
bin, oct, hex – системы исчисления
Вспомним основы информатики и поговорим о системах исчисления. В жизни мы привыкли к десятичной системе (base-10 или decimal), железо компьютеров оперирует в системе двоичной (base-2 или binary) – нулями и единицами. Часто приходится иметь дело с системой шестнадцатиричной (base-16 или hexadecimal), она позволяет записывать данные в 8 раз короче, чем двоичная. Реже встречается система восьмеричная (base-8 или octal). Система исчисления – это всего лишь средство представления числа, т.е. то, как мы его в строчку запишем или считаем, само число остается самим собой, независимо от системы.
Чтобы получить целое число из строки, записанной в какой-то системе исчисления, используем функцию int (второй параметр – база системы):
>>> int('42') # по умолчанию 10 42 >>> int('42', 10) # тоже самое 42 >>> int('101010', 2) 42 >>> int('BEEF', 16) 48879 >>> int('7654', 8) 4012
Наоборот сделать из числа строку в какой-то системе – встроенные функции bin, oct и hex:
>>> bin(42) '0b101010' >>> hex(48879) '0xbeef' >>> oct(4012) '0o7654'
В строке появились префиксы 0b, 0x и 0o. Как и в Си, в Python можно использовать эти префиксы для записи чисел в коде помимо обычного десятичного варианта, если это требуется:
Как и в Си, в Python можно использовать эти префиксы для записи чисел в коде помимо обычного десятичного варианта, если это требуется:
>>> 0b11011, 0xDEAD, 0o777 (27, 57005, 511)
Однако, часто приходится иметь дело с чистыми HEX-данными без префиксов. Многие (да и я) делали вот так:
>>> hex(12345)[2:] '3039'
Т.е. просто отрезали первые два символа. Это не очень интуитивно, да и может привести к неправильному поведению, если передать отрицательное число:
>>> hex(-12345) '-0x3039' >>> hex(-12345)[2:] 'x3039'
К счастью, есть встроенная функция format(value, format_spec) (не путать с  format
format
>>> format(3039, 'x'), format(3039, 'X'), format(3039, '#x')
('bdf', 'BDF', '0xbdf')
>>> format(120, 'b')
'1111000'
>>> format(79, 'o')
'117'x— 16-ричное без префикса, маленькие буквX— 16-ричное без префикса, заглавные буквы#x— 16-ричное с префиксом, маленькие буквыb— двоичное число без префикса и т.д.
format(value, format_spec) эквивалентная вызову type(value).__format__(value, format_spec).
🐉 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈
6 911
16-ричные8-ричныеbinformathexoctpythonдвоичныепреобразование чиселсистемы исчислениястрокиуроки программированияформатирование
Tirinox
Восьмеричная и шестнадцатеричная системы счисления
Планирование уроков на учебный год (по учебнику К. Ю. Полякова, Е.А. Еремина, базовый уровень)
Ю. Полякова, Е.А. Еремина, базовый уровень)
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год (по учебнику К.Ю. Полякова, Е.А. Еремина, базовый уровень) | Восьмеричная и шестнадцатеричная системы счисления
Содержание урока
§12. Восьмеричная система счисления§13. Шестнадцатеричная система счисленияШестнадцатеричная система счисления
Алгоритм перевода шестнадцатеричного числа в двоичную систему счисления
Алгоритм перевода двоичного числа в шестнадцатеричную систему счисления
Вопросы и задания
Задачи
Алгоритм перевода двоичного числа в шестнадцатеричную систему счисления
1. Разбить двоичное число на тетрады, начиная справа.
В начало самой первой тетрады добавить слева нули, если это необходимо.
2. Перевести каждую тетраду (отдельно) в шестнадцатеричную систему счисления.
3. Соединить полученные цифры в одно «длинное» число.
Например: 10000100001010101111002 = 10 0001 0000 1010 1011 11002 = 210АВС16.
