
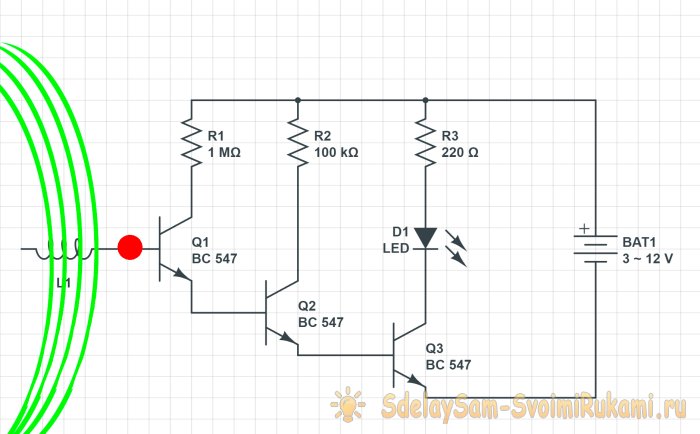
простой детектор зева с использованием ориентиров на лице
MachNEase от Nam — Машинное обучение стало проще, Намитха Гурупрасад
Вы когда-нибудь задумывались, сколько раз вы зеваете каждый день ?! Неаайы…. У нас есть дела поважнее !!!
Хотите узнать, сколько у вас зевок? Что ж, вы всего в одном шаге !!
- Человеческие лица значительно передают и эффективно выражают чувства благодаря сокращению различных лицевых мышц.
- Крайняя усталость, скука и отсутствие интереса — это первопричины сонливости и, в конечном итоге, зевоты.
- Определение ориентиров на лице — радикальный подход к обнаружению зевки.
- Следовательно, логично ожидать, что эффективная система обработки изображений лица может быть разработана с использованием компьютерного зрения.
УСТАНОВИТЕ И ИМПОРТ ОСНОВНЫХ БИБЛИОТЕК:
- OpenCV — библиотека функций программирования, в основном предназначенная для компьютерного зрения в реальном времени (Документация).

pip install opencv-python
- DLib — универсальная кроссплатформенная программная библиотека, написанная на C ++ (Документация).
pip install dlib
- NumPy — библиотека для языка программирования Python, добавляющая поддержку больших многомерных массивов и матриц, а также большой набор высокоуровневых математических функций для работы с этими массивами (Документация)
pip install numpy
Теперь импортируйте все эти библиотеки:
import cv2 import dlib import numpy as np
ПОЛУЧИТЕ КООРДИНАТЫ ЗНАКОВ ЛИЦА:
- Чтобы найти координаты ориентиров на лицах, используется оценщик формы, реализованный в библиотеке dlib.
detector = dlib.get_frontal_face_detector() #For detecting faces landmark_path="shape_predictor_68_face_landmarks.dat" #Path of the file - if stored in the same directory.
 Else, give the relative path
predictor = dlib.shape_predictor(landmark_path) #For identifying landmarks
Else, give the relative path
predictor = dlib.shape_predictor(landmark_path) #For identifying landmarks- Оценщик дает 68 ориентиров, включая уголки глаз, кончик носа, губы и т. Д.
- Определите количество лиц, обнаруженных веб-камерой. Убедитесь, что есть только одна тема для обнаружения активности.
#Obtaining Facial Landmark coordinates
def get_facial_landmarks(image):
face = detector(image, 1)
#Detecting faces in image
if len(face) > 1:
return "Multiple faces detected in the frame!!"
if len(face) == 0:
return "No face detected in the frame!!"
#Return the coordinates
#Predictor identifies all the 68 landmarks for the detected face
return np.matrix([[pred.x, pred.y] for pred in predictor(image, face[0]).parts()])- Добавьте 68 координат ориентира на лицо на обнаруженное лицо.

#Drawing the landmarks : yellow in color
def landmarks_annotation(image, facial_landmarks):
#Different image window for facial landmarks
image = image.copy()
for coord, p in enumerate(facial_landmarks):
#Extracting coordinate values and the location / matrix of the coordinates
position = (p[0, 0], p[0, 1])
#Identify and draw the facial landmarks
cv2.putText(image, str(coord), position, cv2.FONT_HERSHEY_COMPLEX, 0.3, (0, 255, 255))
return imageВЫЧИСЛИТЕ РАССТОЯНИЕ ГУБ:
- Вычислите значение центроида
#Landmark coordinates for upper lip identified in the face
def upperlip(facial_landmarks):
ulip = []
#create an array to store the landmark coordinates of the upper lip
for i in range(50,53):
#The range is predefined in "shape_predictor_68_face_landmarks. dat"
ulip.append(facial_landmarks[i])
for i in range(61,64):
#The range is predefined in "shape_predictor_68_face_landmarks.dat"
ulip.append(facial_landmarks[i])
#Locate the mean value of the upper lip coordinates
ulip_mean = np.mean(ulip, axis=0)
return int(ulip_mean[:,1])#centroid value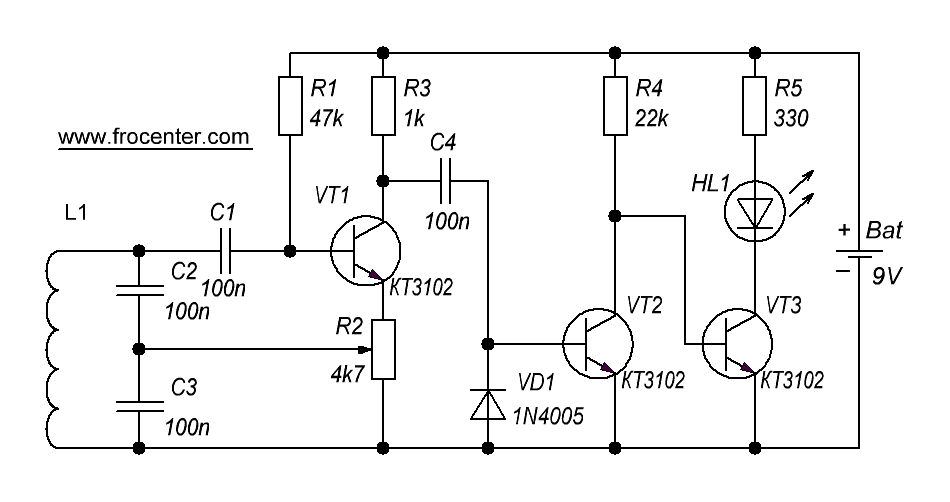 dat"
ulip.append(facial_landmarks[i])
for i in range(61,64):
#The range is predefined in "shape_predictor_68_face_landmarks.dat"
ulip.append(facial_landmarks[i])
#Locate the mean value of the upper lip coordinates
dat"
ulip.append(facial_landmarks[i])
for i in range(61,64):
#The range is predefined in "shape_predictor_68_face_landmarks.dat"
ulip.append(facial_landmarks[i])
#Locate the mean value of the upper lip coordinates
- Вычислите значение центроида нижней губы, используя ориентиры.
#Landmark coordinates for lower lip identified in the face
def lowerlip(facial_landmarks):
llip = []
#create an array to store the landmark coordinates of the lower lip
for i in range(65,68):
#The range is predefined in "shape_predictor_68_face_landmarks.dat"
llip.append(facial_landmarks[i])
for i in range(56,59):
#The range is predefined in "shape_predictor_68_face_landmarks.dat"
llip. append(facial_landmarks[i])
#Locate the mean value of the lower lip coordinates
llip_mean = np.mean(llip, axis=0)
return int(llip_mean[:,1])#centroid value append(facial_landmarks[i])
#Locate the mean value of the lower lip coordinates
llip_mean = np.mean(llip, axis=0)
return int(llip_mean[:,1])#centroid value
append(facial_landmarks[i])
#Locate the mean value of the lower lip coordinates
llip_mean = np.mean(llip, axis=0)
return int(llip_mean[:,1])#centroid value- Определите зевоту, вычислив расстояние между верхней и нижней губами, используя их соответствующие центроиды.
#Detect the yawning activity
def yawning(image):
#Obtain the facial Landmark coordinates
facial_landmarks = get_facial_landmarks(image)
if type(facial_landmarks) == str:
return image, 0
#Obtain the frame / image with annotated facial landmarks
landmarks_image = landmarks_annotation(image, facial_landmarks)
#Obtain Lip centroids
upperlip_centroid = upperlip(facial_landmarks)
lower_lip_centroid = lowerlip(facial_landmarks)
#Calculate the distance between the centroids
lips_dist = abs(upperlip_centroid - lower_lip_centroid)
return landmarks_image, lips_distОТОБРАЖЕНИЕ СОСТОЯНИЯ ЗЕЗЫВАНИЯ И ПОДСЧЕТА: (Игра начинается !!!!)
- Инициализировать статус зевоты и считать
yawn_status = False yawn_count = 0
- Создайте объект прямой трансляции
video_capture = cv2.VideoCapture(0)

- Определите зевоту, вызвав ее функцию
while True:
_, image_frame = video_capture.read()
#Identify the yawning activity
landmarks_image, lips_dist = yawning(image_frame)
#Update the yawn status
previous_status = yawn_status- Убедитесь, что расстояние между губами эксцентрично
(порог: субъективно) [Здесь выявляется и учитывается ваш зевок: D]
- Если да, то отобразите
#comes under while loop
#lips distance is subjective and changes from subject to subject based on their facial structures
if lips_dist > 40:
yawn_status = True
output_text = " Number of Yawns: " + str(yawn_count + 1)
cv2.putText(image_frame, "You are yawning", (50,450), cv2.FONT_HERSHEY_COMPLEX, 1,(255,255,0))
cv2. putText(image_frame, output_text, (50,50), cv2.FONT_HERSHEY_COMPLEX, 1,(0,0,255))
else:
yawn_status = False
if previous_status == True and yawn_status == False:
yawn_count += 1  putText(image_frame, output_text, (50,50), cv2.FONT_HERSHEY_COMPLEX, 1,(0,0,255))
else:
yawn_status = False
if previous_status == True and yawn_status == False:
yawn_count += 1
putText(image_frame, output_text, (50,50), cv2.FONT_HERSHEY_COMPLEX, 1,(0,0,255))
else:
yawn_status = False
if previous_status == True and yawn_status == False:
yawn_count += 1- Создайте 2 отдельных окна:
- Ориентиры на лице
- Активность зевки
cv2.imshow('Facial Landmarks', landmarks_image )
cv2.imshow('Yawning Activity Detection', image_frame )- Нажмите Q, чтобы остановить это обнаружение.
if cv2.waitKey(1) & 0xFF == ord('q'):
break- Это хорошая привычка наводить порядок, который вы натворили. Следовательно, завершите работу объекта веб-камеры и сбросьте все открытые окна.
video_capture.release() cv2.destroyAllWindows()
ИСПОЛНЕНИЕ:
Зайдите в свой терминал и вставьте следующую команду:
Здесь имя файла: «yawn_detector. py»
py»
python yawn_detector.pyYIPPPEEEE !!! ВЫ ПРОСТО ЗАКОНЧИЛИ ЗЕВАТЬ И УВИДЕЛИ РТ НА ШИРОКУ !!!!!!
