Конъюнкция и дизъюнкция | Prolog
Так как Prolog – логический язык программирования, он поддерживает различные логические операции. В объектно–ориентированных и функциональных языках программист может просто последовательно вызвать необходимые ему функции. Но в Prolog все выполняемые правила должны быть соединены логическими операторами. Формально: правила в Prolog записываются в форме правил логического вывода с логическими заключениями и списком логических условий. Даже для опытных программистов такая формулировка может быть неочевидной, но в следующих уроках вы подробнее познакомитесь с логическим языком и научитесь писать простые логические операции.
Обратите внимание: в дальнейшем мы будем использовать слово предикат, как замену слову правило
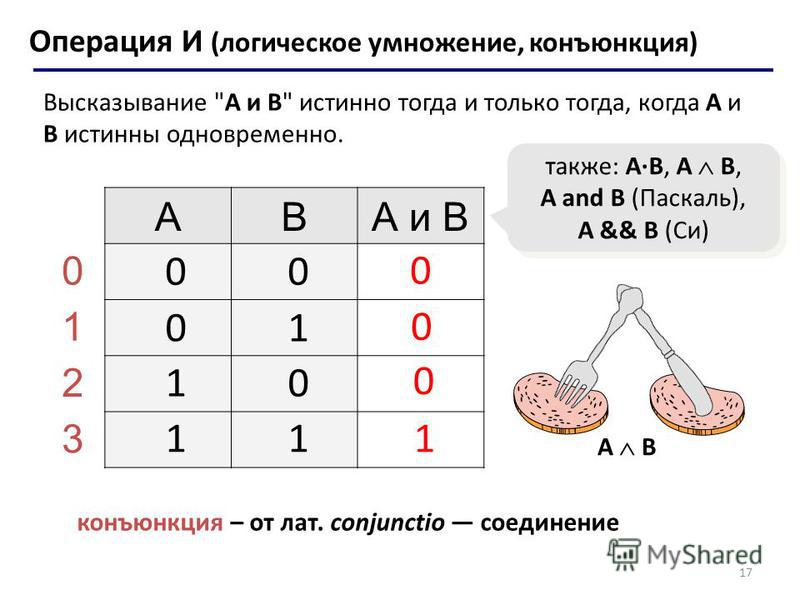
В Prolog существует два встроенных предиката, описывающих конъюнкцию (логическое «И») и дизъюнкцию (логическое «ИЛИ»). Записываются они , и ; соответственно. Т.е. все последовательно применяемые правила должны быть соединены символами ; («ИЛИ»). Чтобы понять принцип работы давайте рассмотрим пример:
Чтобы понять принцип работы давайте рассмотрим пример:
:–
write("Hello, "), write("World!").
Обратите внимание: в ходе отладки вашей программы вы будете сталкиваться с документацией и ошибками. В них можно встретить запись вида
название/число, напримерwrite/1. Данная запись означает, что существует предикат с такимназванием, принимающийчислоаргументов
В данном примере мы вызываем встроенный предикат write/1, чтобы вывести на экран строку ‘Hello, ‘. Далее мы хотим вызвать этот предикат еще раз, чтобы вывести строку ‘World!’. Как было описано выше, предикаты должны быть соединены логическими операциями, чтобы вывести какой–либо логический результат.
,). Если ввести эти команды в интерпретатор мы получим следующий вывод:Hello, World! true.
Фактически операция «И» как бы выполняет функции вместе и дает один результат. Другое название конъюнкции – логическое умножение. Но мы также можем соединить предикаты операцией «ИЛИ» – логическим сложением. В этом случае мы получим следующий вывод:
Другое название конъюнкции – логическое умножение. Но мы также можем соединить предикаты операцией «ИЛИ» – логическим сложением. В этом случае мы получим следующий вывод:
Hello, true ; World! true.
Вместо ожидаемой строки «Hello, World!» мы получили странный вывод, содержащий значения true. Что произошло в этом случае? В данном примере операция «ИЛИ» выполнила предикаты отдельно друг от друга.
Помните, какая задача стоит перед Prolog программой? «Доказать, является ли заданное утверждение следствием из имеющихся фактов и правил». Любое доказательство возвращает «ИСТИНУ» или «ЛОЖЬ».
В примере выше оба предиката не содержат каких–либо логических условий, их задача – вывести строку, поэтому поэтому каждый из этих предикатов вернул «ИСТИНУ» (true).
Более подробно:
- Интерпретатор доказал предикат
write('Hello, ') - Интерпретатор вывел результат доказательства –
true - Интерпретатор доказал предикат
write('World!'). В ходе доказательства была выведена переданная нами в качестве аргумента строка ‘World!’.
