
Распознавание голоса (voice recognition module v3.1)
Общие сведения:
Модуль распознавания голоса — Voice Recognition Module V3.1 — это компактный и простой в управлении модуль распознавания речи. На базе данного модуля можно создавать проекты с голосовым управлением.
Для работы модуля его необходимо обучить — записать через микрофон собственные голосовые команды в энергонезависимое хранилище голосовых команд модуля. Вы можете записать до 80 голосовых команд (каждая команда не более 1,5 сек., примерно одно, максимум два слова) и все они будут храниться в модуле, даже после отключения питания. Стоит отметить, что записывать можно не только голос (слова), но и различные звуки.
У модуля есть два вида памяти: память хранилища (где голосовые команды просто хранятся) и память распознавателя (где голосовые команды участвуют в сравнении со звуком поступившем через микрофон).
Перед распознаванием голосовых команд их нужно загрузить из памяти хранилища в память распознавателя. Память распознавателя рассчитана на 7 голосовых команд, значит модуль способен одновременно сравнивать до 7 голосовых команд с поступающим звуковым сигналом.
Память распознавателя рассчитана на 7 голосовых команд, значит модуль способен одновременно сравнивать до 7 голосовых команд с поступающим звуковым сигналом.
Термины:
- Хранилище голосовых команд – энергонезависимая память состоящая из 80 ячеек, в каждую ячейку можно записать одну голосовую команду с текстовым комментарием.
- Распознаватель голосовых команд – основная часть модуля распознавания речи, блок содержащий ОЗУ из 7 ячеек, в каждую ячейку можно загрузить одну голосовую команду из хранилища голосовых команд модуля. Блок распознавателя сравнивает загруженные в него голосовые команды с поступающим звуковым сигналом.
- Номер ячейки – совпадает с номером записи. Память хранилища и память распознавателя разбита на ячейки. Одна ячейка может хранить одну запись (голосовую команду). Доступ к записям хранилища и записям распознавателя осуществляется по номерам ячеек.
- Обучение – процесс записи ваших голосовых команд в хранилище.

- Загрузка – копирование записанной голосовой команды из хранилища в распознаватель.
- Подпись – текстовый комментарий (до 10 символов) к голосовой команде записанной в хранилище.
- Группа – список содержащий 7 номеров ячеек хранилища. Поддерживаются, системные группы и пользовательские группы. Загрузка группы приводит к загрузке в распознаватель тех голосовых команд хранилища, номера которых указаны в группе.
Более подробно о группах читайте в разделе Группы.

Видео:
Редактируется…
Спецификация:
- Точность распознавания речи: 99% (при идеальных условиях).
- Объем хранилища: до 80 голосовых команд длительностью не более 1,5 сек.
- Одновременное распознавание: до 7 голосовых команд.
- Напряжение питания: 4,5 … 5,5 В (постоянного тока).
- Потребляемый ток: до 40 мА.
- Цифровой Интерфейс: UART и GPIO уровень TTL 5В.
- Аналоговый интерфейс: разъем микрофона jack 3,5-мм моноканальный.
- Габариты платы: 31х50 мм.

Подключение:
- Колодка из 4 выводов (GND, VCC, RXD, TXD) используется для подключения модуля к аппаратной или программной шине UART Arduino.
| Выводы модуля: | Выводы Arduino: |
|---|---|
| RXD — вход шины UART. | TX — выход шины UART. |
| TXD — выход шины UART. | RX — вход шины UART. |
| VCC — вход питания 5 В. | 5V — вывод питания 5 В. |
| GND — общий вывод питания. | GND — общий вывод питания. |
В примерах библиотеки «VoiceRecognitionV3» используется программная шина UART, где вывод модуля RXD подключается к выводу 3 Arduino UNO, а вывод модуля TXD подключается к выводу 2 Arduino UNO (выводы можно переназначить в скетче). Вместо Arduino UNO можно использовать Piranha Uno.
- Колодка из 4 выводов (IN0, IN1, IN2, GND) может быть использована для загрузки требуемых групп голосовых команд из хранилища в распознаватель голосовых команд.

| IN-2 | IN-1 | IN-0 | № загружаемой группы в распознаватель голосовых команд: |
|---|---|---|---|
| 0 | 0 | 0 | Загрузить системную или пользовательскую группу номер 00. |
| 0 | 0 | 1 | Загрузить системную или пользовательскую группу номер 01. |
| 0 | 1 | 0 | Загрузить системную или пользовательскую группу номер 02. |
| 0 | 1 | 1 | Загрузить системную или пользовательскую группу номер 03. |
| 1 | 0 | 0 | Загрузить системную или пользовательскую группу номер 04. |
| 1 | 0 | 1 | Загрузить системную или пользовательскую группу номер 05. |
| 1 | 1 | 0 | Загрузить системную или пользовательскую группу номер 06. |
| 1 | 1 | 1 | Загрузить системную или пользовательскую группу номер 07. |
Более подробно о группах читайте в разделе Группы.