ЖДАТЬ !! Вы только что скопировали и вставили все долбанные блоки кода ????? Что ж, это было утомительно. Неважно, вы узнали что-то новое и захватывающее …
Вы можете найти ВСЕ КОДЫ здесь: https://github.com/nam1410/MachNEase—Simple-Yawn-Detector-using-Facial-Landmarks
Заинтересованы в машинном обучении, науке о данных и т. Д. ?? :
Погрузитесь в этот океан с помощью
MachNEase with Nam
Я буду загружать простые / реализуемые проекты в свой профиль. Следите за аккаунтом, чтобы получать потрясающие, адаптированные под любые запросы.
Свяжитесь со мной по адресу:
LinkedIn: https://www.linkedin.com/in/namitha-guruprasad-216362155/
Намитха Гурупрасад, студент, Бангалор, Индия
Простой детектор миганий с использованием небольшой сверточной нейронной сети с Python
Сегодня мы собираемся разработать приложение для компьютерного зрения, которое будет определять, открыты или закрыты глаза, и подсчитывать моргания. Для достижения нашей цели мы собираемся обучить небольшую сверточную нейронную сеть (CNN) с помощью Keras, а затем, используя OpenCV и dlib, мы реализуем наш детектор миганий.
Для достижения нашей цели мы собираемся обучить небольшую сверточную нейронную сеть (CNN) с помощью Keras, а затем, используя OpenCV и dlib, мы реализуем наш детектор миганий.
Процесс создания нашего детектора моргания состоит из двух этапов: сначала обучение нейронной сети, а затем разработка детектора. Если хотите, можете пропустить первый этап и перейти ко второму и использовать сеть, которую мы уже подготовили для вас. Вы можете найти код в моем репозитории на github.
Этап первый
На этом этапе мы предположим, что вы уже достаточно много знаете о сверточных нейронных сетях. Это потому, что мы не будем говорить о том, как работает cnn. Если вы впервые слышите о cnn’s, переходите сразу ко второму этапу. В Стэнфорде есть отличный курс, который поможет вам многое понять о нейронных сетях и CNN.
Для начала давайте посмотрим, что нам нужно для обучения нашей cnn. Мы будем использовать библиотеку keras с бэкэндом tensorflow, keras дает вам возможность использовать его с бэкэндом tensorflow или theano. Также вы можете использовать python 2.7 или python 3.x. Если в вашей системе нет keras или tenorflow, вы можете
Также вы можете использовать python 2.7 или python 3.x. Если в вашей системе нет keras или tenorflow, вы можете
$ pip install --upgrade tensorflow
а также
$ pip install keras
, tensorflow поддерживает CUDA, если у вас есть графический процессор с поддержкой CUDA, но для этого руководства это не будет иметь большого значения.
Итак, мы собираемся обучить двоичный классификатор между открытыми и закрытыми глазами. Для этого нам понадобится набор данных для обучения нашего классификатора. Для закрытых глаз мы будем использовать кадрированные изображения размером 26×34 из набора данных Closed Eyes In The Wild (CEW), а для открытых глаз мы использовали изображения с ручным анотированием. Мы собираемся использовать только изображения для левого глаза, потому что наш набор данных невелик, и мы хотим, чтобы cnn был более точным, чтобы добиться того, чтобы мы перевернули правильные изображения, когда мы обрезали все изображения лица. Полный набор данных содержит 2874 изображения.
Для начала импортируем необходимые пакеты:
import csv import numpy as np import keras from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Conv2D,Flatten,Dense,Activation,Dropout,MaxPooling2D from keras.activations import relu from keras.optimizers import Adam
Теперь, когда мы импортировали все, что нам нужно для загрузки данных из набора данных, для этого мы собираемся написать функцию
def readCsv(path): with open(path,’r’) as f: #read the scv file with the dictionary format reader = csv.DictReader(f) rows = list(reader) #imgs is a numpy array with all the images #tgs is a numpy array with the tags of the images imgs = np.empty((len(list(rows)),height,width,1),dtype=np.uint8) tgs = np.empty((len(list(rows)),1)) for row,i in zip(rows,range(len(rows))): #convert the list back to the image format img = row[‘image’] img = img.
 strip(‘[‘).strip(‘]’).split(‘, ‘)
im = np.array(img,dtype=np.uint8)
im = im.reshape((26,34))
im = np.expand_dims(im, axis=2)
imgs[i] = im
#the tag for open is 1 and for close is 0
tag = row[‘state’]
if tag == ‘open’:
tgs[i] = 1
else:
tgs[i] = 0
#shuffle the dataset
index = np.random.permutation(imgs.shape[0])
imgs = imgs[index]
tgs = tgs[index]
#return images and their respective tags
return imgs,tgs
strip(‘[‘).strip(‘]’).split(‘, ‘)
im = np.array(img,dtype=np.uint8)
im = im.reshape((26,34))
im = np.expand_dims(im, axis=2)
imgs[i] = im
#the tag for open is 1 and for close is 0
tag = row[‘state’]
if tag == ‘open’:
tgs[i] = 1
else:
tgs[i] = 0
#shuffle the dataset
index = np.random.permutation(imgs.shape[0])
imgs = imgs[index]
tgs = tgs[index]
#return images and their respective tags
return imgs,tgsЭта функция принимает единственный обязательный параметр — путь к CSV-файлу с набором данных.
Сначала мы читаем файл csv в формате словаря, а затем составляем список с каждой строкой файла. Затем мы создаем два пустых массива numpy для хранения изображений и тега каждого изображения. После этого мы обращаемся к каждой строке списка, который содержит изображение и тег изображения, чтобы подтвердить предыдущие массивы их значений. В конце мы перемешиваем два массива и возвращаем их.
Итак, чтобы продолжить, мы собираемся построить нашу cnn, используя keras. В нашей сети есть три сверточных фильтра с активацией relu, за каждым фильтром следует слой максимального объединения. Затем мы добавляем dropout слой, за которым следуют два полностью связанных слоя с также активацией relu. Наконец, мы добавляем одиночный нейрон с сигмовидной активацией для нашего бинарного классификатора. В качестве оптимизатора мы будем использовать адам, а для нашей функции потерь мы будем использовать бинарную кроссэнтропию.
В нашей сети есть три сверточных фильтра с активацией relu, за каждым фильтром следует слой максимального объединения. Затем мы добавляем dropout слой, за которым следуют два полностью связанных слоя с также активацией relu. Наконец, мы добавляем одиночный нейрон с сигмовидной активацией для нашего бинарного классификатора. В качестве оптимизатора мы будем использовать адам, а для нашей функции потерь мы будем использовать бинарную кроссэнтропию.
#make the convolution neural network def makeModel(): model = Sequential() model.add(Conv2D(32, (3,3), padding = ‘same’, input_shape=(height,width,1))) model.add(Activation(‘relu’)) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(64, (2,2), padding= ‘same’)) model.add(Activation(‘relu’)) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(128, (2,2), padding=’same’)) model.add(Activation(‘relu’)) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.
 add(Activation(‘relu’))
model.add(Dense(512))
model.add(Activation(‘relu’))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(optimizer=Adam(lr=0.001),
loss=’binary_crossentropy’,
metrics=[‘accuracy’])
return model
add(Activation(‘relu’))
model.add(Dense(512))
model.add(Activation(‘relu’))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(optimizer=Adam(lr=0.001),
loss=’binary_crossentropy’,
metrics=[‘accuracy’])
return modelТеперь у нас есть все, что нужно для обучения нашей маленькой и простой cnn.
def main(): xTrain ,yTrain = readCsv(‘dataset.csv’) #scale the values of the images between 0 and 1 xTrain = xTrain.astype(‘float32’) xTrain /= 255 model = makeModel() #do some data augmentation datagen = ImageDataGenerator( rotation_range=10, width_shift_range=0.2, height_shift_range=0.2, ) datagen.fit(xTrain) #train the model model.fit_generator(datagen.flow(xTrain,yTrain,batch_size=32), steps_per_epoch=len(xTrain) / 32, epochs=50) #save the model model.save(‘blinkModel.hdf5’)
Сначала мы загружаем наши изображения и теги в два массива numpy, затем мы масштабируем значения изображений от 0 до 1, мы делаем это, потому что это ускоряет процесс обучения. После этого мы выполняем некоторое увеличение наших данных, чтобы искусственно увеличить количество обучающих примеров, потому что у нас небольшой набор данных, и мы должны уменьшить переобучение. Наконец, мы обучаем сеть для 50 эпох с размером пакета 32 и сохраняем наш обученный cnn.
После этого мы выполняем некоторое увеличение наших данных, чтобы искусственно увеличить количество обучающих примеров, потому что у нас небольшой набор данных, и мы должны уменьшить переобучение. Наконец, мы обучаем сеть для 50 эпох с размером пакета 32 и сохраняем наш обученный cnn.
Мы знаем, что обычно нам приходилось разделять наши данные на наборы train, val и test, выполнять некоторую тонкую настройку, а затем обучать нашу сеть оценивать их на нашем тестовом наборе, но цель этого руководства — быстро сделать простой детектор миганий и не как обучить классификатор cnn для открытых и закрытых глаз. Поэтому для этого мы не придаем большого значения действительно важным этапам обучения.
Второй этап
Теперь у нас есть обученный cnn, и мы готовы построить наш детектор миганий. Посмотрим, какие библиотеки нам понадобятся.
import cv2 import dlib import numpy as np from keras.models import load_model from scipy.spatial import distance as dist from imutils import face_utils
Библиотека компьютерного зрения, которую мы собираемся использовать, — это OpenCV. Если у вас ее нет, вы можете установить ее, следуя инструкциям, приведенным здесь для Ubuntu 16.04. Также мы будем использовать dlib, а для набора удобных функций, чтобы упростить работу с OpenCV, нам понадобится библиотека imutils. Если в вашей системе не установлен ни один из этих двух компонентов, вы можете легко установить их, используя
Если у вас ее нет, вы можете установить ее, следуя инструкциям, приведенным здесь для Ubuntu 16.04. Также мы будем использовать dlib, а для набора удобных функций, чтобы упростить работу с OpenCV, нам понадобится библиотека imutils. Если в вашей системе не установлен ни один из этих двух компонентов, вы можете легко установить их, используя
pip install — upgrade imutils
а для dlib вы можете следовать этому руководству.