Шестнадцатеричная система оказалась очень удобной для записи значений ячеек памяти. Байт в современных компьютерах представляет собой 8 соседних битов, т. е. две тетрады. Таким образом, значение байтовой ячейки можно записать как две шестнадцатеричные цифры:
Каждый полубайт (4 бита) «упаковывается» в одну шестнадцатеричную цифру. Благодаря этому замечательному свойству, шестнадцатеричная система в сфере компьютерной техники практически полностью вытеснила восьмеричную
1 Начиная с 1964 года, когда шестнадцатеричная система стала широко использоваться в документации на новый компьютер IBM/360.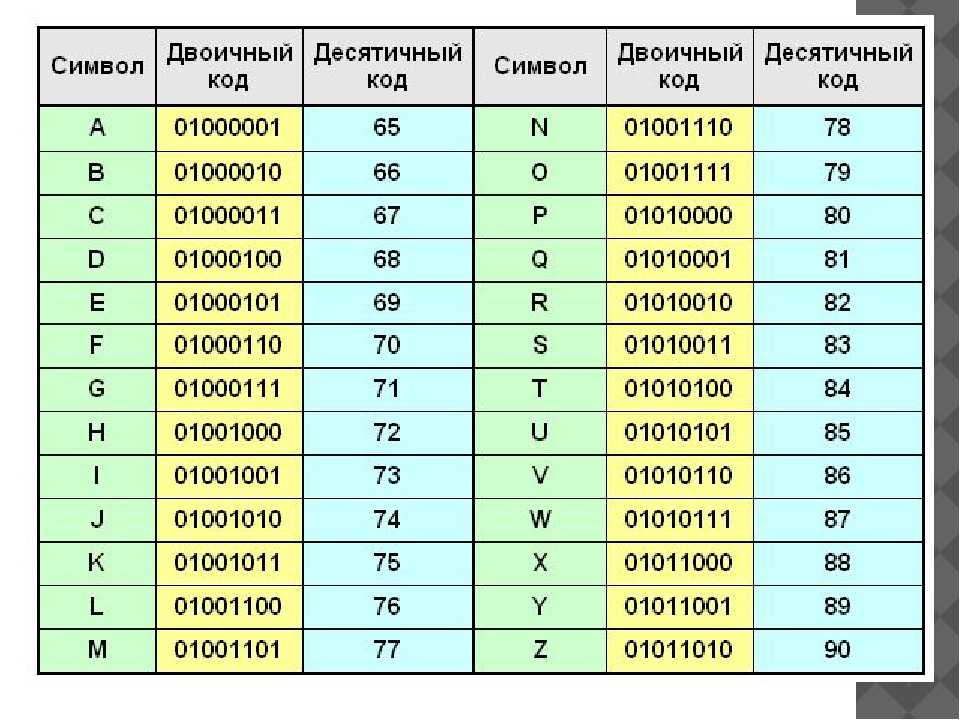
Перевод из шестнадцатеричной системы в восьмеричную (и обратно) удобнее выполнять через двоичную систему. Можно, конечно, использовать и десятичную систему, но в этом случае объём вычислений будет значительно больше.
При выполнении сложения нужно помнить, что в системе с основанием 16 перенос появляется тогда, когда сумма в очередном разряде превышает 15. Удобно сначала переписать исходные числа, заменив все буквы на их численные значения:
При вычитании заём из старшего разряда равен 1016 = 16, а все «промежуточные» разряды заполняются цифрой F — старшей цифрой системы счисления:
Если нужно работать с числами, записанными в разных системах счисления, их сначала переводят в какую-нибудь одну систему. Например, пусть требуется сложить 538 и 5616 и записать результат в двоичной системе счисления. Здесь можно выполнять сложение в двоичной, восьмеричной, десятичной или шестнадцатеричной системе. Переход к десятичной системе, а потом перевод результата в двоичную трудоёмок.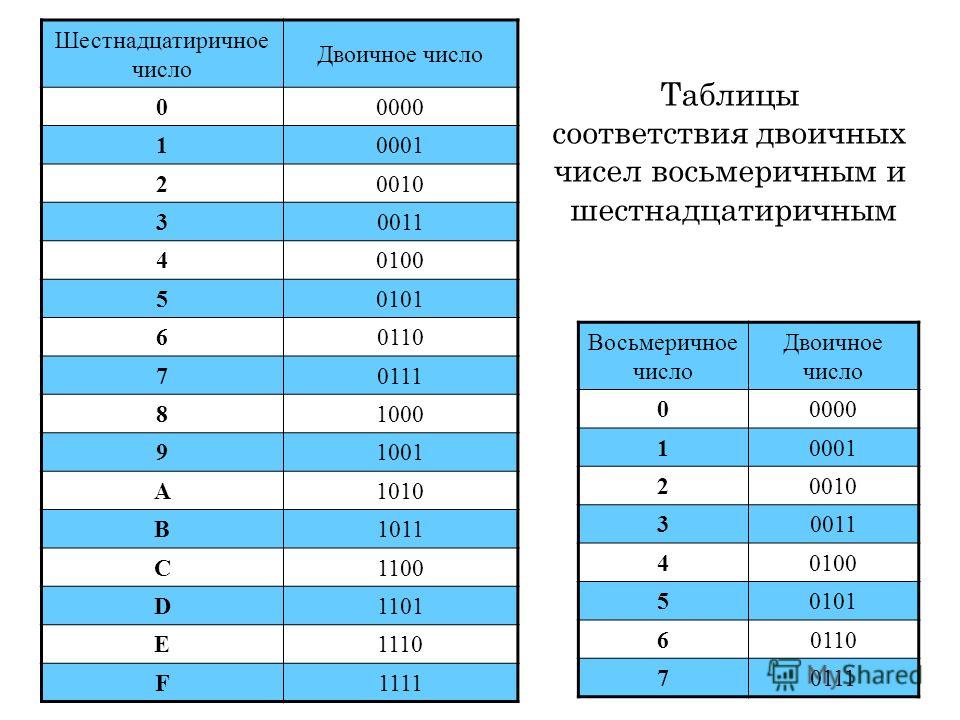
538 = 101 0112 = 10 10112 = 2В16.