Все выводы IN-0…IN-2 внутрисхемно подтянуты до уровня Vcc.
По умолчанию, загрузка групп при помощи выводов IN-0…IN-2 отключена.
- Колодка из 8 выводов (OUT0-OUT6, GND) может быть использована для управления маломощными устройствами напрямую или мощными устройствами через реле, или силовые ключи.
| Выводы: | Назначение: |
|---|---|
| OUT-0 | Вывод реагирует на опознание голосовой команды в 0 ячейке распознавателя. |
| OUT-1 | Вывод реагирует на опознание голосовой команды в 1 ячейке распознавателя. |
| OUT-2 | Вывод реагирует на опознание голосовой команды в 2 ячейке распознавателя. |
| OUT-3 | Вывод реагирует на опознание голосовой команды в 3 ячейке распознавателя. |
| OUT-4 | Вывод реагирует на опознание голосовой команды в 4 ячейке распознавателя. |
| OUT-5 | Вывод реагирует на опознание голосовой команды в 5 ячейке распознавателя. |
| OUT-6 | Вывод реагирует на опознание голосовой команды в 6 ячейке распознавателя. |
По умолчанию выводы OUT реагируют на опознание голосовой команды отрицательным импульсом, но реакцию можно настроить так, что выводы будут менять, устанавливать, или сбрасывать логический уровень при каждом совпадении голосовой команды.
Питание:
Входное напряжение питания 5В постоянного тока, подаётся на выводы Vcc и GND модуля.
Подробнее о модуле:
У модуля распознавания голоса — Voice Recognition Module V3.1 есть два вида памяти: память хранилища (где голосовые команды просто хранятся, даже после отключения питания) и память распознавателя (где голосовые команды участвуют в сравнении со звуком поступившем через микрофон).
Оба типа памяти состоят из ячеек, в одну ячейку записывается одна голосовая команда. Память хранилища голосовых команд состоит из 80 ячеек пронумерованных от 0 до 79, а память распознавателя голосовых команд состоит из 7 ячеек пронумерованных от 0 до 6. Значит модуль способен хранить до 80 голосовых команд, а одновременно сравнивать до 7 голосовых команд с поступающим звуковым сигналом.
Для работы модуля его необходимо обучить — записать столько голосовых команд в энергонезависимое хранилище, сколько требуется для Вашего проекта. В распознаватель, голосовые команды не записываются, а загружаются из памяти хранилища. Модуль позволяет указать номера ячеек хранилища, голосовые команды которых будут автоматически загружаться в распознаватель при подаче питания модуля.
Такая организации памяти позволяет разделить длинные голосовые команды (произношение которых занимает более 1,5 сек.) на две и более маленьких голосовых команд, которые будут подгружаться из хранилища в распознаватель по мере опознания модулем предыдущих частей длинной голосовой команды.
Пример:
- Предположим, мы желаем создать голосовое управление светом в коридоре, комнате и на кухне, а так же управление жалюзи в комнате и на кухне.
- Записываем в ячейки хранилища следующие голосовые команды: «свет», «жалюзи», «в коридоре», «в комнате» и «на кухне».
- Голосовые команды «свет» и «жалюзи» загружаем из хранилища в распознаватель изначально.
- При распознавании голосовой команды «свет», загружаем в распознаватель голосовые команды «в коридоре», «в комнате» и «на кухне».
- При распознавании голосовой команды «жалюзи», загружаем голосовые команды «в комнате» и «на кухне» (не загружая «в коридоре», если конечно у Вас там нет жалюзей).
- Таким образом Вы можете произнести «свет, в коридоре», «свет, в комнате», «свет, на кухне», «жалюзи, в комнате», «жалюзи, на кухне», а модуль сначала распознает первое слово («свет» или «жалюзи»), а потом оставшуюся часть Вашей длинной голосовой команды.
- Осталось добавить в программу условие, что через определённое Вами время, после опознания команды «свет» или «жалюзи», они опять должны быть загружены в распознаватель. Так модуль перейдёт в состояние готовности принять следующую длинную голосовую команду, вне зависимости от того была ли корректно распознана предыдущая, или нет.