Обзор металлоискателя: сначала мы считываем каждый кадр с камеры, затем обрезаем глаза и передаем их контроллеру, которого мы обучили делать по ним прогнозы. После этого мы берем среднее значение прогнозов, потому что мы ищем мигания, поэтому мы должны быть уверены. В конце концов, мы противодействуем последовательным предсказаниям закрытия, и если они превышают пороговое значение, мы считаем это миганием. Давайте посмотрим код.
Теперь мы определим функцию для распознавания лиц. Мы будем использовать детектор лиц haarcascade, потому что он быстрее, чем фронтальный детектор лица dlib.
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_alt.xml’)
# detect the face rectangle
def detect(img, cascade = face_cascade , minimumFeatureSize=(20, 20)):
if cascade.empty():
raise (Exception(“There was a problem loading your Haar Cascade xml file.”))
rects = cascade.detectMultiScale(img, scaleFactor=1.3, minNeighbors=1, minSize=minimumFeatureSize)
# if it doesn’t return rectangle return array
# with zero lenght
if len(rects) == 0:
return []
# convert last coord from (width,height) to (maxX, maxY)
rects[:, 2:] += rects[:, :2]
return rectsЭта функция принимает единственный обязательный параметр на весь фрейм.
В первой строке мы загружаем классификатор haarcascede из файла xml, который вы можете найти в репо.
Строки 5–7 проверяем, правильно ли загрузился классификатор.
Строки 11–12 мы проверяем, не нашел ли классификатор прямоугольник с лицом, и возвращаем пустой список, если не нашел.
Наконец, в строке 15 мы преобразуем список прямоугольников из [x, y, a, b], где (x, y) — координаты левого угла прямоугольника, а a, b — пиксели, которые мы нужно добавить к x и y соответственно, чтобы сформировать весь прямоугольник, к [x, y, maxX, maxY]. Затем мы возвращаем список прямоугольников, который содержит ноль, один или несколько прямоугольников.
Теперь, когда у нас есть прямоугольник рамки, содержащий лицо, мы можем перейти к поиску глаз. Давайте сделаем для этого функцию.
predictor = dlib.shape_predictor(“shape_predictor_68_face_landmarks.dat”)
def cropEyes(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect the face at grayscale image
te = detect(gray, minimumFeatureSize=(80, 80))
# if the face detector doesn’t detect face
# return None, else if detects more than one faces
# keep the bigger and if it is only one keep one dim
if len(te) == 0:
return None
elif len(te) > 1:
face = te[0]
elif len(te) == 1:
[face] = teТакже эта функция принимает один обязательный параметр — кадр.
В строке 1 мы инициализируем предсказатель лица библиотеки dlib. Вы можете узнать об этом подробнее в этой записи блога.
В строке 4 мы конвертируем наш кадр в оттенки серого. Затем в строках 6–17 мы назначаем значение функции обнаружения лица, а затем проверяем, пусто ли оно, и не возвращаем ничего, если это так, потому что нам не нужно отображение нашего предиктора. прекратить (станет более ясно через несколько минут).
# keep the face region from the whole frame face_rect = dlib.rectangle(left = int(face[0]), top = int(face[1]), right = int(face[2]), bottom = int(face[3])) # determine the facial landmarks for the face region shape = predictor(gray, face_rect) shape = face_utils.shape_to_np(shape) # grab the indexes of the facial landmarks for the left and # right eye, respectively (rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS[“left_eye”] (lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS[“right_eye”] # extract the left and right eye coordinates leftEye = shape[lStart:lEnd] rightEye = shape[rStart:rEnd]
Сначала мы в строке 2 берем область лица из всего кадра, а затем определяем ориентиры лица для области лица, а в строке 5 эти координаты преобразуются в массив NumPy.
В Строках 11–12 мы берем индексы лицевых ориентиров для левого и правого глаза из полного набора лицевых ориентиров dlib.
Затем мы извлекаем координаты левого и правого глаза, используя методы нарезки массива, используя только что полученные индексы.
# keep the upper and the lower limit of the eye # and compute the height l_uppery = min(leftEye[1:3,1]) l_lowy = max(leftEye[4:,1]) l_dify = abs(l_uppery — l_lowy) # compute the width of the eye lw = (leftEye[3][0] — leftEye[0][0]) # we want the image for the cnn to be (26,34) # so we add the half of the difference at x and y # axis from the width at height respectively left-right # and up-down minxl = (leftEye[0][0] — ((34-lw)/2)) maxxl = (leftEye[3][0] + ((34-lw)/2)) minyl = (l_uppery — ((26-l_dify)/2)) maxyl = (l_lowy + ((26-l_dify)/2)) # crop the eye rectangle from the frame left_eye_rect = np.rint([minxl, minyl, maxxl, maxyl]) left_eye_rect = left_eye_rect.astype(int) left_eye_image = gray[(left_eye_rect[1]):left_eye_rect[3], (left_eye_rect[0]):left_eye_rect[2]]
Наша cnn, чтобы иметь возможность предсказывать на изображении, изображение должно быть того же формата, что и изображения, с которыми он обучался. Поэтому нам нужно внести те же изменения в координаты глаз, которые у нас есть.
Поэтому нам нужно внести те же изменения в координаты глаз, которые у нас есть.
Сначала в строках 3–8 мы находим минимальное и максимальное значение y из наших координат и вычисляем высоту левого глаза. Dlib дает 6 пар координат для глаз,
как вы можете видеть, для вычисления высоты глаза нам нужен минимум y из второй и третьей пары и максимум y из пятой и шестой пары. Ширина намного проще, потому что нам просто нужно взять x из первой и четвертой пары и вычислить их разницу.
Это то, что мы делаем в строке 11.
Затем в строках 17–21 для вычисления координат прямоугольника глаза мы добавляем половину разностей формы, которую мы хотим, чтобы наше изображение было, с шириной и высотой глаза, которые у нас есть, к нашему x. и координаты y.
После в строках 24–26 мы обрезаем прямоугольник глаза со всего изображения.
Это было для левого глаза, теперь сделаем то же самое для правого.
# same as left eye at right eye r_uppery = min(rightEye[1:3,1]) r_lowy = max(rightEye[4:,1]) r_dify = abs(r_uppery — r_lowy) rw = (rightEye[3][0] — rightEye[0][0]) minxr = (rightEye[0][0]-((34-rw)/2)) maxxr = (rightEye[3][0] + ((34-rw)/2)) minyr = (r_uppery — ((26-r_dify)/2)) maxyr = (r_lowy + ((26-r_dify)/2)) right_eye_rect = np.rint([minxr, minyr, maxxr, maxyr]) right_eye_rect = right_eye_rect.astype(int) right_eye_image = gray[right_eye_rect[1]:right_eye_rect[3], right_eye_rect[0]:right_eye_rect[2]]
Чтобы закончить нашу функцию
# if it doesn’t detect left or right eye return None if 0 in left_eye_image.shape or 0 in right_eye_image.shape: return None # resize for the conv net left_eye_image = cv2.resize(left_eye_image, (34, 26)) right_eye_image = cv2.resize(right_eye_image, (34, 26)) right_eye_image = cv2.flip(right_eye_image, 1) # return left and right eye return left_eye_image, right_eye_image
мы проверяем, не обнаружили ли мы левый или правый глаз, чтобы не вернуть ни одного, и, если мы обнаружили оба глаза, мы изменяем их размер, чтобы убедиться, что изображения имеют правильный размер, и перед тем, как вернуть изображения глаз, мы переворачиваем правый глаза, поэтому нам нужно налево для правильных прогнозов.
Прежде чем мы перейдем к основной функции нашего скрипта, мы напишем функцию для оставшейся предварительной обработки каждого изображения, которое мы должны сделать для нашей cnn.
# make the image to have the same format as at training def cnnPreprocess(img): img = img.astype(‘float32’) img /= 255 img = np.expand_dims(img, axis=2) img = np.expand_dims(img, axis=0) return img
Здесь мы масштабируем значения изображений между 0 и 1 и добавляем еще два измерения, потому что keras нужно, чтобы изображение имело форму (строки, ширина, высота, каналы), где строка — это количество изображений, ширина и высота изображения и канал количества цветов. Итак, у нас есть одно изображение на каждый раз и 1 канал, и это то, что делают строки 5–6.
Наконец, мы готовы к нашей основной функции.
def main(): # open the camera,load the cnn model camera = cv2.VideoCapture(0) model = load_model(‘blinkModel.hdf5’) # blinks is the number of total blinks ,close_counter # the counter for consecutive close predictions # and mem_counter the counter of the previous loop close_counter = blinks = mem_counter= 0 state = ‘’ while True: ret, frame = camera.
 read()
# detect eyes
eyes = cropEyes(frame)
if eyes is None:
continue
else:
left_eye,right_eye = eyes
# average the predictions of the two eyes
prediction = (model.predict(cnnPreprocess(left_eye)) + model.predict(cnnPreprocess(right_eye)))/2.0
read()
# detect eyes
eyes = cropEyes(frame)
if eyes is None:
continue
else:
left_eye,right_eye = eyes
# average the predictions of the two eyes
prediction = (model.predict(cnnPreprocess(left_eye)) + model.predict(cnnPreprocess(right_eye)))/2.0Сначала мы открываем камеру, загружаем нашу модель cnn и определяем некоторую полезную переменную, которую мы будем использовать и объясним через минуту. Затем начинаем считывать последовательные кадры.
В строках 16–19 мы вызываем нашу функцию для обнаружения и обрезки глаз со всего кадра и проверяем, равно ли их значение «нулю». Если нет, сценарий остановится, чтобы избежать проверки значения и перехода к следующему циклу, если это так. После мы просто усредняем наши прогнозы для глаз.
# blinks # if the eyes are open reset the counter for close eyes if prediction > 0.5 : state = ‘open’ close_counter = 0 else: state = ‘close’ close_counter += 1 # if the eyes are open and previousle were closed # for sufficient number of frames then increcement # the total blinks if state == ‘open’ and mem_counter > 1: blinks += 1 # keep the counter for the next loop mem_counter = close_counter # draw the total number of blinks on the frame along with # the state for the frame cv2.
В Строках 3–8 мы проверяем значение прогноза, если оно больше 0,5, потому что у нас есть двоичный классификатор с сигмовидным нейроном, который дает в качестве выходных данных вероятность открытия глаза, и если он более 50% мы относим к категории открытых. Если он открыт, мы устанавливаем переменную состояния open и close_counter в ноль. если он закрывается, мы добавляем единицу к счетчику, чтобы мы могли знать, для скольких последовательных кадров глаза были закрыты.