Теперь сложим числа в 16-ричной системе:
2В16 + 5616 = 8116
и переведём результат в двоичную систему:
8116 = 1000 00012.
Следующая страница Вопросы и задания
Cкачать материалы урока
Шестнадцатеричные слова
Шестнадцатеричная система счисления (основание 16) имеет следующие цифры:
0 1 2 3 4 5 6 7 8 9 A B C D E F
0–9 имеют свои обычные значения, но A=10, B=11, С=12, Г=13, Е=14 и Ж=15. Считая ноль буквой O, можно составить список слов, состоящих из букв ABCDEFO. Калькулятор Windows может конвертировать десятичные и шестнадцатеричные числа.
- Если в меню доступны и «Программист», и «Научный», щелкните «Программист», в противном случае нажмите «Научный».
- Для преобразования выполните одно из следующих действий:
- Выберите HEX, введите буквы и затем выберите DEC.
- Выберите DEC, введите число и затем выберите HEX.
| Hexadecimal | Decimal |
|---|---|
| ABED | 44013 |
| AB0DE | 700638 |
| ACCEDE | 11325150 |
| ACE | 2766 |
| AD | 173 |
| ADD | 2781 |
| ADDED | 712173 |
| AD0 | 2768 |
| AD0BE | 708798 |
| BABE | 47806 |
| BAD | 2989 |
| BADE | 47838 |
| BA0BAB | 12192683 |
| BE | 190 |
| BEAD | 48813 |
| BED | 3053 |
| BEE | 3054 |
| BEEF | 48879 |
| B0A | 2826 |
| B0B | 2827 |
| B0DE | 45278 |
| B00 | 2816 |
| CAB | 3243 |
| CACA0 | 830624 |
| CAFE | 51966 |
| CEDE | 52958 |
| C0 | 192 |
| C0B | 3083 |
| C0CA | 49354 |
| C0C0 | 49344 |
| C0C0A | 789514 |
| C0D | 3085 |
| C0DA | 49370 |
| C0DE | 49374 |
| C0FFEE | 12648430 |
| C00 | 3072 |
| DAB | 3499 |
| DAD | 3501 |
| DE | 222 |
| DEAD | 57005 |
| DEAF | 57007 |
| DECADE | 14600926 |
| DEC0DE | 14598366 |
| DEED | 57069 |
| DEFACE | 14613198 |
| D0 | 208 |
| D0D0 | 53456 |
| D0E | 3342 |
| D0FF | 53503 |
| EBB | 3771 |
| EFFACE | 15727310 |
| FACADE | 16435934 |
| FACE | 64206 |
| FAD | 4029 |
| FAD | 4029 |
| FAD | 4029 |
| 4028 4029 | |
. 0026 0026 | |
| FADE | 64222 |
| FED | 4077 |
| FEE | 4078 |
| FEED | 65261 |
| F0B | 3851 |
| F0E | 3854 |
| F00D | 61453 |
Источники
- Список английских слов из ftp://ftp.univie.ac.at/security/dictionaries/, который был отфильтрован
Readme
- README от ftp://ftp.univie.ac.at/security/dictionaries/
На других языках
- Heksadesimale ord (норвежский)
Происхождение английского алфавита (и всех его 26 букв)
Обновлено в 2022 году
Английский алфавит имеет увлекательную историю, и развитие каждой буквы алфавита имеет свою собственную историю. Хотя английский язык широко распространен, для тех, кто не говорит по-английски, английский язык является одним из самых сложных для изучения. В самом деле, в английском языке много общего, потому что за годы его развития появилось несколько разных языков. Ученые, миссионеры и завоеватели превратили английский язык в то, что мы знаем и на чем говорим сегодня.