В ходе доказательства была выведена переданная нами в качестве аргумента строка ‘World!’. - Интерпретатор вывел результат доказательства –
true
 В ходе доказательства была выведена переданная нами в качестве аргумента строка ‘World!’.
В ходе доказательства была выведена переданная нами в качестве аргумента строка ‘World!’.Итоги: в отличие от других языков, задача Prolog – доказать какие–то утверждения на основе уже существующих в программе фактах. Работу программы можно сравнить с доказательством какой–либо теоремы или предположения.
В следующих уроках вы познакомитесь с фактами и правилами в языке Prolog и научитесь правильно использовать логические операции.
Задание
Повторите пример из урока и выведите на экран следующую строку:
Hello, true ; World! true.Упражнение не проходит проверку — что делать? 😶
Если вы зашли в тупик, то самое время задать вопрос в «Обсуждениях». Как правильно задать вопрос:
- Обязательно приложите вывод тестов, без него практически невозможно понять что не так, даже если вы покажете свой код. Программисты плохо исполняют код в голове, но по полученной ошибке почти всегда понятно, куда смотреть.

Тесты устроены таким образом, что они проверяют решение разными способами и на разных данных. Часто решение работает с одними входными данными, но не работает с другими. Чтобы разобраться с этим моментом, изучите вкладку «Тесты» и внимательно посмотрите на вывод ошибок, в котором есть подсказки.
Мой код отличается от решения учителя 🤔Это нормально 🙆, в программировании одну задачу можно выполнить множеством способов. Если ваш код прошел проверку, то он соответствует условиям задачи.
В редких случаях бывает, что решение подогнано под тесты, но это видно сразу.
Прочитал урок — ничего не понятно 🙄
Кстати, вы тоже можете участвовать в улучшении курсов: внизу есть ссылка на исходный код уроков, который можно править прямо из браузера.
Полезное
Математическая логика
SWI–Prolog
SWISH
←Предыдущий
Нашли ошибку? Есть что добавить? Пулреквесты приветствуются https://github.com/hexlet-basics
Концептуальное логическое и физическое моделирование данных
Известно и чаще всего встречается три варианта построения модели данных или три способа моделирования данных. Каждый вариант моделирования отражает строго один опеределенный аспект данных, где аспекты — это темпоральные стадии процесса проектирования «от замысла до воплощения» некоторой технологии обработки данных или некого когломерата данных, имеющих ценность для их пользователя/потребителя.
Каждый из видов моделирования порождает свою модель, где модель — это множество элементов, образующих слой данных определенного уровня абстрактности или детальности:
- Концептуальный -► концептуальная модель. Цель модели — установить семантику (дать определение) моделируемых явлений реальности и их информационные взаимосвязи.
- Логический -► логическая модель. Цель модели — логически выверенный, оптимизированный и нормализованный набор атрибутов, характеризующих данные, а также связанные с данными методы их обработки. Логический уровень являет собой также спецификацию на реализацию данных в определенной выбранной технологии.
- Физический -► физическая модель. Программное воплощение структур данных.
- Собственно данные — модель реальности, выраженная в символьно-числовом виде.
 Цель модели — установить семантику (дать определение) моделируемых явлений реальности и их информационные взаимосвязи.
Цель модели — установить семантику (дать определение) моделируемых явлений реальности и их информационные взаимосвязи.Почему моделей (подходов к моделированию) и соответственно слоёв данных именно три? На этот вопрос можно ответить по разному:
- три слоя — это три уровня абстракции. Такой ответ подчеркивает нисходящий подход от общего к частному, от контуров замысла о данных к их физическому воплощению. Недостаток такого взглядя заключается в том, что между уровнями абстракции многие затрудняются установить строгие отношения конгруэнции трех множеств.
- три слоя — это темпоральные стадии одной и той же атомарной единицы — единицы данных. В таком случае концептуальный уровень задаёт смысловой объем понятия, заключенного в единице данных, логический — описывает спецификацию единицы данных, физический — описывает реализацию единицы данных.
Слоёв может быть и больше — смотри подробности и концепты, изложенные, например, в Zaсhman Framework. Есть разные основания иметь более трех слоёв, со временем данная статься обогатится этими основаниями, но пока уясним суть ниболее часто востребованных моделей или порождаемых ими слоёв данных.
Концептуальный слой моделированияВ концептуальном слое моделирования (или на концептуальном уровне моделирования) мы определяем основные понятия предметной области и их взаимосвязь. Иногда также используют термин «построение онтологиии предметной области». В сущности — это семантическая модель предметной области или одного из её доменов.