В данный пример можно добавить немного интерактивности включив в проект MP3-плеер и записав в него несколько сообщений. Вы говорите «свет», MP3-плеер воспроизводит сообщение «где?», Вы говорите «на кухне», MP3-плеер воспроизводит сообщение «свет на кухне включён!», или «свет на кухне выключен», в зависимости от текущего состояния реле управления светом. Стоит учитывать, что модуль распознавания речи и MP3-плеер должны находиться на разных шинах UART.
Еще одним плюсом наличия двух типов памяти модуля (хранилища и распознавателя), является возможность создания голосового управления несколькими людьми (до 7 человек) на одном модуле.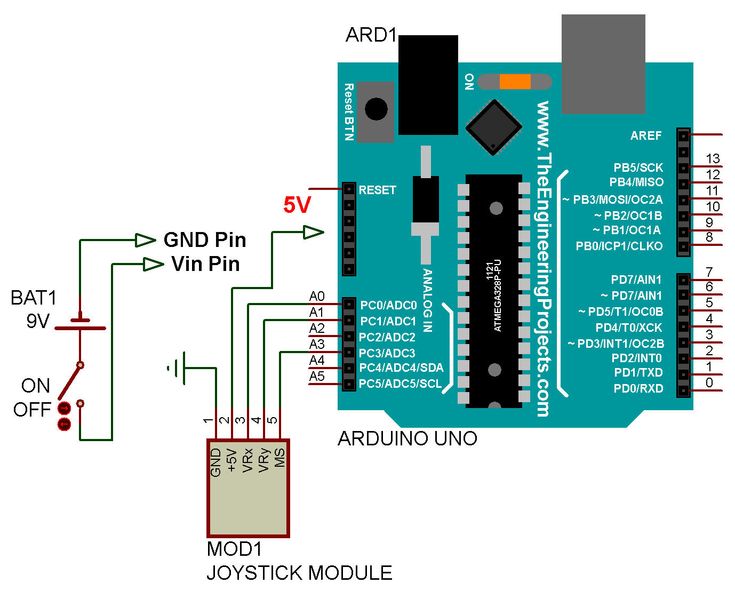 Каждый человек записывает одинаковые слова голосовых команд в разные ячейки хранилища модуля, а так же записывает одно стартовое слово, например, «Окей дом». В таком случае в распознаватель изначально загружаем все голосовые команды «Окей дом» записанные разными людьми. Если кто то скажет «Окей дом, свет, в коридоре», то по номеру ячейки опознанной модулем голосовой команды «Окей дом», Вы сможете определить кем она была сказана и подгрузить в распознаватель следующие команды «свет» и «жалюзи» записанные именно этим человеком.
Каждый человек записывает одинаковые слова голосовых команд в разные ячейки хранилища модуля, а так же записывает одно стартовое слово, например, «Окей дом». В таком случае в распознаватель изначально загружаем все голосовые команды «Окей дом» записанные разными людьми. Если кто то скажет «Окей дом, свет, в коридоре», то по номеру ячейки опознанной модулем голосовой команды «Окей дом», Вы сможете определить кем она была сказана и подгрузить в распознаватель следующие команды «свет» и «жалюзи» записанные именно этим человеком.
Управление модулем может осуществляться 2 способами:
- Через последовательный порт UART (полный функционал).
Управление осуществляется командами протокола VR3, или методами библиотеки VoiceRecognitionV3 (некоторые примеры описаны в настоящей статье). - Через выводы модуля IN и OUT (частичный функционал).
Входы IN позволяют загрузить требуемые группы голосовых команд из хранилища в распознаватель, а выходы OUT позволяют определить номер распознанной голосовой команды и управлять устройствами.

Примеры:
В данном разделе содержатся примеры с использованием библиотеки VoiceRecognitionV3.
Пример обучения модуля:
Скетч примера поставляется вместе с библиотекой «VoiceRecognitionV3» и предназначен для записи голосовых команд в хранилище, загрузки голосовых команд из хранилища в распознаватель, удаления записанных голосовых команд, проверки состояния хранилища и распознавателя, получения комментариев к записям и проверки состояния модуля.
- Откройте скетч из примеров: Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_train.
- Выберите Вашу плату Arduino (Инструменты -> Плата), выберите порт (Инструменты -> Порт).
- Нажмите кнопку «Загрузить», дождитесь загрузки скетча в Arduino.
- Откройте «Монитор последовательного порта». Установите скорость передачи 115200 бод, установите отправку с добавлением символа новой строки (NL — NewLine), или с добавлением символов возврата каретки и новой строки (NL & CR).

В мониторе последовательного порта появится таблица со списком команд, которые Вы можете вводить:
5. Отправьте команду «settings» (настройки) чтобы проверить настройки модуля.