В самом деле, в английском языке много общего, потому что за годы его развития появилось несколько разных языков. Ученые, миссионеры и завоеватели превратили английский язык в то, что мы знаем и на чем говорим сегодня.
Происхождение алфавитного письма
Раннее алфавитное письмо появилось около четырех тысяч лет назад. По мнению многих ученых, именно в Египте зародилась алфавитная письменность между 1800 и 1900 годами до нашей эры. Происхождением была протосинайская (протоханаанская) форма письма, которая была не очень хорошо известна.
Примерно через 700 лет финикийцы разработали алфавит, основанный на более ранних основах. Он широко использовался в Средиземноморье, включая южную Европу, Северную Африку, Пиренейский полуостров и Левант. Алфавит состоял из 22 букв, все согласные.
В 750 г. до н.э. греки добавили гласные в финикийский алфавит, и эта комбинация считалась первоначальным истинным алфавитом. Это было воспринято латинянами (римлянами) и объединено с некоторыми этрусскими буквами, такими как буквы S и F. Примерно в третьем веке древняя латиница удалила буквы G, J, V/U, W, Y и Z. Когда Римская империя управляла частями мира, они ввели латинский алфавит, полученный из латинской версии, хотя буквы J, U/V и W по-прежнему не использовались.
Примерно в третьем веке древняя латиница удалила буквы G, J, V/U, W, Y и Z. Когда Римская империя управляла частями мира, они ввели латинский алфавит, полученный из латинской версии, хотя буквы J, U/V и W по-прежнему не использовались.
Эволюция английского алфавита
Когда Римская империя достигла Британии, она принесла с собой латинский язык. Британия в то время находилась под контролем англосаксов, германского племени, использовавшего древнеанглийский язык в качестве своего языка. В то время в древнеанглийском языке использовался футорк, более старый алфавит. Его также называли руническим алфавитом.
Древнеанглийский
Сочетание латинского алфавита и рунического алфавита Футорка привело к современному английскому алфавиту. Некоторые из дополнений из рунических алфавитов были «шип» со звуком «т» и «винн» со звуком «у». Помните, что в латинском алфавите не было буквы «w». В Средние века, когда люди в Британии перестали использовать старые руны, буква thorn была заменена буквой th, а руническое wynn превратилось в uu, которое позже превратилось в w.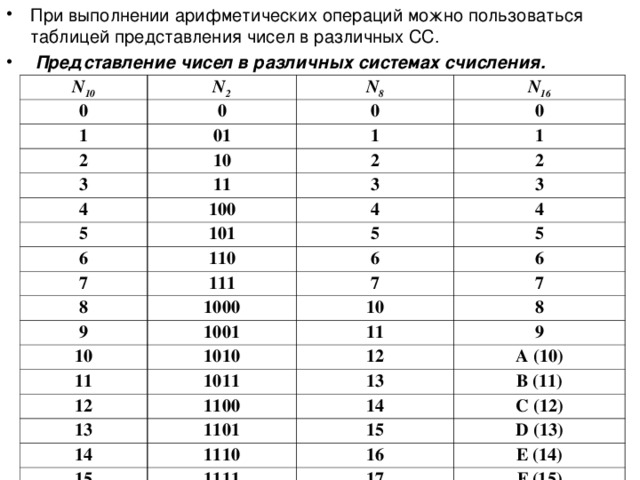 0003
0003
Позже в тот же период были добавлены буквы «j» и «u», и количество букв увеличилось до 26. Однако были включены буквенные комбинации, такие как «æ», «œ» и символ амперсанда (&). в алфавите.
Среднеанглийский
Когда норманны вторглись в Британию в 1066 г. н.э., низкорожденные использовали древнеанглийский язык. Ученые, духовенство и дворянство писали и говорили на латыни или нормандском языке. После двух столетий норманнского правления письмо на английском языке снова стало популярным, при этом некоторые древнеанглийские буквы были удалены. Джеффри Чосер использовал среднеанглийский язык в «Кентерберийских рассказах» «Купальная жена».
Современный английский
В 15 веке печатный станок был представлен в Великобритании Уильямом Кэкстоном. К этому времени английский язык был стандартизирован. Из-за взаимозаменяемости буквы V и U были разделены, при этом первая стала согласной, а U — гласной.