Базовый элемент концептуальной модели: бизнес-сущность или бизнес-объект, или концепт. Что есть концепт? — что-то близкое к определению или дефиниции. То есть задача концептуальной модели дать границы (или окрестности) сущностей, то есть определить объем понятия, который стоит за неким словом (или более точно — обозначающим знаком).
Что есть концепт? — что-то близкое к определению или дефиниции. То есть задача концептуальной модели дать границы (или окрестности) сущностей, то есть определить объем понятия, который стоит за неким словом (или более точно — обозначающим знаком).
Примеры концептов или бизнес-сущностей:
- клиент (как вариант, клиент-ФЛ, клиент-ЮЛ) — это ….<далее идет попытка вербально определить основные характерстики, позволяющие отнести наблюдаемое явление к тому, что обозначается словом клиент>
- продукт (как вариант, товар, услуга) — это < … … … >
- сделка (как вариант, заказ) — это < … … … >
- контракт — это < … … … >.
Концептуальная модель в своём упрощенном виде, как правило, представлена в документах класса ГЛОССАРИЙ (примечание: это может быть как местная wiki, так и разрозненные главы типа «Глоссарий» в различных документах компании). Схематически (графически) наиболее удобным способом отображение концептуальной модели является диаграмма типа «диаграмма классов». Связи между бизнес-сущностями (концептами) полезно «окрашивать» действиями из предметной области, например, клиент заключает сделку, заказ состоит из товаров. Наилучшая нотация для концептуального уровня – подборка элементов из слоя Business и Motivation методологии Archimate. В данной нотации рекомендуется использоваться объект Meaning, а также бизнес-сущности (Business Objects). Последние могут быть привязаны к ряду других архитектурных компонент (например, value или capability), что улучшает их окрашивание или лучше структурирует (делает более наглядной) моделируемую предметную область.
Связи между бизнес-сущностями (концептами) полезно «окрашивать» действиями из предметной области, например, клиент заключает сделку, заказ состоит из товаров. Наилучшая нотация для концептуального уровня – подборка элементов из слоя Business и Motivation методологии Archimate. В данной нотации рекомендуется использоваться объект Meaning, а также бизнес-сущности (Business Objects). Последние могут быть привязаны к ряду других архитектурных компонент (например, value или capability), что улучшает их окрашивание или лучше структурирует (делает более наглядной) моделируемую предметную область.
Фокус моделирования:
- понятийная/смысловая модель, выработка глоссария
- разработка онтологии домена (онтики)
- создание/проработка представления о понятии/явлении, как об информационном объекте (то есть как о совокупности атрибутов)
- выявление связей между понятиями: это не только чётче устанавливает границы понятий, но также формирует из них взаимосвязанную и нормализованную сеть
- выделение ключевых атрибутов, характеризующих ту или иную бизнес-сущность.

Сложные концептуальные модели, содержащие десятки бизнес-сущностей, разбиваются на домены. Домен – группировка «родственных» сущностей, образующих модель отдельного фрагмента моделируемой предметной области (онтика домена).
В крупных проектах приходится поддерживать две концептуальных модели (модели двух видов):
- текущую концепт.модель, являющуюся мостиком между логическими моделями данных конкретных приложений. Эта модель достаточно быстро костенеет за счет многичсленных связей с логическим слоем.
- текущую концепт.модель, отражающую текущее понимание нами онтологии предметной области. Эта модель может меняться почти каждый день.
Итак, концепт.модель — это атрибутированная модель понятий. Естестественно, что если с нее начато проектирование, то концептуальная модель может стать существенной частью логической модели (то есть модели разрабатываемого приложения). Это также бывает в следующих случаях:
- при создании BI-систем
- при создании модели данных интеграционной платформы.

Поддержание концептуальной модели данных возможно в российском ПО класса Enterprise Architect — СиММА.
Логический уровень или слой моделирования
Логическая модель является уточнением и детализацией концептуальной модели. Более точное выражение — это спецификация концептуальной модели. Но это лишь с одной стороны. С другой стороны, на построение логической модели (на создание спецификации данных) также влияет:
- тип планируемой СУБД, которая будет воплощать модель
- класс проектируемой системы: операционная (транзакционная) или аналитическая (BI)
- исторически сложившияся трактовка предметной области вендором системы.
Логический уровень моделирования – это уровень логики организации данных, то есть какие данные и как сгруппированы и связаны друг с другом. Концептуальный уровень больше заботится о смысловых связях, логический – о реальных связях между объектами системы (ссылки объектов друг на друга, отношения объектов). Концептуальный уровень оперирует бизнес-сущностями, логический – сущностями будущей или фактически имеющейся информационной системы (например, базы данных). В компаниях с большой историей логический уровень задан фактически развернутыми системами конкретных вендоров. Слово «логический» стоит понимать в смысле «строго выверенный по правилам математической логики». Слово СПЕКА нужно держать в уме постоянно. Не бывает нестрогих спецификаций.