В строках 13–14 мы видим, открыты ли глаза и переменная счетчика памяти больше единицы, счетчик памяти имеет значение счетчика закрытия предыдущего цикла. Таким образом, мы можем проверить, открыты ли глаза и были ли они ранее закрыты для получения достаточных рамок. На этом этапе вы можете настроить количество последовательных кадров на вашей камере.
Таким образом, мы можем проверить, открыты ли глаза и были ли они ранее закрыты для получения достаточных рамок. На этом этапе вы можете настроить количество последовательных кадров на вашей камере.
Затем мы рисуем на нашем кадре общее количество миганий и текущее состояние.
Наконец, мы отображаем рамку, и вы можете остановить счетчик, нажав кнопку q.
# do a little clean up cv2.destroyAllWindows() del(camera)
И здесь мы делаем небольшую уборку.
Теперь у вас есть детектор моргания. Построить его было легко и быстро. Это не идеально, но может быть лучше при более подходящем обучении. Вы можете использовать свой собственный набор данных, если хотите, и вы можете изменить все, что захотите.
Металлоискатель Garrett AT MAX — простой и надежный профессиональный детектор
С точки зрения производительности и возможностей AT MAX не уступает другим профессиональным металлодетекторам. По глубине у него максимальные для VLF-металлоискателей возможности. Он имеет отличную способность распознавать металлы и хороший дискриминатор.
Конструкция металлоискателя
построен очень стандартно – он имеет S-образную штангу с блоком управления, катушкой на нижней штанге и довольно широкий подлокотник с мини-ножками под ним. Это самая классическая схема металлоискателя, которая уже зарекомендовала себя на протяжении нескольких десятилетий.
Детектор отлично сбалансирован, несмотря на свой вес 1,4 кг. Да, есть детекторы, которые легче, но 300-400 г не имеют большого значения для металлоискателя, если весь комплект (МД + катушка) не превышает 1,7-1,8 кг. Так что детектор находится в оптимальной весовой категории.
С точки зрения эргономики, это очень хорошо продуманный металлоискатель.
Новая ручка на AT MAX достаточно удобна. Даже если вы копаете без перчаток, она дает хорошее сцепление с ладонью. Сама ручка широкая, и если у вас большая ладонь, то это определенно плюс.
Garrett имеет свой собственный разъем и крепление для катушки. Разъем подходит довольно плотно, но сидит хорошо. Такое плотное соединение вызвано необходимостью поддержания водонепроницаемости.
Батарейный отсек спрятан в блоке металлоискателя, питание от 4-х стандартных батарей AA. Интересная особенность заключается в том, что при падении мощности батареи детектор работает стабильно, ни громкость, ни глубина не уменьшается. Заряда батарей хватает на два световых дня автономной работы.
Монтажные хомуты штанги также были существенно переработаны, они стали прочнее и лучше, их не так легко сломать. У Гаррета бывают проблемы в этом плане, но здесь проблема решена.
В комплекте AT MAX стандартная катушка PROformance DD 11×8.5″. Это отличный универсальный вариант для всех типов поиска.
На другой стороне блока управления у AT MAX имеется разъем для наушников, спрятанный под крышкой. Лучше держать его закрытым, если вы не собираетесь с прибором нырять, так как это дополнительная защита от воды.
Особенности Garrett AT MAX
С точки зрения производительности AT MAX не уступает другим профессиональным металлодетекторам. По глубине у него максимальные для VLF-металлоискателей возможности. Он имеет отличную способность распознавать металлы и хороший дискриминатор.
Вот несколько ключевых факторов, которые отличают этот металлоискатель от других.
Водонепроницаемость
Детектор отлично работает в любую погоду — на морозе, под дождем и в снегу. Так, после погружения в воду динамик на приборе работает по-прежнему отлично. Поэтому одним из способов помыть AT MAX является просто погружение его чистую в воду.
Беспроводные наушники Z-Lynk
Есть комплектация AT MAX с беспроводными наушниками MS-3. Наушники очень удобные и хорошо сидят, они не мешают движению, дают отличное качество звука и обладают быстрой передачей сигнала.
Наушники имеют кнопку включения/выключения и два индикатора — питание от аккумулятора и беспроводное подключение к металлодетектору.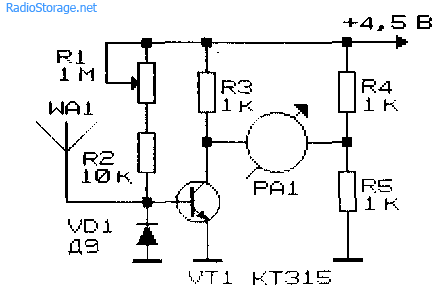 Чтобы использовать их просто нажмите кнопку, оденьте их на голову и идите копать!
Чтобы использовать их просто нажмите кнопку, оденьте их на голову и идите копать!
Можно купить комплект AT MAX без наушников, но лучше не экономить на них. В наушниках все сигналы слышатся намного лучше и производительность обнаружения намного выше, т.е. меньше риск пропустить хорошую и небольшую находку.
Регулятор громкости на наушниках очень удобен — просто вращающаяся рукоятка. Это решение для многих удобнее, чем наличие кнопок регулировки громкости, — вы можете работать в перчатках и не отвлекаться на такие факторы, как регулировка громкости или включение/выключение наушников.
Кроме того, MS-3 от Garrett — одни из лучших наушников для поиска.
Одночастотность
Garrett AT MAX работает на частоте 13,6 кГц, что достаточно для обнаружения как мелких, так и крупных/средних объектов.
Меню и настройки
Глядя на настройки и меню, можно сказать, что является одним из самых простых, если не самым простым профессиональным металлоискателем.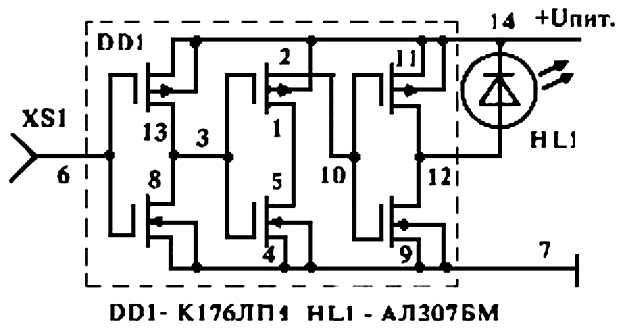 Простота, удобство, надежность и высокие поисковые характеристики — это не пустые слова применительно к AT MAX.
Простота, удобство, надежность и высокие поисковые характеристики — это не пустые слова применительно к AT MAX.
Все необходимые основные настройки находятся сразу под рукой – это баланс грунта, который детектор выполняет очень быстро и точно и пороговый уровень тона. Остальные настройки не столь важны для многих. С настроенной на максимум чувствительностью и громкостью в наушниках вы можете пойти копать.
Какие настройки возможны в AT MAX?
Выборочная дискриминация (Notch). 12 меток дискриминации, может быть активирована любая их комбинация. Причем в процессе поиска вы можете отключать звуковую индикацию ненужных целей по мере их нахождения, просто убирая соответствующую им метку на шкале.
Дискриминация железа (Iron Disc). От 0 (без дискриминации железа) до 44 (максимальная дискриминация железа). Для контроля, сколько железа может быть в виде цели. Очень полезно при маскировании железным объектом соседней цели. Убирая сигналы, например, от гвоздя (регистрируется 18-24 ед. по шкале ID), т.е. выставив Iron Disc на 24, вы не увидите сигнала от гвоздя, но обнаружите рядом лежащую монету, т.к. оба объекта (гвоздь и монета) имеют общую, комбинированную проводимость больше 24 ед.
Убирая сигналы, например, от гвоздя (регистрируется 18-24 ед. по шкале ID), т.е. выставив Iron Disc на 24, вы не увидите сигнала от гвоздя, но обнаружите рядом лежащую монету, т.к. оба объекта (гвоздь и монета) имеют общую, комбинированную проводимость больше 24 ед.
Ручной и автоматический баланс грунта. Необходимая функция в любом профессиональном детекторе.
Регулировка порогового тона. От -9 до +23. Положительные значения добавляют слышимый шум к отклику цели, отрицательные вычитают. Чаще всего, чтобы слышать слабые сигналы, рекомендуют установить небольшое положительное смещение. При нежелательных откликах прибора можно установить нулевой порог или уйти в отрицательные значения. Для восприятия слабых сигналов очень помогут наушники.
Звук железа (Iron Audio). Используется, чтобы слышать сигнал от исключенного из поиска железа. Полезно в режимах дискриминации, когда, например, пробки звучат как хорошие цели. С Iron Audio сигнал от них будет переменным: низкий-высокий-низкий тон.
С Iron Audio сигнал от них будет переменным: низкий-высокий-низкий тон.
Подстройка частоты. Используется для минимизации электромагнитных помех от ЛЭП, других металлоискателей и т.п.
Регулировка громкости. Влияет только на максимальный звук сигнала, а не на уровень звука от слабых сигналов. Т.е. работает как ограничитель.
Чувствительность. 8 уровней. Ставьте ее больше при поиске мелких или глубоких целей. Уменьшайте в сильно замусоренных местах, при больших помехах, когда устойчивость работы не достигается балансом грунта и подстройкой частоты и проч.
Режимы (маски дискриминации). 4 режима.
Все металлы (All Metall). Непрерывный звуковой отклик. Максимальная глубина и чувствительность.
Пользовательский (Custom). Сохраняет ваши настройки и после выключения прибора.
Монеты (Coins). Для поиска большинства видов монет.
Многие копают в нулевом режиме Zero Mode. Zero — обычный режим, но с открытой дискриминацией, Iron Disc установлен на ноль, все 12 сегментов дискриминации включены. В режиме All Metall — детектор реагирует на любое изменение в грунте одним непрерывным пропорциональным средним тоном и обеспечивает максимальную глубину и чувствительность. В режиме Zero работает функция тональной идентификации, и звуковая информация о цели поступает в трехтональном виде.
Можно установить дискриминацию в режиме АМ, тогда получите уже более информативную программу — на цели ниже порога дискриминации будет один тон, а на цели выше порога другой.
Вы можете копать и в других режимах, но это зависит от задачи. Если место чистое, можно включить все металлы – вы получите максимально возможную глубину, но нулевой режим для обычного поиска является наиболее эффективным. Вы можете столкнуться с подозрительными и неустойчивыми сигналами, которые могут принести хорошие результаты – благодаря отличному дискриминатору AT MAX редко ошибается в определении типа металла.
Для мусорных мест придется использовать дискриминацию и даже вырезать некоторые сегменты, чтобы не сойти с ума от непрерывного звучания металлоискателя.