Для отправки команды введите «settings» и нажмите кнопку «Отправить», как на картинке ниже:
В ответ на команду «settings» (настройки) в мониторе последовательного порта появятся текущие настройки модуля:
Эти настройки означают следующее:
| Baud rate | (скорость передачи данных по шине UART) | 9600 бит/сек. |
| Output IO Mode | (режим работы выходов OUT) | Импульсный. |
| Pulse Width | (ширина импульса) | 10 миллисекунд. |
| Auto Load | (автозагрузка записей в распознаватель) | Отключена. |
| Group control by external IO | (управление группами при помощи входов IN 0-2) | Отключено. |
6. Обучение модуля распознавания голоса. Введите строку «sigtrain 0 On».
Введите строку «sigtrain 0 On».
Команда «sigtrain» указывает библиотеке что мы хотим записать голосовую команду, далее следует номер записи (ячейки) — «0» и завершает строку текстовое описание голосовой команды — «On». Вместо подписи «On» Вы можете ввести любое слово до 10 байт, например, «Вкл».
В ответ на команду «sigtrain 0 On» (sigtrain номер подпись) в мониторе последовательного порта появится надпись «Speak now» (говорите сейчас). Вам нужно произнести свою голосовую команду (это может быть любое слово, например «Включить»). Через пару секунд в мониторе последовательного порта появятся надпись «Speak again» (говорите снова) . Вам нужно повторно произнести свою голосовую команду.
Если обе произнесённые голосовые команды совпали, то в мониторе последовательного порта появятся надписи: «Record: 0 — Success» (Запись: 0 — Успех), «Record 0 — Trained» (Запись 0 — Обучена), «SIG: On» (Подпись: «On»).
Это означает что Ваша голосовая команда записана в хранилище голосовых команд.
Но если, по «мнению» модуля, голосовые команды не совпадают, то в мониторе последовательного порта появится надпись «Record: 0 — Cann’t matched» (Запись: 0 — не соответствует):
После чего опять появится надпись «Speak now» (говорите сейчас), а затем «Speak again» (говорите снова).
Вам нужно повторить голосовые команды пока запись не будет сохранена в хранилище.
Что такое подпись? Подпись — это текстовое описание голосовой команды. В нашем случае мы записали команду 0 с подписью «On». После завершения обучения модуль может отображать подпись произнесённой (распознанной) голосовой команды.
Во время обучения можно смотреть не в монитор последовательного порта, а на два светодиода расположенные рядом с разъёмом микрофона: SYS_LED (желтый) и STATUS_LED (красный).
- Желтый светодиод быстро мигает – приготовьтесь произнести голосовую команду.
- Красный светодиод горит – произнесите голосовую команду.
- Желтый светодиод мигает – приготовьтесь повторно произнести голосовую команду.
- Красный светодиод горит – произнесите голосовую команду.
- Оба светодиода мигают одновременно – голосовые команды совпали и записаны.
- Желтый светодиод медленно мигает – сравнение звукового сигнала с записями распознавателя.
7. Попробуйте обучить модуль следующей голосовой команде.
Ведите строку «sigtrain 1 Off». Эта строка указывает модулю что Вы собираетесь записать голосовую команду в 1 ячейку хранилища с подписью «Off». После появления надписей «Speak now» (говорите сейчас) и «Speak again» (говорите снова), произнесите слово «Отключить».
Таким образом Вы можете записать в хранилище до 80 голосовых команд (с номерами от 0 до 79). При записи голосовых команд не обязательно соблюдать очерёдность следования номеров ячеек памяти хранилища. Можно записать голосовую команду, сначала в 3 ячейку, потом в 0, а потом, например, в 27. Главное помнить, в какой ячейке какая команда, чтоб их случайно не затереть, вот для этого то мы и указываем подпись при записи голосовых команд. Но, если Вы уверены, что подпись Вам не нужна, то вводите строку «sigtrain номер» без подписи.
Но, если Вы уверены, что подпись Вам не нужна, то вводите строку «sigtrain номер» без подписи.
Для того что бы модуль, после обучения (записи голосовых команд), мог опознать голосовую команду, её нужно загрузить из хранилища в распознаватель. В распознаватель модуля можно загрузить до 7 из 80 записанных команд.
8. Загрузка голосовых команд из хранилища в распознаватель модуля. Введите строку «load 0 1» для загрузки записей из 0 и 1 ячеек хранилища в память распознавателя.
Процесс загрузки не удаляет записи из памяти хранилища, а копирует записи из указанных ячеек хранилища голосовых команд в память распознавателя по порядку.
В ответ на команду «load 0 1» (загрузить записи 0 и 1) в мониторе последовательного порта появятся надписи «Record 0 Loaded» (запись 0 загружена) и «Record 1 Loaded» (запись 1 загружена).