Концептуальный уровень оперирует бизнес-сущностями, логический – сущностями будущей или фактически имеющейся информационной системы (например, базы данных). В компаниях с большой историей логический уровень задан фактически развернутыми системами конкретных вендоров. Слово «логический» стоит понимать в смысле «строго выверенный по правилам математической логики». Слово СПЕКА нужно держать в уме постоянно. Не бывает нестрогих спецификаций.
Важное замечание. В простейших случаях концептуальные объекты (бизнес-сущности) совпадают с объектами логического уровня. В таких случаях фаза концептуального моделирования может совсем не требоваться или совпадать с фазой построения логической модели. Очень часто молодые системные аналитики пытаются построить сложную логическую модель и проваливают работу, не подозревая о необходимости фазы концептуального моделирования, которая должна выполняться с участием бизнес-аналитиков и самого бизнеса. В настоящее время — время диджитал — концептуализация и цифровизация должны рассматриваться как синонимы.
Сущности логического уровня – это сущности, которыми оперирует информационная система (база данных или сервер приложений). Сущности (объекты) логического уровня соответствуют типам объектов избранной СУБД. Для реляционных баз данных – это ENTITY (сущность), для объектно-ориентированных — это КЛАСС. К сущностям логического уровня подвязываются методы работы с этими сущностями. Здесь также следует держать во внимании, что в XXI веке мы проектируем не столько объекты данных, сколько объекты поведения. То есть выделяя экземпляры данных логического уровня мы должны думать о них не только, как о контейнарх с атрибутами, а как о носителях методов работы с данными.
Базовый элемент логической модели: КЛАСС (сущность в ООП) или собственно ENTITY (сущность, таблица для реляционных баз данных).
Для проектирования реляционных баз данных используется нотация ERD. Рамками этой нотации фактически и задаётся логический уровень моделирования. Однако для систем, имеющих в своей основе объектную модель, логический уровень описывается диаграммной классов (из нотации UML).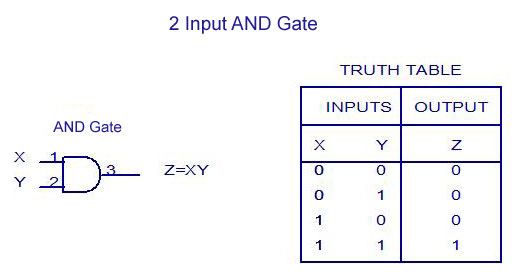 Детализирующие (вспомогательные) и часто используемые диаграммы логического уровня моделирования – это диаграммы состояний.
Детализирующие (вспомогательные) и часто используемые диаграммы логического уровня моделирования – это диаграммы состояний.
Примеры сущностей (классов):
- клиент -► party + customer + customer_profile + person
- продукт -► продукт + предложение продукта + price plan
- заказ -► order, order_item
Фокус моделирования:
- выделение элементарных сущностей, элементарных логических единиц (классов), имеющих самостоятельный смысл в моделируемой предметной области
- детальное (точное) уточнение (установка) взаимосвязей между сущностями
- перечисление всех (!) значимых для бизнеса атрибутов сущности, а также обогащение их атрибутами, вытекающими из архитектуры приложения в целом
- разделение атрибутов на простые атрибуты и перечисления (будущие справочники)
- выделение сущностей не столько как контейнеров для атрибутов, сколько как объектов поведения
Немаловажное влияние на сущности логического уровня и их взаимосвязи оказывает тип проектируемой системы. Если проектируемая система относится к BI-классу, то следует понимать назначение BI-системы, ожидаемые от нее витрины, срезы, аналитики, метод моделирования времени (динамики изменения данных) и т.п.
Если проектируемая система относится к BI-классу, то следует понимать назначение BI-системы, ожидаемые от нее витрины, срезы, аналитики, метод моделирования времени (динамики изменения данных) и т.п.
Если в ходе проектирования разрабатывается логическая модель не одной, а нескольких систем, что часто имеет место быть в крупных компаниях, внедряющих пятую, десятую или сто двадцатую систему, то при разработке логической модели указывают к какой системе принадлежит (или будет принадлежать) та или иная сущность. Распределение сущностей по различным информационным системам даёт возможность грубо наметить (спрогнозировать) будущие информационные потоки (точки интеграции и точки синхронизации) между системами.