Коротко о звуковой индикации AT MAX
Быстрое восстановление процессора AT MAX помогает хорошо разделять соседние цели. И пропорциональный звуковой отклик означает, что громкость пропорциональна мощности сигнала.
Все металлы. Пользователь постоянно слышит, что видит металлоискатель в земле, с помощью пропорционального среднего тона. При этом могут использоваться функции Iron Disc и Iron Audio, и черные металлы будут давать низкий тон.
Режимы дискриминации. Изменение тонов целей в зависимости от типа металла и проводимости. Низкий тон — ферромагнитные цели, средний — цветные цели с низкой и средней проводимостью (небольшие монеты, фольга, тонкие предметы и т.п.), высокий — цветные цели со средней и высокой проводимостью (большие монеты, ювелирка).
Информация на дисплее AT MAX
Цель.
Цифровой ID объекта, курсор идентификации, примерная глубина залегания (5 сегментов, с шагом 5 см, зависит и от размера цели), легенда идентификации (что может представлять собой обнаруженный объект).
Настройки.
Выбранная маска дискриминации, отображение дискриминации железа, индикатор режима поиска, уровень чувствительности.
Состояние.
Заряд батарей, беспроводное соединение.
Производительность металлоискателя
AT MAX очень чувствителен к любому металлу в земле, независимо от того, большой объект или маленький.
Есть смысл докупить катушку размером 13″/ 15″ и снайперку размером 7″ или 5″ — этот комплект решит все ваши поисковые задачи на многие годы вперед, и вам не нужно будет менять детектор.
Вывод
— профессиональный, легко настраиваемый, удобный, надежный, водонепроницаемый металлоискатель, который эффективно работает на любом грунте.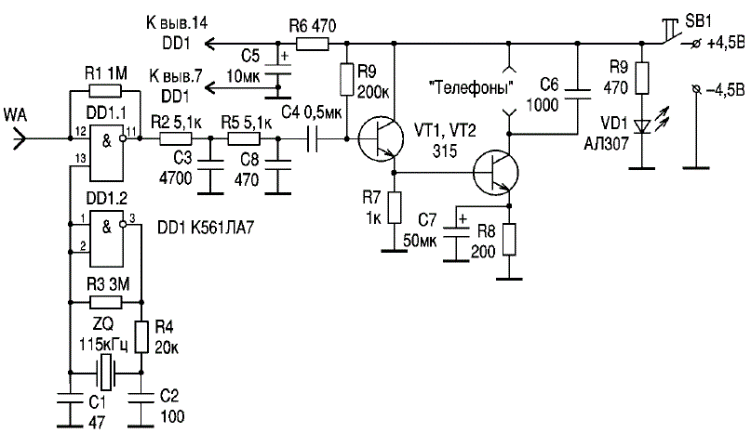 Беспроводные наушники также просты и удобны.
Беспроводные наушники также просты и удобны.
Прибор дает вам возможность выбрать, как вы хотите с ним работать — просто включить и идти на поиск, воспользовавшись отличными стандартными настройками, или самому тонко настроить его под свои конкретные задачи — в любом случае у вас будут находки.
SSID, канал, диапазон, сигнал, и др.
NetSpot — это простой в использовании детектор для Mac.
NetSpot может помочь сделать быстрые снимки сетей Wi-Fi вокруг вас. Кроме того, вы еще можете использовать его для полного исследования всей вашей беспроводной сети.
Перейти к…
Как использовать Детектор Беспроводной Сети
Как использовать NetSpot для полного исследования зоны покрытия WLAN
Диагностика Wi-Fi с приложением NetSpot поможет вам
Детектор Wi-Fi полезен в различных ситуациях, например:
- Когда вы путешествуете и необходимо найти открытую сеть для подключения. Наличие детектора Wi-Fi, загруженного на ваш Макбук или другой ноутбук, позволяет сделать это просто.
- Когда вы хотите протестировать ограничения зоны действия вашей сети Wi-Fi, и определить, где ухудшается сигнал.
- Когда у вас есть проблемы с сигналом и вы хотите выяснить, есть ли еще сети в этом же диапазоне, которые создают помехи вашей.
 Наличие детектора Wi-Fi, загруженного на ваш Макбук или другой ноутбук, позволяет сделать это просто.
Наличие детектора Wi-Fi, загруженного на ваш Макбук или другой ноутбук, позволяет сделать это просто.Как использовать Детектор Беспроводной Сети
Использовать NetSpot в качестве детектора WLAN — легко. Просто установите приложение NetSpot и поместите свой Макбук или другой ноутбук в том месте, которое хотите исследовать. Как только программа загрузится, нажмите на переключатель в верхнем левом углу экрана, чтобы изменить его с «Исследование» на «Обнаружение». NetSpot немедленно обнаружит все сети в диапазоне действия и отобразит их на экране.
Вы сразу сможете увидеть подробую информацию о каждой беспроводной сети, обнаруженной в данном диапазоне, такую как:
- SSID — имя сети
- Канал — по которому транслируется сеть (1, 6, 11, и др. )
- Частота — на которой транслируется сеть (2.4 ГГц, 5 ГГц,
20 МГц, 40 МГц) - Тип безопасности — который имеется у сети (WEP, WPA, WPA2, и др.)
- Режим — какой у сети протокол 802.11 (a, b, g, n, ac или ax)
- Уровень (ОСШ) — уровень отношения сигнал/шум в сети
- Уровень сигнала — насколько сильный сигнал у сети
- Уровень шума — как много шумовых помех в сети
 )
)Как использовать NetSpot для полного исследования зоны покрытия WLAN
Если вы желаете получить более полную картину своей беспроводной сети, вы можете использовать NetSpot для полного исследования зоны ее покрытия. Это позволит вам выполнить обнаружение WLAN в разных точках по всей зоне покрытия вашей сети.
Если вы ранее не пользовались NetSpot, прочтите перед этим «Как начать исследование?». Далее определите диапазон, в котором вы хотите обнаружить Wi-Fi и загрузите карту территории. Вы также можете нарисовать карту, используя инструменты NetSpot для построения карт.
Затем продолжайте исследование, получая данные по всей зоне покрытия. Как только вы завершите свое исследование, вы сможете увидеть визуализацию тепловой карты.
Визуализации NetSpot позволяют вам увидеть мощность вашего сигнала, отношения сигнал/шум и сигнал/помеха, охватывая весь диапазон, который вы исследовали. Также есть визуализация Количества точек доступа, которая покажет вам, сколько Точек доступа (или роутеров) обнаружено в каждой области измерения. NetSpot заботится обо всех ваших потребностях в обнаружении беспроводной сети.
Диагностика Wi-Fi с приложением NetSpot поможет вам
Бесплатно обнаружить
помехи WiFiБесплатно обнаружить WiFi
Обнаружить точки доступа WiFi
Обнаружить все беспроводные сети
Обнаружить беспроводную сеть
Обнаружить сети WiFi для Mac
- 4. 8
- 969 Ratings
 8
8- #1
- Обзоры сайтов Wi-Fi, анализ, устранение неисправностей
- 500K
- Пользователи по всему миру
- 8
- годы на рынке
- Cross-platform
- Mac/Windows
- Скачать NetSpot
- Узнайте больше о NetSpot
FAQ
Как использовать детектор беспроводной сети?
NetSpot — отличный детектор WLAN — установите приложение и перенесите свой ноутбук в область, которую вы хотите исследовать. Откройте NetSpot, нажмите переключатель в верхнем левом углу, чтобы перейти в режим «Обнаружение». NetSpot обнаружит все сети в радиусе действия и отобразит их.
Какую конкретно информацию о каждой беспроводной сети можно обнаружить в данном диапазоне?
Вы сможете увидеть следующую информацию:
- SSID — имя сети
- Канал — по которому транслируется сеть (1, 6, 11, и др. )
- Частота — на которой транслируется сеть (2.4 ГГц, 5 ГГц,
20 МГц, 40 МГц) - Тип безопасности — который имеется у сети (WEP, WPA, WPA2, и др.)
- Режим — какой у сети протокол 802.11 (a/b/g/n/ac/ax)
- Уровень (ОСШ) — уровень отношения сигнал/шум в сети
- Уровень сигнала — насколько сильный сигнал у сети
- Уровень шума — как много шумовых помех в сети
 )
)Как использовать NetSpot для обследования сайтов WLAN?
Чтобы исследовать зону покрытия WiFi, загрузите карту территории и начните проводить измерения повсюду. Как только опрос будет завершен, вы сможете увидеть визуализацию тепловой карты.
Визуализации NetSpot позволяют вам увидеть мощность вашего сигнала, отношения сигнал/шум и сигнал/помеха, охватывая весь диапазон, который вы исследовали. Также есть визуализация Количества точек доступа, которая покажет вам, сколько Точек доступа (или роутеров) обнаружено в каждой области измерения.
Есть еще вопросы?
Оставьте заявку
или напиши пару слов.
Читайте дальше Все о Wi-Fi
Если вы хотите получить больше информации о Wi-Fi, ознакомьтесь со следующими статьями о маршрутизаторах Wi-Fi, лучших приложениях для беспроводных сетей, сигналах Wi-Fi и т. Д.
Скачайте NetSpot бесплатно
Wi-Fi Обзоры сайтов, Анализ, Устранение неполадок работает на MacBook (macOS 10.10+) или любом ноутбуке (Windows 7/8/10/11) со стандартным адаптером беспроводной сети 802.11a/b/g/n/ac/ax.
Скачать NetSpot
- 4.8
- 969 Отзывы Пользователей
Оставить отзыв
Простой детектор электрического поля – схема для поиска обрыва провода на 220V в кабеле, шнуре питания « ЭлектроХобби
Все те устройства, что питаются от электрической сети имеют шнур питания, который соединяет нашу электротехнику с розеткой. Такие шнуры внутри себя содержать многожильные медные провода, что и позволяет этим шнурам перегибаться большое количество раз, оставаясь невредимыми. Но у любого электрического шнура, кабеля имеются наиболее слабые места, а именно там, где проводу приходится больше всего перегибаться. Со временем, какие бы хорошие провода у шнура, кабеля не были, все равно рано или поздно происходит обрыв медного проводника внутри этого кабеля.
Такие шнуры внутри себя содержать многожильные медные провода, что и позволяет этим шнурам перегибаться большое количество раз, оставаясь невредимыми. Но у любого электрического шнура, кабеля имеются наиболее слабые места, а именно там, где проводу приходится больше всего перегибаться. Со временем, какие бы хорошие провода у шнура, кабеля не были, все равно рано или поздно происходит обрыв медного проводника внутри этого кабеля.
