li X, Yan X, Gu Q, Zhou H, Wu D, Xu J (2019) Deepchemstable: прогноз химической стабильности с помощью сети свертки графа на основе внимания. J Chem Inf Model 14:1044–1049
Артикул Google ученый
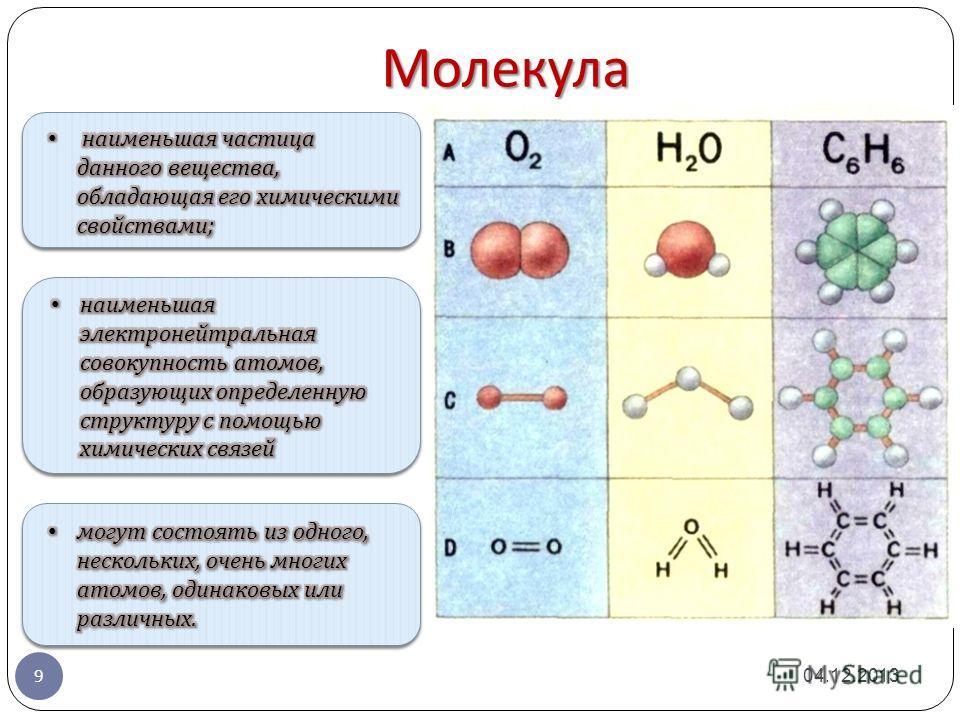 MATCH Commun Math Comput Chem 79: 509–524
MATCH Commun Math Comput Chem 79: 509–524Дювено Д.К., Маклорен Д., Ипаррагирре Дж., Бомбарелл Р., Хирзель Т., Аспуру-Гузик А., Адамс Р.П. (2015)Сверточные сети на графах для изучения молекулярных отпечатков пальцев. В Достижениях в области нейронных систем обработки информации. стр. 2224–2232.
Брейман Л. (2001) Случайные леса. Mach Learn 45:5–32
Статья Google ученый
Скачать ссылки
Благодарности
Авторы выражают признательность группе Государственной ключевой лаборатории физической химии твердых поверхностей Сямэньского университета за использование их высокопроизводительных вычислительных ресурсов.
Финансирование
Эта работа частично финансировалась в рамках программы Китайского совета по стипендиям № 201806310017 и гранта Национального института здравоохранения США R35-GM1269.85. Усилия SK финансировались за счет учебного гранта BD2K T32LM012410 Национального института здравоохранения США.
Информация об авторе
Авторы и организации
Ключевая лаборатория инновационных целевых исследований лекарственных средств провинции Фуцзянь, Школа фармацевтических наук, Сямыньский университет, Сямэнь, 361000, Китай
Bowen Tang, 0 Meijuan 9 Qijuan Fang, 0u 8 Yingk
Департамент электротехники и компьютерных наук, Институт информатики и Центр наук о жизни Кристофера С.