В память распознавателя можно загружать записи из любых ячеек хранилища голосовых команд, например, строка «load 3 21 17» приведёт к загрузке записей из ячеек 3, 21 и 17 хранилища голосовых команд, в память распознавателя, по порядку указания ячеек. То есть запись 3 хранилища скопируется в ячейку 0 распознавателя, запись 21 хранилища скопируется в ячейку 1 распознавателя, а запись 17 хранилища скопируется в ячейку 2 распознавателя. Но пока делать этого не стоит, ведь мы записали только 2 голосовые команды в память хранилища (ячейки 0 и 1) и загрузили их в в память распознавателя (так же ячейки 0 и 1).
То есть запись 3 хранилища скопируется в ячейку 0 распознавателя, запись 21 хранилища скопируется в ячейку 1 распознавателя, а запись 17 хранилища скопируется в ячейку 2 распознавателя. Но пока делать этого не стоит, ведь мы записали только 2 голосовые команды в память хранилища (ячейки 0 и 1) и загрузили их в в память распознавателя (так же ячейки 0 и 1).
Теперь если Вы произнесёте слова «Включить» и «Отключить», то увидите сообщения
- Распознана голосовая команда загруженная в ячейку распознавателя 0, запись загружена не группой, запись загружена из ячейки хранилища 0, голосовая команда имеет подпись «On».
- Распознана голосовая команда загруженная в ячейку распознавателя 1, запись загружена не группой, запись загружена из ячейки хранилища 1, голосовая команда имеет подпись «Off».
Пример управления светодиодом на плате Arduino:
Скетч примера поставляется вместе с библиотекой «VoiceRecognitionV3».
- Откройте скетч из примеров: Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_control_led.
- Выберите Вашу плату Arduino (Инструменты -> Плата), выберите порт (Инструменты -> Порт).
- Нажмите кнопку «Загрузить», дождитесь загрузки скетча в Arduino.
- Откройте «Монитор последовательного порта». Установите скорость передачи 115200 бод, установите отправку с добавлением символа новой строки (NL — NewLine), или с добавлением символов возврата каретки и новой строки (NL & CR).

В мониторе последовательного порта появится следующий текст:
Так как в предыдущем примере Вы уже записали 2 команды в распознаватель, то произнесите их. Произнесение первой команды приведёт к включению светодиода на плате Arduino, а произнесение второй к выключению. При этом в мониторе последовательного порта будут отображаться те же сведения, что и при опознании голосовых команд в предыдущем примере:
- Распознана голосовая команда загруженная в ячейку распознавателя 0, запись загружена не группой, запись загружена из ячейки хранилища 0, голосовая команда имеет подпись «On».
- Распознана голосовая команда загруженная в ячейку распознавателя 1, запись загружена не группой, запись загружена из ячейки хранилища 1, голосовая команда имеет подпись «Off».

Остальные примеры включённые в библиотеку «VoiceRecognitionV3»:
Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_multi_cmd: раскрывает принцип работы с группами голосовых команд. Голосовая команда записанная в 0 ячейку хранилища (RECORD 0) используется для переключения между двумя группами голосовых команд. Первая группа содержит номера ячеек хранилища RECORD 0,1,2,3,4,5,6, а вторая группа содержит номера ячеек хранилища RECORD 0,7,8,9,10,11,12. Перед запуском данного примера необходимо обучить модуль (записать) голосовые команды от 0 до 12.
Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_check_baud_rate: позволяет узнать установленную скорость передачи данных по шине UART. Может пригодиться если Вы забыли пользовательские настройки.
Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_bridge: позволяет отправлять команды протокола VR3 без кода заголовка, длины кадра и кода конца кадра. Например, для отправки команды «Check Recognizer», вместо байтов «AA 02 01 0A», нужно ввести только 01. Протокол VR3 описан в разделе Wiki — Протокол VR3 для модуля распознавания голоса.
Группы:
Группы используются для удобства загрузки нескольких голосовых команд из хранилища в распознаватель. Каждая группа может включать до 7 номеров ячеек хранилища голосовых команд. Загрузка группы приводит к загрузке в распознаватель всех ячеек хранилища, номера которых указаны в группе. Группы можно загружать командами UART или при помощи входов модуля IN 0-2.
Существует два вида групп: системные группы и пользовательские группы.