The Table Alphabeticall, первый словарь на английском языке, опубликованный Робертом Кодри в 1604 году. Буква J также была добавлена в современный английский язык в это время.
Что такое алфавит?
Буквы, используемые языком, в совокупности называются алфавитом. Он имеет фиксированный порядок, основанный на обычаях пользователей. Алфавит используется для письма, а символы, используемые для письма, называются буквами. Каждая буква представляет один звук или родственный звук (также называемый фонемой), используемый в разговорной речи. Алфавит с помощью стандартного направления чтения, пробелов и знаков препинания образует слова, легко читаемые читателями.
Рассказы о буквах английского алфавита
Вероятно, вы один из многих людей, выучивших английский алфавит в очень раннем возрасте. Ваши родители могли научить вас произносить алфавит наизусть, а также петь «Алфавитную песенку». Но когда вы достигаете дошкольного возраста, вы уже знаете большинство букв английского алфавита и можете составлять простые слова. Когда вы пошли в школу, вы снова познакомились с английским алфавитом и выучили больше слов, комбинируя буквы.
Поскольку вы начали с изучения английского алфавита, вполне естественно, что вы принимаете его как должное и не проявляете интереса к изучению его истории и истории образования каждой буквы.
Современный алфавит из 26 букв появился в 16 веке. На развитие английского алфавита оказали влияние семитские, финикийские, греческие и римские сценарии. Очень интересно узнать, как образовалась каждая буква.
Буква А
Первоначальная форма буквы А была перевернутой. Он был представлен в 1800-х годах. Будучи перевернутым, он выглядел как голова животного с рогами или оленями. Это было уместно, потому что в древнесемитском языке эта буква переводится как «бык».
Буква B
В своей первоначальной форме буква B была заимствована из египетских иероглифов, и буква располагалась на животе. В своем первоначальном виде он выглядел как дом с дверью, крышей и комнатой. Символ представлял собой «убежище» около 4000 лет назад.
Письмо C
Письмо пришло от финикийцев. Он имел форму бумеранга или охотничьей палки. Греки называли его «гамма», и вместо того, чтобы писать в другом направлении, он был перевернут в том направлении, в котором он пишется сегодня, а итальянцы придали ему лучшую форму полумесяца.
Буква D
«Далет» — это название, данное букве D финикийцами в 800 г. до н.э. Первоначально он выглядел как грубый треугольник, обращенный влево. Первоначальное значение буквы — «дверь». Когда греки приняли алфавит, они дали ему название «дельта». Позже оно было перевернуто, и римляне придали правой стороне буквы форму полукруга.
Буква ЕОколо 3800 лет назад буква «Е» в семитском языке произносилась как «Н». Он был похож на фигурку человека с двумя руками и одной ногой. В 700 г. до н.э. гики перевернули его и изменили произношение на звук «и».
Буква F Буква «F» была финикийской и больше походила на «Y». Когда она произносилась в то время, звук был близок к «вау». «дигамма» и изменили его, чтобы он напоминал современную букву «Ф».0003
Буква G
Буква «G» произошла от «зета» греков. Сначала это выглядело как «я», но произношение сделало звук «ззз». Римляне изменили его форму около 250 г. до н.э., придав ему верхнюю и нижнюю части и звук «г». В латыни не было звука «з». В ходе его развития прямые линии стали изогнутыми, закончив его нынешнюю серповидную форму.
Буква H
Буква «H» пришла от египтян и использовалась как символ забора. При произнесении он издавал хриплый звук, поэтому ранние академики считали, что в этом нет необходимости, а британские и латинские ученые в конце концов исключили букву H из английского алфавита примерно к 500 году нашей эры.
Буква I
Буква «I» называлась «йод» в 1000 г. до н.э. Это означало руку и руку. Греки назвали его «йота» и сделали вертикальным. В своей эволюции она превратилась в прямую линию около 700 г. до н.э.
Буква J
Буква «I» также использовалась для обозначения звука «J» в древние времена. Он получил свою форму письма в 15 веке как вклад испанского языка. Только около 1640 года письмо регулярно появлялось в печати.
Буква К
Буква «К» — старая буква, так как она произошла от египетских иероглифов. На семитском языке ему дали название «каф», что переводится как «ладонь». В те времена буква была обращена в другую сторону. Когда греки приняли его в 800 г. до н.э., он стал «каппа» и перевернулся вправо.