Бонда, Университет Миссури, Колумбия, Миссури, 65211, СШАBowen Tang, Skyler T. Kramer & Dong Xu
Авторы
- Bowen Tang
Посмотреть публикации автора
Вы также можете искать этого автора в PubMed Google Scholar
- Skyler T. Kramer
Посмотреть публикации автора
Вы также можете искать этого автора в PubMed Google Scholar
- Meijuan Fang
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Академия
- Yingkun Qiu
Посмотреть публикации автора
Вы также можете искать этого автора в PubMed Google Scholar
- Zhen Wu
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
- Dong Xu
Просмотр публикаций автора
Вы также можете искать этого автора в PubMed Google Scholar
Вклады
BT и DX разработали исследование. BT реализовала модели и написала рукопись. Все авторы внесли свой вклад в интерпретацию результатов. Все авторы просмотрели и отредактировали рукопись. Все авторы прочитали и одобрили окончательный вариант рукописи.
Авторы переписки
Переписка с Чжэнь Ву или Дун Сюй.
Заявления об этике
Конкурирующие интересы
Авторы заявляют об отсутствии конкурирующих интересов.
Дополнительная информация
Примечание издателя
Springer Nature остается нейтральной в отношении юрисдикционных претензий в опубликованных картах и институциональной принадлежности.
Дополнительная информация
Дополнительный файл 1.Дополнительную информацию можно найти в сопроводительных документах. Исходный код и подготовленные наборы данных доступны в репозитории SAMPN на Github (https://github.com/tbwxmu/SAMPN).
Права и разрешения
Открытый доступ Эта статья находится под лицензией Creative Commons Attribution 4. 0 International License, которая разрешает использование, обмен, адаптацию, распространение и воспроизведение на любом носителе или в любом формате при условии, что вы укажете автора(ов) оригинала и источник, предоставьте ссылку на лицензию Creative Commons и укажите, были ли внесены изменения. Изображения или другие сторонние материалы в этой статье включены в лицензию Creative Commons на статью, если иное не указано в кредитной строке материала. Если материал не включен в лицензию Creative Commons статьи, а ваше предполагаемое использование не разрешено законом или выходит за рамки разрешенного использования, вам необходимо получить разрешение непосредственно от правообладателя. Чтобы просмотреть копию этой лицензии, посетите http://creativecommons.org/licenses/by/4.0/. Отказ Creative Commons от права на общественное достояние (http://creativecommons.org/publicdomain/zero/1.0/) применяется к данным, представленным в этой статье, если иное не указано в кредитной линии данных.
Перепечатка и разрешения
Об этой статье
Направленная передача сообщений для молекулярных графов
Описание
По умолчанию
Пользовательский
4 реализации кода в TensorFlow и PyTorch. Графовые нейронные сети недавно добились больших успехов в предсказании квантово-механических свойств молекул. Эти модели представляют молекулу в виде графа, используя только расстояние между атомами (узлами). Однако они не учитывают пространственное направление от одного атома к другому, несмотря на то, что информация о направлении играет центральную роль в эмпирических потенциалах для молекул, например. в угловых потенциалах. Чтобы снять это ограничение, мы предлагаем направленную передачу сообщений, при которой мы встраиваем сообщения, передаваемые между атомами, а не сами атомы. Каждое сообщение связано с направлением в пространстве координат. Эти направленные вложения сообщений являются эквивариантными по вращению, поскольку связанные направления вращаются вместе с молекулой. Мы предлагаем схему передачи сообщений, аналогичную распространению убеждений, которая использует информацию о направлении путем преобразования сообщений в зависимости от угла между ними. Кроме того, мы используем сферические функции Бесселя и сферические гармоники для построения теоретически обоснованных ортогональных представлений, которые обеспечивают лучшую производительность, чем преобладающие в настоящее время гауссовские радиальные базисные представления, при использовании менее 1/4 параметров.