Либо же повреждение может произойти из-за перегорания наиболее слабых мест самого провода (были переломлены несколько жил и рабочем состоянии остались только несколько токопроводящих жил), и при этом место такого обрыва может быть не видно невооруженному глазу. Либо же случаи, когда просто нужно определить местоположение электрического кабеля внутри стены, что его извлечь или просто не повредить во время сверлильных работ. И во всех этих случаях будет полезна простая схема детектора обрыва электрического кабеля, состоящая всего из нескольких деталей.
Принцип действия этой схемы, которая может обнаружить скрытую проводку в стене или обрыв медных жил в кабеле, достаточно прост. Это устройство улавливает электрические поля, которые существуют вокруг фазовых проводов. То есть, при наличии фазы на проводе вокруг этого проводника на некотором расстоянии имеется переменное электрическое поле. Если в это переменное поле ввести другой проводник тока (в нашем случае небольшую антенну из медного провода), то на его концах образуется небольшая разность потенциалов (электрическое напряжение). Поскольку это наведенное напряжение имеет очень маленькую величину, то возникает необходимость в усилении сигнала.
Это устройство улавливает электрические поля, которые существуют вокруг фазовых проводов. То есть, при наличии фазы на проводе вокруг этого проводника на некотором расстоянии имеется переменное электрическое поле. Если в это переменное поле ввести другой проводник тока (в нашем случае небольшую антенну из медного провода), то на его концах образуется небольшая разность потенциалов (электрическое напряжение). Поскольку это наведенное напряжение имеет очень маленькую величину, то возникает необходимость в усилении сигнала.
В итоге, схема детектора электрического поля, обнаруживает вокруг фазового провода это самое поле, после чего с антенны слабое переменное напряжение подается на вход, двух последовательно соединенных, простых транзисторных усилителей. Как известно транзисторы могут усиливать электрический ток. Причем это усиление даже у одного транзистора может быть десятки и сотни раз. А если эти транзисторы подсоединены друг за другом, то усиление становится еще больше и уже может достигать тысячи раз. Именно это усилительное свойство и применяется в данной схеме.
Именно это усилительное свойство и применяется в данной схеме.
Как видно схема детектора электрического поля (скрытой проводки) состоит из антенны, двух усилительных транзисторных (биполярных) каскадов индикаторного светодиода и источника питания на 3 вольта, ну и еще кнопки включения схемы. Чувствительность схемы достаточно хорошая, и она еще также зависит от размеров антенны. Если в роли антенны использовать небольшую спираль, сделанную из небольшого куска медной проволоки (намотанную допустим на ампулу обычной авторучки, содержащую 30 витков, и диаметр провода около 0,5 мм), как показано на рисунке схемы, то устройство может обнаруживать электрическое поле на расстоянии до 3-5 см. Для поиска обрыва медного провода внутри кабеля или шнура питания этого расстояния более чем достаточно, поскольку слишком чувствительный прибор также ухудшит точность нахождения места обрыва.
Биполярные транзисторы в схему лучше ставить любые маломощные, n-p-n проводимости с высоким коэффициентом усиления. На схеме я указал транзисторы типа C945 (зарубежные), или КТ3102, КТ315 (отечественные), или любые подобные. Если у вас имеются схожие транзисторы, но p-n-p проводимости, то в схему можно поставить и их, но при этом уже нужно изменить полярность подключения источника питания и светодиода на противоположную. Можно в схему поставить и один транзистор, но он должен быть составным (так называемые транзисторы Дарлингтона), которые имеют весьма большой коэффициент усиления. По сути в одно таком составном транзисторе располагаются два, также как и в нашей схеме.
На схеме я указал транзисторы типа C945 (зарубежные), или КТ3102, КТ315 (отечественные), или любые подобные. Если у вас имеются схожие транзисторы, но p-n-p проводимости, то в схему можно поставить и их, но при этом уже нужно изменить полярность подключения источника питания и светодиода на противоположную. Можно в схему поставить и один транзистор, но он должен быть составным (так называемые транзисторы Дарлингтона), которые имеют весьма большой коэффициент усиления. По сути в одно таком составном транзисторе располагаются два, также как и в нашей схеме.
Светодиод в этой схеме детектора обрыва сетевого провода выполняет роль индикатора этого самого электрического поля. То есть, как только мы антенну поднесли к фазному проводу, схема обнаружила электрическое поле, биполярные транзисторы открылись и светодиод зажегся. Параллельно светодиоду можно еще припаять обычную звуковую пищалку. В этом случае при обнаружении электрического поля устройство будет сигнализировать об этом и визуально, светодиодом, и звуком, через пищалку. Так что делайте, как вам будет удобней и лучше. Светодиод в схему можно поставить практически любой, лишь бы горел видимым светом.
Так что делайте, как вам будет удобней и лучше. Светодиод в схему можно поставить практически любой, лишь бы горел видимым светом.
Ну, и пару слов о том, как именно осуществлять поиск обрыва медного провода внутри электрического кабеля, шнура питания. Итак, мы имеем нерабочий кабель, на пример от сетевого удлинителя. Мы вилку удлинителя включаем в розетку. Как известно в розетке один контакт это фаза, а второй это ноль, ну и еще земля, если она есть. То есть, на удлинителе, по всей его длине (в случае его исправности) на одном проводе должна появится фаза. Вокруг этой фазы будет электрическое поле.
Когда мы антенной нашего детектора медленно будем проводить по всей длине кабеля удлинителя, то светодиод индикатора будет гореть, пока он видит наличие фазы в проводе. В месте обрыва, естественно, фаза прервется. И как только мы дойдем до места обрыва, после него светодиод просто погаснет. Если светодиод горит по всей длине кабеля, то значит один из двух проводов кабеля цел. Значит нужно вилку включить в розетку наоборот, то есть чтобы фаза появилась на другом проводе кабеля. После чего повторяем поиск обрыва. Если кабель действительно поврежден, то в любом случае вы это место обнаружите данной схемой детектора электрического поля.
Значит нужно вилку включить в розетку наоборот, то есть чтобы фаза появилась на другом проводе кабеля. После чего повторяем поиск обрыва. Если кабель действительно поврежден, то в любом случае вы это место обнаружите данной схемой детектора электрического поля.
Видео по этой теме:
P.S. Данная схема детектора поля позволяет легко обнаружить как обрыв провода в кабеле, шнуре питания, так и найти провод электрической проводки внутри стены. И даже при своей простоте и минимум деталей схема работает вполне нормально и хорошо. Изменяя длину антенны, можно также изменять чувствительность устройства. Хотя можно добавить еще одни транзистор и в этом случае чувствительность детектора увеличивается еще больше. Так что пробуйте, собирайте и используйте по своему назначению.
Детектор лжи – простой способ узнать правду | 59.ru
Пропала цепочка со стола коллеги, деньги из кассы или конкуренты узнали секрет фирмы? Вор в коллективе – явление неприятное, но, к сожалению, нередкое. Есть способ не только выяснить, кто виноват, но и не допускать таких ситуаций впредь. Лишь недавно «детектор лжи» перестал быть прерогативой спецслужб. В Перми проверкой сотрудников на полиграфе занимается «Ассоциация исследователей лжи».
Есть способ не только выяснить, кто виноват, но и не допускать таких ситуаций впредь. Лишь недавно «детектор лжи» перестал быть прерогативой спецслужб. В Перми проверкой сотрудников на полиграфе занимается «Ассоциация исследователей лжи».
Полиграф эффективен только в том случае, если с ним работает профессионал. Иначе это просто компьютер с проводками и датчиками. Отличить нервного, но честного сотрудника от уравновешенного мошенника под силу лишь хорошему психологу. О специфике работы с «детектором лжи» рассказал полиграфолог «Ассоциации исследователей лжи» Владимир Чебатков. Отвечал правду и только правду.
– Владимир, интересно, есть ли шансы обмануть полиграф?
– Вы можете контролировать ширину сосудов, гальваническую реакцию, дыхание верхнее и нижнее, тремор, который в любом случае будет. Говорят, что можно принять успокоительное. Да, принимайте, я это увижу. Первое, чему учат полиграфолога, – это методам противодействия.
– Все привыкли считать «детектор лжи» шпионской штучкой.
– Да, раньше так и было. Но недавно государство дало разрешение на использование полиграфа не только сотрудниками полиции. Кстати, при переаттестации каждый полицейский обязан был пройти исследование на «детекторе». Сейчас эта практика распространяется на многие сферы. На Западе такая проверка уже давно стала нормой. У нас все только начинается.
Сейчас в кризис главная проблема предпринимателей – сохранить деньги. Существуют аудиторы, фирмы по безопасности бизнеса, но они проверяют только бумаги, не людей. А это большое упущение. «Ассоциация исследователей лжи» как раз и восполняет этот пробел. Если человек работает больше года и если в компании работа построена таким образом, что легко можно что-либо унести, кто-то этим обязательно воспользуется. Ну а если сотрудники видят, что их периодически проверяют, то воровства в компании не будет!
Представьте обыкновенный магазинчик. Мы тестируем людей и выясняем, что за три месяца было украдено более 100 тысяч. А сколько хозяева потеряли до этого? Просто из-за того, что у них недобросовестные продавцы. Поэтому проще заплатить 3-4 тысячи и избавиться от этих вопросов. Многие говорят: «Ну уволю я этих, придут другие и тоже будут воровать». Я отвечаю – не будут. Если сразу же протестировать и сказать, что это будет повторяться раз в полгода, то не будут.
Поэтому проще заплатить 3-4 тысячи и избавиться от этих вопросов. Многие говорят: «Ну уволю я этих, придут другие и тоже будут воровать». Я отвечаю – не будут. Если сразу же протестировать и сказать, что это будет повторяться раз в полгода, то не будут.
Возможны проверки по следующим фактам:
- воровство;
- финансовые махинации;
- шпионаж в пользу третьих лиц, сговор с конкурентами;
- взяточничество, коррупция, откаты;
- служебный проступок;
- нарушение коммерческой и банковской тайны;
- материальный и моральный ущерб компании;
- использование служебного положения;
- негласное использование ресурсов предприятия.
Также возможно определить:
- особенности отношений в коллективе;
- благонадежность, лояльность сотрудников;
- верность выбора кандидатуры на руководящую должность;
- порядочность сотрудника при увольнении.
– Некоторые крупные компании уже имеют в штате своего полиграфолога.
– Это ошибка и очень серьезная. Полиграфолог должен быть независимым лицом и когда говорят: «У нас есть свой специалист» – они не понимают, что сейчас он в стороне, а через полгода все знают, где его кабинет и ходят к нему пить чай. Он перестает быть полиграфологом, а становится просто человеком за компьютером. И рано или поздно это начинает бить по карману собственнику компании.
– Сколько времени занимает тестирование?