Буква L
В древнесемитском языке современная буква «L» была перевернутой. Таким образом, это выглядело как крючковатое письмо. Он уже назывался «Эль», что означало «Бог». Финикийцы были ответственны за то, что придали ему перевернутый вид, с крюком, обращенным влево. Они немного поправили крюк и изменили название на «ламед» (произносится «лах-мед»), погонщик для скота. Греки называли его «лямбда» и поворачивали вправо. Окончательный вид буквы «L» с прямой ногой под прямым углом был любезно предоставлен римлянами.
Буква М
Происхождение буквы «М» было волнистыми вертикальными линиями с пятью вершинами, которые, по мнению египтян, символизировали воду. В 1800 г. до н.э. семиты сократили линии до трех волн, а финикийцы убрали еще одну волну. В 800 г. до н.э. вершины были превращены в зигзаги и перевернуты по горизонтали, образуя букву М, которую мы знаем сегодня.
Буква N
Другим египетским символом была буква «N», которая первоначально выглядела как маленькая рябь поверх более крупной ряби, которая обозначала кобру или змею. Древние семиты придали ему звук «н», что символизировало «рыбу». Около 1000 г. до н. э. появилась только одна рябь, и греки назвали ее «ню».0003
Буква О
Буква «О» также пришла от египтян. Он назывался «глаз» по-египетски и «айин» по-семитски. Финикийцы еще больше сократили иероглифы, оставив только контур зрачка.
Буква P
В древнем семитском языке сегодняшняя буква «P» выглядела как перевернутая «V». Она произносилась как «pe», что означало «рот». Финикийцы превратили ее вершину в форму диагонального крючка. В 200 г. до н.э. римляне перевернули его вправо и замкнули петлю, образовав букву «П».0003
Буква Q
Первоначальный звук буквы «Q» был похож на «qoph», что переводится как клубок шерсти или обезьяна. Первоначально он был написан как круг, пересекаемый вертикальной линией. В римских надписях около 520 г. до н.э. буква появилась такой, какой мы ее знаем сегодня.
Буква R
Профиль человека, обращенного влево, был первоначальной формой буквы «R», написанной семитами. Оно произносилось как «реш», что означало «голова». Римляне повернули его вправо и добавили наклонную ногу.
Буква S
Буква «S» раньше выглядела как горизонтальная волнистая буква W, которая использовалась для обозначения лука лучника. Угловатость формы была от финикийцев, которые дали ему название «голень», что переводится как «зуб». Римляне перевернули его в вертикальное положение и назвали «сигма», в то время как римляне перевернули его в положение, которое буква имеет сегодня.
Буква Т
Древние семиты использовали строчную форму буквы «Т», которую мы видим сегодня. Финикийцы называли букву «тау» (знак), которая при произнесении звучала как «ти». Греки называли его «тау». Они также добавили крест в верхней части буквы, чтобы отличить ее от буквы «X»9.0003
Буква U
Буква «U» изначально выглядела как «Y» в 1000 г. до н.э. В то время его называли «вав», что означало «колышек». У греков он назывался «ипсилон». Различие начало появляться примерно в 1400-х годах.
Буква W
Буква «W» появилась в средние века, когда писцы Карла Великого писали две буквы «u» рядом, разделенные пробелом. В то время издаваемый звук был похож на «в». Буква появилась в печати как уникальная буква «W» в 1700 году.
Буква X
Буква «кси» у древних греков звучала как «Х». Строчная форма буквы «Х» встречалась в рукописных рукописях, доступных в средние века. Итальянские печатники конца 15 века также использовали строчные буквы «X».
Буква Y
Буква Y, начинавшаяся как «ипсилон», была добавлена римлянами в 100 г. н.э.
Буква Z
Раньше у финикийцев была буква «заин». Она означала «топор». Первоначально она выглядела как буква «I» с засечками вверху и внизу. Примерно в 800 г. до н.э. греки приняли его как «зета» и присвоили ему звук дз. Он не использовался в течение нескольких столетий до прихода нормандских французов и их слов, которые нуждались в звуке буквы «Z».0003
Alphabet Aside…
Компания Day Translations, Inc. занимается письменным и устным переводом на английском и более чем на 100 других языков. Будьте уверены, что наши языковые услуги оказывают опытные и сертифицированные профессионалы. Все наши команды устных и письменных переводчиков являются носителями языка. Они также являются экспертами в предметной области и способны выполнять специальные проекты по письменному и устному переводу. Если вам нужны срочные языковые услуги, вы можете немедленно связаться с Day Translations, позвонив по телефону 1-800-9.