Системные группы имеют жесткую структуру и включают в себя 7 номеров ячеек хранилища голосовых команд:
| № системной группы | № ячеек хранилища голосовых команд входящих в группу: |
|---|---|
| 00 | 00, 01, 02, 03, 04, 05, 06 |
| 01 | 07, 08, 09, 0A, 0B, 0C, 0D |
| 02 | 0E, 0F, 10, 11, 12, 13, 14 |
| 03 | 15, 16, 17, 18, 19, 1A, 1B |
| 04 | 1C, 1D, 1E, 1F, 20, 21, 22 |
| 05 | 23, 24, 25, 26, 27, 28, 29 |
| 06 | 2A, 2B, 2C, 2D, 2E, 2F, 30 |
| 07 | 31, 32, 33, 34, 35, 36, 37 |
| 08 | 38, 39, 3A, 3B, 3C, 3D, 3E |
| 09 | 3F, 40, 41, 42, 43, 44, 45 |
| 0A | 46, 47, 48, 49, 4A, 4B, 4C |
Пользовательские группы Вы можете создавать по своему усмотрению (Вы сами решаете какие ячейки хранилища голосовых команд будут входить в группу). Допускается создание до 8 пользовательских групп с номерами от 00 до 07. Каждая пользовательская группа может содержать до 7 голосовых команд хранилища.
Допускается создание до 8 пользовательских групп с номерами от 00 до 07. Каждая пользовательская группа может содержать до 7 голосовых команд хранилища.
Управлять группами можно, как с использованием методов библиотеки VoiceRecognitionV3, так и при помощи команды протокола VR3.
Ссылки:
- Модуль распознавания голоса — Voice Recognition Module V3.1.
- Библиотека VoiceRecognitionV3.
- Wiki — Установка библиотек в Arduino IDE.
- Wiki — Протокол VR3 для модуля распознавания голоса.
Распознавания голоса на Arduino – Радиодед
Тема распознавания голоса микроконтроллером довольно интересна и нова, поэтому я решил представить вам схему устройства распознавания голоса на микроконтроллере, а точнее на Arduino. Распознавание голоса довольно непростая задача, а реализовать это на микроконтроллере еще сложнее, в силу ограниченности его ресурсов. В нашем случае реализация распознавания голоса будет на микроконтроллере ATmega328P, работающего на частоте 16МГц.
В данном устройстве была использована библиотека uSpeech, которая полностью автономна и не требует передачи голосовых команд на компьютер для дальнейшего распознавания, как того требуют другие библиотеки и модули, например, такие как BitVoicer.
В моей схеме распознавания голоса на микроконтроллере была использована uSpeech в силу своей автономности и малых размеров. Хотя у неё есть недостаток, такой как ограниченность распознавания. Эта библиотека позволяет распознавать только фонемы, т.е. отдельные звуки, но для многих схем и устройств этого более чем достаточно. Ниже приведен список используемых фонем (звуков):
| Фонема (звук) | Соответствующая ей буква (может быть несколько) |
| «е» | е |
| «х» | х, ш, щ, дж, ж, з |
| «в» | в, может срабатывать на з |
| «ф» | ф |
| «с» | с |
| «о» | о, а, ш, л, м, н, у, ю |
| » « | слишком тихий звук |
В качестве микрофона используется электретный микрофон (ссылка на статью на Wikipedia), обычно он выглядит так:
Сигнал с него достаточно слабый, поэтому его необходимо усилить.
Либо можно купить готовый микрофон с усилителем на eBay или AliExpress, найти можно по запросу «Mic amplifier arduino» или «Микрофонный усилитель Arduino». Выглядит он так:
Микрофон с микрофонным усилителем желательно подключить к микроконтроллеру через резистор 470…2К и разделительный конденсатор (он уже есть в самих схемах усилителей, а также на готовых платах), который убирает постоянную составляющую.
Схема подключения микрофона и усилителя к Arduino следующая: микрофон через усилитель подключается к аналоговому порту Ардуино A0, три светодиода через резисторы подключаются к цифровым выходам 5,6,7 (схему можно изменить, внеся соответствующие, небольшие правки в исходный код программы).
В качестве индикаторов распознанных команд были использованы три светодиода разных цветов.