Важное замечание. При разработке новой информационной системы, являющейся частью комплекса унаследованных систем, часто приходится использовать как проектирование сверху вниз (от концептуального уровня к физическому), так и обратное – снизу вверх: от уже существующих физических моделей к логической и далее мапирование в концептуальную. Это на порядок или даже на 2 порядка усложняет проектирование даже если нужно создать/автоматизировать один сквозной процесс, протекающий через ряд информационных систем.
Это на порядок или даже на 2 порядка усложняет проектирование даже если нужно создать/автоматизировать один сквозной процесс, протекающий через ряд информационных систем.
Иногда при проработке логического уровня возникают сущности, которые трудно подвязать к бизнес-сущностям концептуального уровня и тогда возникает вопрос: нужно ли на концептуальном уровне завести новую бизнес-сущность? Ответ таков:
- с одной стороны, не стоит перегружать концептуальный уровень.
- с другой стороны, если на концептуальном уровне появляется новая сущность, она должна быть отражена в глоссарии, как принципиально новое понятие, существенно отличное от других понятий данной предметной области.
- добавление данных на логическом уровне без увязки с концептуальным неизбежно ведет к нарушение интеропербельности приложений в корпоративном масштабе.
- не ленитесь использоваться для организации сущностей отношения наследования-специализации.
Каждый вендор информационной системы имеет логическую модель своей системы даже если он и не раскрывает ее своим клиентам. При интеграции нескольких систем приходится сначала увязывать их логические модели на концептуальном уровне моделирования, а лишь потом строить связи между логическими моделями разных систем. Например, в системе автоматизации продаж клиент может быть представлен как PARTY, в ERP-системе той же компании как КОНТРАГЕНТ, а системе биллинга той же компании, как АБОНЕНТ.
При интеграции нескольких систем приходится сначала увязывать их логические модели на концептуальном уровне моделирования, а лишь потом строить связи между логическими моделями разных систем. Например, в системе автоматизации продаж клиент может быть представлен как PARTY, в ERP-системе той же компании как КОНТРАГЕНТ, а системе биллинга той же компании, как АБОНЕНТ.
О необходимости тщательного сопряжения логического и концептуального уровня много написано в DDD (Domain Driven Design).
И еще раз акцентируем внимание, что все чаще (да уже и практически всегда) объекты/классы проектируются как объекты поведения (при измельчении микросервисов), а не объекты группировки данных. Это сильно усложняет контроль за проектированием целостности и связности данных. Это просто усложняет проектирование, что и необходимо, и неизбежно.
Поддержание логической модели данных возможно в российском ПО класса Enterprise Architect — СиММА.
Физический уровень или слой моделирования
Физический слой – это слой таблиц для реляционных моделей данных. С точки зрения ИТ — это слой наивысшей детализации данных. Инвентаризация данных на этом уровне в корпоравтином масштабе крайне затруднительна: для одной-двух-двадцами систем это можно сделать вручную. Если систем десятки и сотни, то такую инвентаризацию нужно делать автоматически путем автомазированного сбора метаданных. Или отказаться от идеи инвентаризации физических структур данных в репозитории, ограничившись лишь ведением логической модели данных эксплуатируемых/развиваемых приложений. Физические модели в таком случае остаются описанными лишь в документации на системы и задача ведения репозитория — задача ведения реестра системной документации.
С точки зрения ИТ — это слой наивысшей детализации данных. Инвентаризация данных на этом уровне в корпоравтином масштабе крайне затруднительна: для одной-двух-двадцами систем это можно сделать вручную. Если систем десятки и сотни, то такую инвентаризацию нужно делать автоматически путем автомазированного сбора метаданных. Или отказаться от идеи инвентаризации физических структур данных в репозитории, ограничившись лишь ведением логической модели данных эксплуатируемых/развиваемых приложений. Физические модели в таком случае остаются описанными лишь в документации на системы и задача ведения репозитория — задача ведения реестра системной документации.
Базовый элемент физической модели: таблица.
Примеры таблиц:
- клиент -► table_1
- продукт -► table_2
- сделка -► table_3
Не исключается, что одна таблица физического уровня может участвовать в моделировании сразу нескольких логических сущностей.
Фокус моделирования:
- Выделение отдельных таблиц, в том числе как результат нормализации данных.
- Выделение таблиц-справочников.
- Определение ключей.
- Разделение атрибутов на простые атрибуты и перечисления (будущие справочники).

В простейших случаях логические объекты (сущности) совпадают с объектами физического уровня. Это характерно для самых простых баз данных реляционного типа.
В потоковых системах, где структурирование данных не выполняется в момент их порождения и накопления, данные на физическом уровне могут представлять просто тексты и строки. Преобразование таких данных к интерпретируемому виду будет выполняться по требованию согласно схеме, определенной в логическом слое, который в этом случае можно считать слоем интерперетации сырых данных.