– В среднем человека можно протестировать за час. Сначала я просто беседую, исследую по «профайлингу», хотя я предпочитаю термин «верификация». Пол Экман все-таки ввел именно это понятие. А только потом я уже включаю аппарат. Бывают ситуации, когда у человека плохое самочувствие, он не выспался, его накрутили или он сам по себе тревожно-мнительный. В таких случаях требуется дополнительное время. После 45 минут делаю перерыв. Как-то в случае с супружеской неверности я проводил тест три часа.
Пол Экман – американский психолог, специалист по распознаванию лжи по мимике и жестам. Прототип доктора Лайтмана в сериале «Обмани меня» (другой вариант – «Теория лжи»).
Прототип доктора Лайтмана в сериале «Обмани меня» (другой вариант – «Теория лжи»).
Часто я пытаюсь дознаться до каких-нибудь секретов. А это очень-очень важно. Полиграфологу надо рассказывать все, как священнику. И вот почему. Например, я спрашиваю: «Принимали наркотики?» А потом интересуюсь пропажей денег, из-за которой меня и вызвали. Человек денег не брал, но когда-то принимал наркотики. И сейчас у него фоном идет реакция на первый вопрос. Да, может быть руководство узнает о наркотиках, но это лучше необоснованных подозрений.
Бывают действительно сложные тестирования. Например, в женских коллективах, где все всё знают. Дамы уже несколько раз обсудили ситуацию, примерили ее на себя. А при таком «вживании в роль» может появиться минимальная реакция. В таком случае приходится делать повторное тестирование.
– Вы говорите, что полиграфологу надо практически исповедоваться. А как же тайна исповеди, конфиденциальность?
– Я приведу пример. Директор предприятия заказал тест. Курьер утверждал, что деньги передал, бухгалтер не получала. Вопрос серьезный. Я вижу, что бухгалтер волнуется, но чувствую, что не из-за этих денег. Бывают такие ситуации, что приходится задавать очень личные вопросы. Я спрашиваю: «С руководством спала»? У нее реакция высокая. «Деньги брала», – низкая. То есть вот от чего волнение было.
Курьер утверждал, что деньги передал, бухгалтер не получала. Вопрос серьезный. Я вижу, что бухгалтер волнуется, но чувствую, что не из-за этих денег. Бывают такие ситуации, что приходится задавать очень личные вопросы. Я спрашиваю: «С руководством спала»? У нее реакция высокая. «Деньги брала», – низкая. То есть вот от чего волнение было.
Полиграфолог – это не юрист. О каких-то вещах будет сказано обязательно. Заказчик получил информацию, за которую он заплатил. Все остальное неважно.
– С тестируемыми вы общаетесь как добрый друг или плохой полицейский?
– «Полицейский» бывает редко. Я скорее «друг». Ко мне они пришли не по своей воле. И если они честны, то почему я должен быть «плохим полицейским». Наоборот, я должен снять тревожность, чтобы она не мешала тесту. Правда бывают ситуации, когда человек явно агрессивен. Он не виноват, но агрессивен, и это мешает работе. Тогда приходится разговаривать и резко. Но в большинстве случаев – я друг.
– Мы подошли к очень серьезной теме – этика полиграфолога.
– Полиграфолог дает информацию только тому, кто его заказывает. И никому другому. Я придерживаюсь старой школы и тесты предоставляю только в печатном виде. Мы не даем аудио- и видеоматериалы. Представьте, а если это попадет в Сеть? Только резюме и только в печатном виде, чтобы избежать подделок.
– У вас не возникла профдеформация, что «все люди врут»? Вы не перестали верить людям?
– Представьте человека, который всегда говорит правду. Радикальная честность – это тоже не норма. Мы все где-то говорим неправду. Учим детей одному, а сами живем по-другому. Такое бывает. Но в глобальном смысле я считаю, что люди все же честны. Если не говорить о патологических врунах и воришках.
«Ассоциация исследователей лжи»адрес: г. Пермь, ул. Рязанская, 80, оф. 408;телефон: (342) 259-78-60;Сайт.Мульти газовый зажим простой | Gas Clip Technologies
Напоминание: опубликуйте свою фотографию с детектором Gas Clip на нашей странице в LinkedIn, чтобы получить шанс выиграть приз! Каждые две недели определяется новый победитель.
Деталь № MGC-S
Продается через дистрибьюторов по всему миру.
4 ГАЗОВЫЙ ДЕТЕКТОР со СРОКОМ РАБОТЫ 2 ГОДА
Простое обнаружение газа
Никакой зарядки! Калибровка не требуется! (При необходимости можно откалибровать)
Надежный тест на сероводород (H 2 S), окись углерода (СО), кислород (O 2 ) и горючих газов (НПВ) с помощью этого простого в использовании и обслуживании детектора. Просто включите его и получите гарантию защиты от токсичных газов 24 часа в сутки 7 дней в неделю в течение двух полных лет.
Ключевым фактором является низкое энергопотребление!
Компания Gas Clip Technologies продолжает совершенствовать передовые маломощные
фотометрическая инфракрасная технология для измерения горючих газов помогает упростить обнаружение газа и
безопаснее, чем когда-либо. Новейший член их семейства газовых детекторов, Multi Gas Clip Simple, никогда не требует подзарядки и
нет необходимости в калибровке. Это ПРОСТО в использовании!
Новейший член их семейства газовых детекторов, Multi Gas Clip Simple, никогда не требует подзарядки и
нет необходимости в калибровке. Это ПРОСТО в использовании!
Особенности
- 2 года работы — 2 года жизни!
- 2 года гарантии. Для любой услуги, пожалуйста, позвоните в наш сервисный центр.
- Никогда не заряжать! Калибровка не требуется!
- Большой, легко читаемый экран
- Простое управление одной кнопкой
- Работает в средах с повышенным содержанием кислорода и с недостатком кислорода
- Непрерывная регистрация данных в течение 1 секунды
- Датчик НПВ невосприимчив к H 2 S и силиконовому яду
- Собрано в США
- Совместим с простой док-станцией MGC или простой настенной док-станцией MGC
Техническая спецификация
Простое техническое описание MGC v2. 07
07Руководство
Простое руководство MGC v1.06Краткое руководство пользователя
Простое краткое руководство MGC v1.03Программного обеспечения
Простая прошивка MGC v1.1.32 (24-01-2022)Программное обеспечение GCT IR Link v2.0.67* (27-07-2022)
*Системные требования: Доступно для ПК на базе Windows©
(64-разрядные версии Vista, 7, 8.x, 10).
Пользователи также должны установить программное обеспечение Microsoft Net 4.0.
(для загрузки используйте Chrome, Firefox, Opera или Edge)
Видео
Простой видеоролик о продукте MGCАксессуары
Детектор(ы) продаются отдельно.
Артикул №: GCT-XP
Внешний насос позволяет любому диффузионному детектору Gas Clip брать удаленные образцы на расстоянии до 75 футов, всасывая воздух со скоростью более одного фута в секунду, и поставляется с двухлетней гарантией. .
*Системные требования: Доступно для ПК на базе Windows© (Vista, 7, 8.x, 10, 64-разрядные версии)
Детекторы продаются отдельно.
Деталь №: GCT-IR-LINK
Коммуникационный модуль GCT IR LINK с кабелем USB (для использования со всеми извещателями GCT
На фото подключен к извещателю MGC-SIMPLE.
Деталь №: USB-кабель GCT IR Link
USB-кабель GCT IR Link
Детектор(ы) продаются отдельно.
Деталь №: MGC-S-DOCK
Испытательная док-станция в переносном кейсе с газовым отсеком, регулятором, манометром, зарядным устройством и USB-накопителем (используется с MGC Simple и Simple Plus)
Детектор(ы) продаются отдельно.
Деталь №: MGC-S-WMDOCK
Испытательная док-станция в металлическом корпусе с газовым отсеком, регулятором, манометром, зарядным устройством и USB-накопителем (используется с MGC Simple и Simple Plus)
Детектор(ы) продаются отдельно.
Деталь №: DOCK-CHARGER
Сменное зарядное устройство для док-станции — стандарт. Блок питания 110 В (для всех док-станций GCT Clip)
Детектор(ы) продаются отдельно.
Деталь №: MGC-S-HAK
Комплект ручного аспиратора для MGC Simple и MGC Simple Plus — зонд, каменный фильтр, шланг для отбора проб, груша и калибровочный колпачок (используется с MGC Simple и Simple Plus).
Детектор(ы) продаются отдельно.
Газ продается отдельно.
Вы можете использовать любой баллон с калибровочным газом, если он имеет C-10 разъем.
Деталь №: GCT-CSK
Жесткий футляр для переноски с вкладышем из пеноматериала,
1′ пробоотборный зонд,
фильтр воздуха каменный частичный,
10-футовый шланг для отбора проб,
ручной насос аспиратора,
3-футовый калибровочный/тестовый шланг с быстроразъемным соединением,
калибровочные колпачки (Multi Gas Clip и MGC Simple/Simple Plus),
Регулятор 0,5 л/мин и GCT IR LINK.
Детектор(ы) продаются отдельно.
Вы можете использовать любой баллон с калибровочным газом, если он имеет C-10 разъем.
Деталь №: GCT-CSK-GAS
Твердый футляр для переноски с пенопластовой вставкой, Счетверенный газовый баллон объемом 58 л (25 частей на миллион H3S, 100 частей на миллион CO, 18% O2 и 50% НПВ), 1-дюймовый пробоотборный зонд, фильтр твердых частиц воздушного камня, 10-футовый шланг для отбора проб, ручной аспирационный насос, 3-футовый калибровочный/тестовый шланг с быстроразъемным соединением, калибровочные колпачки (Multi Gas Clip и MGC Simple/Simple Plus), Регулятор 0,5 л/мин и GCT IR LINK.
Детектор(ы) продаются отдельно.
Деталь №: PROBE-1
Выносной пробоотборный зонд — 1 фут
Детектор(ы) продаются отдельно.
Деталь №: REG-MANUAL
Ручной регулятор (использование вне док-станции) для использования со всеми детекторами GCT, кроме насосов MGC
Детектор(ы) продаются отдельно.
Деталь №: MGC-S-X-FILTER-KIT
Крышка внешнего пылевого фильтра плюс 5 фильтров (только для использования с MGC Simple * Simple Plus)
Запчасти и запасные части
Деталь №: MGC-S-CALCAP
Сменный калибровочный колпачок (для использования с MGC-S и MGC-S-PLUS)
Деталь №: AL-CLIP
Сменный зажим типа «крокодил» (включая винт) (для использования со всеми детекторами GCT)
Деталь №: HOSE-3
Калибровочный шланг — 3 фута. Tygon ID-1/8″ (3,18 мм), OD-1/4″ (6,35 мм), стенка-1/16″ (1,59 мм)
Вы можете использовать любой баллон с калибровочным газом, если он имеет C-10 разъем.