В исходном примере библиотеки uSpeech сравнивались одиночные фонемы (звуки).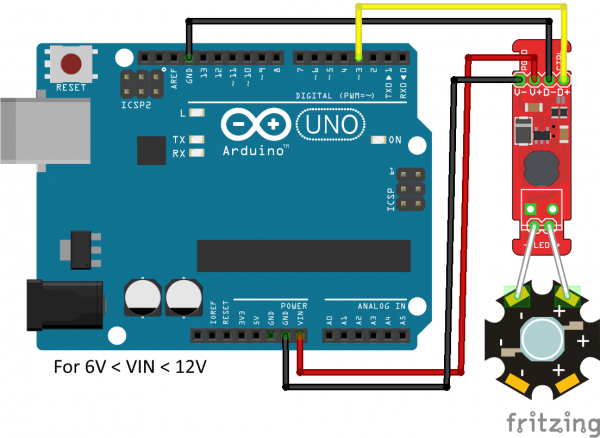 Пример позволял распознать 6 фонем (звуков): «ф», «е», «о», «в», «с», «х» (f, e, o, v, s, h). Мной был использован массив байт, который содержал паттерны, распознаваемых слов, что позволило в конечном итоге распознавать не отдельные фонемы (звуки), а целые слова, состоящие из распознаваемых фонем. Массив полученных звуков сравнивается с заранее прописанным массивом байт (паттерном слова), и в случае совпадения, с учетом заданного порога чувствительности, делается вывод о том, какое слово было произнесено.
Пример позволял распознать 6 фонем (звуков): «ф», «е», «о», «в», «с», «х» (f, e, o, v, s, h). Мной был использован массив байт, который содержал паттерны, распознаваемых слов, что позволило в конечном итоге распознавать не отдельные фонемы (звуки), а целые слова, состоящие из распознаваемых фонем. Массив полученных звуков сравнивается с заранее прописанным массивом байт (паттерном слова), и в случае совпадения, с учетом заданного порога чувствительности, делается вывод о том, какое слово было произнесено.
Например, заранее прописанные паттерны для английских слов green,orange и white были следующие «vvvoeeeeeeeofff», «hhhhhvoovvvvf», «hooooooffffffff». Для нахождения наиболее ближайшего эквивалента произносимом слову необходимо находить минимальное редакционное расстояние (расстояние Левенштейна). Для повышения точности и игнорирования нерелевантных паттернов при распозновании использовалась константа LOWEST_COST_MAX_THREASHOLD, определяющая уровень достоверности. Подбирая её значение можно добиться высокой точности распознавания.
Скомпилированный скетч занимает около 20% FLASH-памяти микроконтроллера и около 500 байт, т.е. 25% ОЗУ. Библиотеку для распознавания голосовых команд на Ардуино – uSpeech можно скачать здесь (необходимо нажать зеленую кнопку «Clone or download»). Установка библиотеки стандартная – необходимо распаковать архив и поместить папку в “C:/Users/<Имя пользователя>/Documents/Arduino/libraries”.
Демонстрация работы устройства:
https://www.youtube.com/watch?v=_zlD2lvWB7k
Скачать архив с исходником скетча для Arduino и самой библиотекой.
Просмотров всего: 11 906, сегодня: 4
Модуль распознавания голоса Arduino V3 в упаковке
ВАША КОРЗИНА
4 600,00 ₨
Наличие: Есть в наличии
Количество:
Добавить в список желаний
Сравнить
- Описание
- Дополнительная информация
- Отзывы (0)
Описание
Описание
Модуль распознавания голоса Arduino V3 — это компактная и простая в управлении плата распознавания речи в Пакистане.
Модуль распознавания голоса Продукт V3 представляет собой модуль распознавания голоса, зависящий от говорящего. Всего он поддерживает до 80 голосовых команд. Максимум 7 голосовых команд могут работать одновременно. Он может обучать любой звук как команду. Пользователям необходимо сначала обучить модуль, прежде чем позволить ему распознавать любую голосовую команду.
Эта плата имеет 2 способа управления: последовательный порт (полная функция), общие входные контакты (часть функции). Общие выходные контакты на плате могут генерировать несколько типов волн, пока она распознает соответствующую голосовую команду.
Каковы обновленные функции?
У нас есть модуль распознавания голоса V2, и он поддерживает всего 15 команд и только 5 команд одновременно. В V2 голосовые команды разделены на 3 группы во время обучения. И только одну группу (5 команд) можно было импортировать в Распознаватель. Это означает, что одновременно действуют только 5 голосовых команд.
В V3 голосовые команды хранятся в одной большой группе наподобие библиотеки. Любые 7 голосовых команд из библиотеки можно импортировать в распознаватель. Это означает, что одновременно действуют 7 команд.
Любые 7 голосовых команд из библиотеки можно импортировать в распознаватель. Это означает, что одновременно действуют 7 команд.
В комплект входит:
- 1 модуль распознавания голоса Arduino V3
- Жатка 90 градусов
Технические характеристики:
- Напряжение: 4,5–5,5 В.
- Ток: <40 мА.
- Цифровой интерфейс: уровень TTL 5 В для интерфейса UART и GPIO.
- Аналоговый интерфейс: 3,5-мм разъем для моноканального микрофона + контактный интерфейс для микрофона.