& (логический оператор И) — ArcGIS Pro
Обсуждение
Оператор & выполняет логическую операцию И, когда один или несколько входных данных (операндов) являются растром. Если оба входа (операнда) являются числами, то оператор & выполнит операцию побитового И. Дополнительные сведения о работе с операторами см. в разделе Работа с операторами.
Дополнительные сведения о работе с операторами см. в разделе Работа с операторами.
Когда в выражении используется несколько операторов, они не обязательно выполняются в порядке слева направо. Оператор с наивысшим значением приоритета будет выполнен первым. Дополнительные сведения см. в таблице приоритетов операторов в разделе Работа с операторами в Алгебре карт. Вы можете использовать круглые скобки для управления порядком выполнения. 9, |) имеют более высокий уровень приоритета, чем операторы отношения (<, <=, >, >=, ==, !=). Поэтому, когда логические операторы используются в том же выражении, что и реляционные операторы, логические операторы будут выполняться первыми. Чтобы изменить порядок выполнения, используйте круглые скобки.
Когда в одном выражении последовательно используются несколько реляционных и/или логических операторов, в некоторых случаях оно может не выполняться. Чтобы избежать этой потенциальной проблемы, используйте в выражении соответствующие круглые скобки, чтобы явно определить порядок выполнения операторов. Дополнительные сведения см. в разделе правил сложных операторов в статье Создание сложных операторов.
Дополнительные сведения см. в разделе правил сложных операторов в статье Создание сложных операторов.
Для выполнения булевой оценки необходимы два входа.
Порядок ввода не имеет значения для этого оператора.
Если входные значения представляют собой значения с плавающей запятой, они преобразуются в целые значения путем усечения перед выполнением логической операции. Выходные значения всегда целые.
Другой способ выполнения логической операции И — это &= b, что является альтернативой записи a = a & b.
Если оба входных сигнала являются одноканальными растрами или один из входных данных является константой, выходным будет одноканальный растр.
Если оба входа являются многоканальными растрами, оператор выполнит операцию над каждым каналом из одного входа, и на выходе будет многоканальный растр. Количество полос на каждом многополосном входе должно быть одинаковым.
Если одним из входных данных является многоканальный растр, а другим входным значением является константа, оператор выполнит операцию над постоянным значением для каждого канала в многоканальном входном сигнале, и на выходе будет многоканальный растр.
Если оба входа являются многомерными растрами с одинаковым количеством переменных, оператор выполнит операцию для всех срезов с одинаковым значением размерности, а на выходе будет многомерный растр. Переменные во входных данных должны иметь одинаковые размерности или общие размерности, но не должны иметь необычных размерностей.
Если оба входа имеют одну переменную, но разные имена, установите для среды геообработки matchMultidirectionalVariable значение False, чтобы выполнить операцию.
Если одним из входных данных является многомерный растр, а другим входным значением является константа, оператор выполнит операцию для всех срезов для всех переменных с постоянным значением, а на выходе будет многомерный растр.
Пример кода
и (логическое И) пример 1 (окно Python)В этом примере выполняется логическая операция И над двумя входными растрами.
импорт дуги
из окружения импорта arcpy
импорт из arcpy.sa *
env.workspace = "C:/sapyexamples/данные"
outBooleanAnd = Raster("градусы") & Raster("отрицатели")
outBooleanAnd. save("C:/sapyexamples/output/outbooland.img") & (логическое И) пример 2 (автономный скрипт) save("C:/sapyexamples/output/outbooland.img")
save("C:/sapyexamples/output/outbooland.img") В этом примере выполняется логическая операция И над двумя входными растрами.
# Имя: Op_BooleanAnd_Ex_02.py
# Описание: Выполняет логическую операцию И над значениями ячеек
# из двух входных растров
# Требования: Расширение Spatial Analyst
# Импорт системных модулей
импортировать аркпи
из окружения импорта arcpy
импорт из arcpy.sa *
# Установить параметры среды
env.workspace = "C:/sapyexamples/данные"
# Установить локальные переменные
inRaster1 = Растр ("градусы")
inRaster2 = Растр ("нег")
# Выполнить BooleanAnd
outBooleanAnd = inRaster1 & inRaster2
# Сохраняем вывод
outBooleanAnd.save("C:/sapyexamples/output/outbooland") Булевы операторы — Учебное пособие по исследовательским навыкам
Булевы операторы
Хотя базы данных не могут понимать естественный язык, поиск в базе данных можно сделать очень точным с помощью логических операторов. Логические операторы сообщают базам данных, как именно вы хотите, чтобы ваши условия поиска сочетались для получения оптимальных результатов.