- Размеры: 30 х 48 х 7 (ДхШхВ) мм.
- Точность распознавания: 99% (в идеальных условиях).
- Поддерживает до 80 голосовых команд, каждый голос 1500 мс (произнесение одного или двух слов).
- Максимум 7 голосовых команд действуют одновременно. В комплекте поставляется библиотека Arduino
- .
- Простое управление: UART/GPIO.
- Общий контактный вывод пользовательского управления.

Приложения и ссылки:
Руководство + библиотека.
Дополнительная информация
| Вес | 0,1 кг |
|---|
Рекомендуемые продукты
Нет продукта
Продукты с самым высоким рейтингом
Самые продаваемые продукты
Модуль распознавания голоса — Mikroelectron MikroElectron — интернет-магазин электроники в Аммане
Модуль распознавания голоса
Описание:
Модуль распознавания голоса V3Speak to Control (совместимый с Arduino)
Обзор:
Модуль распознавания речи ELECHOUSE представляет собой компактную и простую в управлении плату распознавания речи.
Этот продукт представляет собой модуль распознавания речи, зависящий от говорящего. Всего он поддерживает до 80 голосовых команд.
Максимум 7 голосовых команд могут работать одновременно. Любой звук можно обучить как команду. Пользователям необходимо сначала обучить модуль
, прежде чем позволить ему распознавать любую голосовую команду.
Эта плата имеет 2 способа управления: последовательный порт (полная функция), общие входные контакты (часть функции). Общие
Выходные контакты на плате могли генерировать несколько видов волн, в то время как соответствующая голосовая команда
распознавалась.
Что нового?
У нас уже есть модуль распознавания голоса V2. Всего он поддерживает 15 команд и только 5 команд одновременно с
.
В V2 голосовые команды разделены на 3 группы во время обучения. И только одну группу (5
команды) можно было импортировать в Распознаватель. Это означает, что только 5 голосовых команд эффективны в 9 часов. 0003
0003
одновременно.
В V3 голосовые команды хранятся в одной большой группе наподобие библиотеки. Любые 7 голосовых команд из библиотеки
можно импортировать в распознаватель. Это означает, что одновременно действуют 7 команд.
Параметр:
- Напряжение: 4,5-5,5 В
- Ток: <40ma
- Цифровой интерфейс: 5 В TTL-уровень для интерфейса UART и GPIO
- Аналоговый интерфейс: 3,5 мммммм-мононочный интерфейс микрофон + микрофон + микрофон + микрофон + микрофон + микрофон + микрофон микрофон + микрофон микрофон + контриктор микрофон + коннектофон микрофон + контриктор микрофон + контриктор микрофон + микрофон микрофон + контриктор микрофон + контриктор микрофон + контриктор микрофон + контриктор микрофон + микрофон микрофон + контриктор микрофон + микрофон микрофон + микрофон микрофон + микрофон.
- Size: 31mm x 50mm
- Recognition accuracy: 99% (under ideal environment)
شرح :
فيديو تعليمي لكيفية استخدام الموديول بالتفصيل
 youtube.com/embed/genV0WUpd8k» frameborder=»0″>
youtube.com/embed/genV0WUpd8k» frameborder=»0″> Features:
- Support maximum 80 voice commands , с каждым голосом 1500 мс (произнесение одного или двух слов)
- Максимум 7 голосовых команд, действующих одновременно
- Поставляется библиотека Arduino
- Простое управление: UART/GPIO
- Общий контактный вывод пользовательского управления
Терминология:
- VR3 — Модуль распознавания голоса V3
- Распознаватель — контейнер, в который загружены действующие голосовые команды (максимум 7).
Является основной частью модуля распознавания голоса. Например, это работает как «игра в мячики». В вашей команде 80 игроков. Но вы не могли позволить им всем вместе играть на корте. Правило позволяет играть только 7 игрокам на площадке. Здесь Распознаватель — это список, который содержит имена игроков, работающих на корте. - Индекс распознавателя — распознаватель поддерживает не более 7 голосовых команд.
Распознаватель имеет 7 областей для каждой голосовой команды. Один индекс соответствует одному региону: 0~6 - Обучить — процесс записи ваших голосовых команд
- Загрузить — скопировать обученный голос в распознаватель
- Запись голосовой команды — записать обученную голосовую команду во flash, номер от 0 to 79
- Подпись — текстовый комментарий к записи
- Группа — помощь в управлении записями, в каждой группе 7 записей. Поддерживаются системная группа и группа пользователей.

В комплект входят:
- Модуль распознавания голоса, 1 шт.
- Микрофон, 1 шт.
42 JD
Количество 4 в наличии 42 динара 1+ шт.