Логические операторы сообщают базам данных, как именно вы хотите, чтобы ваши условия поиска сочетались для получения оптимальных результатов.
Булевых операторов всего пять, и все базы данных библиотек их понимают.
В таблице ниже кратко описаны их функции.
| Оператор | Что он делает? | Пример |
|---|---|---|
| «» | Содержит вместе слова фразы, чтобы база данных искала их вместе, а не по отдельности | «персонал больницы» |
| * | Усекает слово, чтобы получить альтернативные окончания | educat* для образования, образованный, обучает и т. д. |
| И | Объединяет две концепции, чтобы база данных знала, что вы хотите, чтобы оба были в результатах поиска | собаки И «служебные животные» |
| ИЛИ с () | Используется для объединения двух или более ключевых слов, обычно синонимов или связанных терминов для одного и того же понятия, чтобы база данных знала, что вы хотите, чтобы одно или оба из них были в результатах поиска. Всякий раз, когда вы соединяете ключевые слова с помощью ИЛИ, заключайте их в круглые скобки. | (поезда ИЛИ железные дороги) И путешествие |
| НЕ | Используется, чтобы сообщить базе данных, что вы не хотите, чтобы это ключевое слово или группа ключевых слов отображались в результатах поиска. | кормление грудью НЕ (грудное вскармливание ИЛИ период лактации) |
Хотя имеется всего несколько операторов, их можно комбинировать для создания очень сложного поиска все более сложных исследовательских тем. В видео ниже это подробно обсуждается, а также рассказывается, как избежать некоторых распространенных ошибок при поиске в базе данных. Если вы предпочитаете, перейдите к текстовому обсуждению под ним.
Теперь давайте подробнее поговорим о каждом операторе.
«Кавычки»
Кавычки сообщают базе данных, что нужно брать фразу целиком и искать слова вместе и по порядку.
Пример: поиск диких гусей :
- Без кавычек база данных находит слово дикий и слово гусей отдельно. Вы можете получить результаты поиска о том, насколько хорошо домашние гуси выживают в дикой природе.
- С кавычками база данных игнорирует статьи, не содержащие точной фразы «дикие гуси». Он не будет воспитывать «диких гусей» или «диких животных, таких как канадские гуси».
Truncat*
Звездочка (*) — это своего рода подстановочный знак, который сообщает базе данных, что необходимо найти несколько «окончаний» слова.
Пример: Поиск феминизм .
- Без усечения получится только феминизм, но не феминистка.
- Когда вы усекаете как feminis*, вы получаете и феминизм, и феминистку.
Будьте осторожны, не обрезайте само слово слишком рано.
- Если обрезать как femini*, получится феминизм, феминистский, а также женский, что может быть не по теме.

AND
AND объединяет два или более понятий, сообщая базе данных, что оба/все эти ключевые слова должны появляться в результатах поиска.
Пример: В поисках идеи Платона о хорошей жизни .
- Без И большинство баз данных предполагают, что вы все равно имели в виду И; однако некоторые базы данных могут возвращать элементы, в которых упоминается Платон или «хорошая жизнь», но не то и другое одновременно.
- При использовании И база данных знает, что вам нужны статьи, содержащие слово Платон и словосочетание «хорошая жизнь».
Подсказка: если ваша тема — «X из Y», или «влияние X на Y», или «X как Y», или «X в Y», вам нужно использовать И, чтобы соединить концепцию X и concept Y.
OR
OR объединяет два или более ключевых слова для одного и того же понятия, сообщая базе данных, что одно или несколько из них должны появиться в результатах поиска. Это полезно, когда:
- У вас есть несколько способов сказать одно и то же, например, США, США, Америка и Соединенные Штаты.
- Вы ищете две вещи, имеющие отношение к одному и тому же понятию, например, вакцина И (корь ИЛИ «ветряная оспа»)
Пример. Поиск бешенства у млекопитающих
- Без OR вы можете искать бешенство летучих мышей опоссумов «диких кошек», и база данных будет возвращать результаты, содержащие все эти ключевые слова. Вы бы упустили результаты, говорящие о бешенстве только у одного из этих видов животных.
- С помощью ИЛИ вы ищете бешенство И (летучие мыши ИЛИ опоссумы ИЛИ «дикие кошки»), и база данных знает, что вам нужно знать о бешенстве у летучих мышей, или о бешенстве у опоссумов, или о бешенстве у диких кошек, или о любой комбинации вышеперечисленного.
Совет: всегда заключайте в скобки группы ключевых слов, соединенных оператором ИЛИ.
(круглые скобки)
Круглые скобки сообщают базе данных, что она не может просто работать слева направо — сначала она должна выполнить определенные операции. Вот почему вам нужно заключать в круглые скобки группы ключевых слов, соединенных ИЛИ.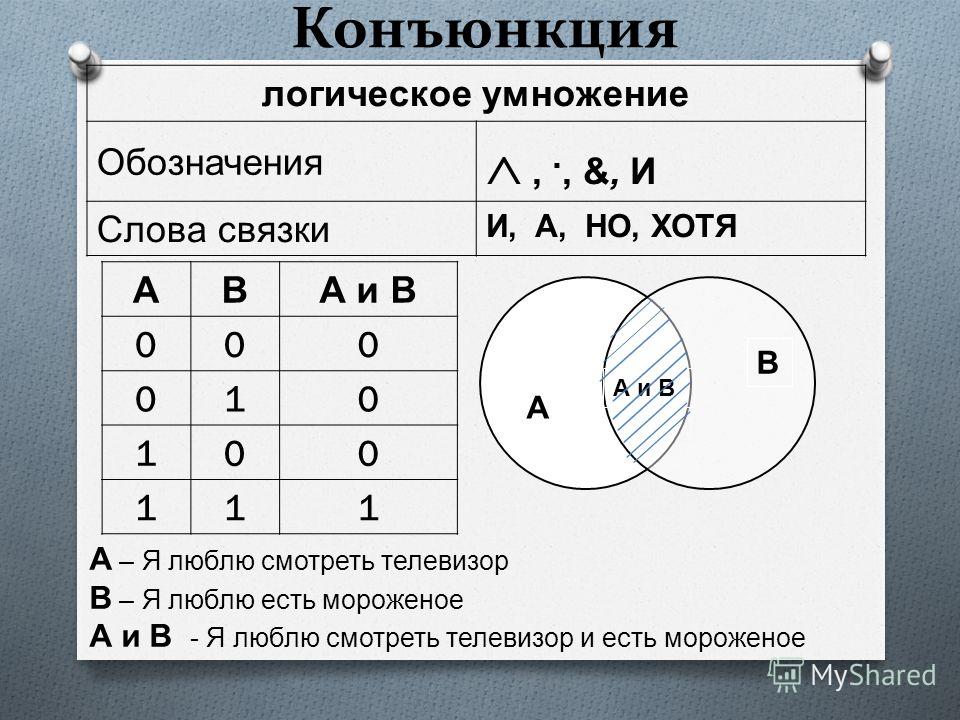
Пример: поиск по использованию летучих мышей и лягушек для борьбы с комарами
- Если вы ищете «борьба с комарами» И летучие мыши ИЛИ лягушки, база данных работает слева направо. Сначала он ищет «борьба с комарами» И летучие мыши, а затем ищет лягушек, поэтому вы получаете результаты поиска, которые касаются лягушек, но не имеют ничего общего с борьбой с комарами
- Если вы ищете «против комаров» И (летучие мыши ИЛИ лягушки), база данных знает, что сначала нужно найти летучих мышей ИЛИ лягушек. Затем он просматривает эти результаты, чтобы найти «средство от комаров».
Вы также можете вложить скобки (поместить один набор внутри другого), и база данных будет работать изнутри наружу.
- (((летучие мыши ИЛИ лягушки) И «борьба с комарами») И (детская площадка ИЛИ «поле для гольфа»)): Сначала база данных ищет летучих мышей ИЛИ лягушек. Он ищет в этих результатах «борьба с комарами». Затем он ищет среди них результаты, в которых упоминается либо детская площадка, либо «поле для гольфа», либо и то, и другое.

НЕ
НЕ исключает результаты поиска, содержащие ключевые слова после него.
Пример: Вы ищете влияние смога на астму, но не хотите читать о Китае .
- Поиск (смог И астма) НЕ Китай, и база данных сначала ищет статьи, содержащие как смог, так и астму, а затем исключает все результаты поиска, содержащие Китай.
Когда вам может понадобиться НЕ:
- Когда вас интересует только часть темы, например собаки, НЕ пудели.
- Если есть определенное слово/фраза, связанная с вашей темой, которая подразумевает предвзятую точку зрения, например иммиграция, НЕ «нелегальные иностранцы»
- Если слово/фраза, которую вы хотите использовать, чаще всего используется как часть фразы, не относящейся к теме, например, климат НЕ «изменение климата»
- Если слово/фраза для вашей темы также используется для другого значения, например, архив НЕ (электронная почта ИЛИ база данных)
Вполне возможно, что у вас может быть настолько сложный поиск, что вам может потребоваться использование всех шести логических операторов для получения оптимальных результатов поиска.