Часть №: MGC-Q-58 / MGC-Q-116
Содержит 25 частей на миллион H 2 S,
100 частей на миллион CO,
18% O 2 ,
и 50% НПВ (2,5% по объему метана)
ДОСТУПНЫ в 58 л или 116 л
Детектор(ы) продаются отдельно.
Деталь №: PROBE-RF
Сменный набор фильтров и прокладок удаленного пробоотборного зонда
Детектор(ы) продаются отдельно.
Артикул №: MGC-WT
Выносной пробоотборный зонд Встроенный водоотделитель Замена фильтра
Деталь №: MGC-SE-4DT
Замена MGC h3S и CO (Dual-Tox) для всех насосов MGC и MGC
Простой детектор Gas Clip Technologies MGC, 4 газа (h3S, O2, CO и НПВ), срок службы 2 года
Простой детектор Gas Clip Technologies MGC, 4 газа (h3S, O2, CO и НПВ), срок службы 2 года
- Артикул:
- ГАМГКС
- Производитель:
- Технологии газового зажима
- Тип:
- 4 Газ (h3S, O2, CO и НПВ)
- Описание:
- 2 года работы
- Вес:
- 1,00 фунта
1036,10 долларов США
- Артикул:
- ГАМГКС
- Производитель:
- Тип:
- 4 Газ (h3S, O2, CO и НПВ)
- Описание:
- 2 года работы
- Вес:
- 1,00 фунта
 org/Brand»>
Технологии газового зажима
org/Brand»>
Технологии газового зажима1036,10 долларов США
Gas Clip Technologies Непрерывная разработка и совершенствование передовой маломощной фотометрической инфракрасной технологии для измерения НПВ помогает сделать обнаружение газа проще и безопаснее, чем когда-либо. Никакой зарядки и калибровки не требуется. Включите детектор и будьте уверены в обнаружении токсичных и горючих газов в режиме 24/7 в течение многих лет без многократной зарядки или калибровки. Без замены датчиков и батареек. Чрезвычайно низкие эксплуатационные расходы. С помощью этого простого в использовании и простого в обслуживании детектора можно надежно проверять наличие сероводорода (h3S), монооксида углерода (CO), кислорода (O2) и горючих газов (НПВ). Просто включите его, и вы получите надежную защиту от токсичных газов 24/7 в течение двух полных лет.
Без замены датчиков и батареек. Чрезвычайно низкие эксплуатационные расходы. С помощью этого простого в использовании и простого в обслуживании детектора можно надежно проверять наличие сероводорода (h3S), монооксида углерода (CO), кислорода (O2) и горючих газов (НПВ). Просто включите его, и вы получите надежную защиту от токсичных газов 24/7 в течение двух полных лет.
Особенности
- Срок службы 2 года
- Работает в средах с дефицитом и обогащением кислорода
- Датчик НПВ невосприимчив к ядам датчика, таким как h3S и силикон
- Простое управление одной кнопкой
- Большой, легко читаемый экран
- 1 Совместимость с простой док-станцией MGC Simple Dock или простой настенной док-станцией MGC
- Полная регистрация данных с интервалом в одну секунду
- Невозможность защиты
- Легкий и прочный, включает в себя зажим типа «крокодил», который надежно фиксируется
- Зарядка или калибровка не требуются
- Гарантия 2 года
Технические характеристики
- ЖК-дисплей с большим углом обзора
- 4 красных светодиодных индикатора
- Желтая подсветка активируется при нажатии кнопки
- Красная подсветка активируется при нажатии кнопки состояние
- Желтый светодиодный индикатор технического обслуживания
- Визуальная, вибрационная и звуковая (минимум 95 дБ) сигнализация
- Низкая, высокая, стальная, TWA и OL (превышение предела) сигнализации
- Полнофункциональная самопроверка при активации
- Непрерывная проверка датчиков, батареи и схемы
- Срок службы батареи 730 дней при непрерывном использовании, исходя из 1,5 мин. аварийных сигналов в день
- Диапазон температур от -4° F до 122° F
- Относительная влажность от 5% до 95% без конденсации влаги
- Соответствует сертификации CAN/CSA C22.2 152 CSA 16.70084100 & ANSI/UL-913 & ANSI/ ISA-S12.13
 аварийных сигналов в день
аварийных сигналов в деньИспытанные газы
- Сероводород (h3S)
- Окись углерода (CO)
- Кислород (O2)
- Горючие газы (НПВ)
Видео Скрыть видео Показать видео
Gas Clip Technologies Введение продукта
Gas Clip Technologies была основана для обеспечения непревзойденного качества,…
Gas Clip Technologies Multi Gas Clip Введение
Срок службы батареи не часы, а месяцы! День за днем, йоу.
..Начало работы с MGC
 ..
..Простые РЧ-детекторы
Простые РЧ-детекторы
3. Пассивный РЧ-зонд с удвоением напряжения
Полезный и простой детекторный зонд можно собрать из нескольких недорогих компонентов и выброшенного шарикового пластикового футляра для ручек. Диоды могут быть германиевыми (OA47, OA90 и т. д.) или диодами Шоттли (HP2800, HP2835, BA482, 1N5711 и т. д.). Для достижения наилучших результатов секция детектора должна быть экранирована.
Любой счетчик должен быть на 50 или 100 мкА полной шкалы, если только не будет использоваться какая-либо форма усилителя постоянного тока, и в этом случае он может быть 1 мА полной шкалы. А 741 оп- Если будет использоваться усилитель постоянного тока, то для пробника необходимо предусмотреть возврат постоянного тока —
Если будет использоваться усилитель постоянного тока, то для пробника необходимо предусмотреть возврат постоянного тока —
Компоненты детектора можно соединить вместе, используя небольшой кусок печатной платы или плату Vero для механической поддержки, или просто установить на металлический заземляющий экран перед установкой в изолированную рукоятку. Для подключения к извещателю подойдет любой небольшой экранированный или коаксиальный кабель длиной около 1 м.
Когда зонд готов и протестирован, необходимо использовать небольшой саморез или небольшое количество клея, чтобы зафиксировать электронику в изолированной рукоятке.
4. Активный радиочастотный датчик
Этот датчик немного сложнее предыдущих и требует наличия операционного усилителя для управления расходомером. Тем не менее, лучшая температурная компенсация и чувствительность могут быть получены в широком диапазоне частот при условии, что используются методы построения УКВ — короткие провода  д. Низкочастотная характеристика будет определяться конденсатором 1n между входом и первым диодом. . Для использования на более низкой частоте увеличьте значение конденсатора.
д. Низкочастотная характеристика будет определяться конденсатором 1n между входом и первым диодом. . Для использования на более низкой частоте увеличьте значение конденсатора.
Детекторные диоды должны быть ОВЧ-диодами типа Шоттки, такими как HP2800, BA482 или аналогичными. Потенциометр 500K используется для установки нуля счетчика и должен быть доступен при использовании. Операционный усилитель общего назначения, такой как CA3140, будет удовлетворительным и может работать от источника питания всего +/-
Чтобы обеспечить согласующее сопротивление 50 Ом, нагрузка 50 Ом может быть построена из двух резисторов для поверхностного монтажа по 100 Ом параллельно или одного резистора 51 Ом, как предпочтительнее. Этому может предшествовать аттенюатор для измерения сигналов более высокого уровня.
Диоды могут быть маломощными германиевыми или кремниевыми, хотя предпочтительны диоды Шоттли.
Соберите компоненты на небольшой части печатной платы. Используйте проволочные щупы или коаксиальный разъем BNC на ВЧ-входе с очень короткими проводами к печатной плате. Вся сборка может быть размещена в небольшой литой коробке или в легком ручном датчике
Максимальный вход ВЧ будет определяться напряжением пробоя диодов детектора. Готовая сборка должна обнаруживать сигналы до нескольких милливольт, если коэффициент усиления операционного усилителя
Если этот пробник будет использоваться в качестве милливаттметра, потребуется небольшой входной аттенюатор, чтобы обеспечить постоянный импеданс 50 Ом при различных уровнях сигнала.
Следующий усилитель постоянного тока был собран и протестирован с детектором с двумя диодами, результаты показаны в таблице ниже. Хотя номиналы резисторов не являются критическими и могут регулироваться для получения различных коэффициентов усиления и чувствительности, схема должна быть сбалансирована. Операционный усилитель
2. Пассивный ВЧ-зонд с одним выпрямителем
Полезный и простой детекторный зонд можно собрать из нескольких недорогих компонентов и выброшенного пластикового футляра для шариковой ручки. Диоды могут быть германиевыми (ОА47, ОА90 и т. д.) или Шоттки (HP2800, HP2835, BA482, 1N5711 и т. д.).
Индикатором может быть аналоговый или цифровой вольтметр с высоким импедансом или осциллограф, настроенный на постоянный ток. Обычный расходомер с подвижной катушкой не подходит из-за большого последовательного резистора. Три компонента могут быть размещены в простом экранированном корпусе с небольшими прикрепленными «выводами». Выход постоянного тока будет положительным по отношению к земле.
Выход постоянного тока будет положительным по отношению к земле.
ВЧ входное напряжение pk- | Выходное напряжение постоянного тока при нагрузке 1 Мб | ВЧ входное напряжение шт.- | Выходное напряжение постоянного тока при нагрузке 1 Мб |
680мв | 8мв | 2,3 В | 520мВ |
850мв | 20мВ | 2,55 В | 620мв |
950мв | 40мВ | 2,85 В | 750мв |
1,1 В | 70мв | 3,2 В | 900мв |
1,2 В | 120мВ | 3,6 В | 1,05 В |
1,3 В | 160мВ | 4,0 В | 1,25 В |
1,45 В | 210мв | 4,5 В | 1,42 В |
1,65 В | 270мВ | 4,8 В | 1,65 В |
1,85 В | 330мВ | 5,2 В | 1,85 В |
2,15 В | 440мв |
Вход Кол-во | Выход постоянного тока | Вход Кол-во | Выход постоянного тока |
16мв | Порог проводимости | 460мВ | 430мв |
34мв | 5мв | 800мв | 650мВ |
48мв | 9,5мВ | 1,3 В | 1,15 В |
64мв | 18мв | 1,6 В | 1,49 В |
100мВ | 39мв | 2,2 В | 2,2 В |
150мВ | 92мв | 3,2 В | 3,15 В |
220мВ | 160мВ | 4,4 В | 4,6 В |
310мв | 260мВ | 5. | 5,8 В |
 0В
0ВКак видно из таблицы выход нелинейный, особенно на низких уровнях. Это означает, что для изготовления калиброванного прибора на выходном измерителе потребуется несколько шкал.
ВЧ входное напряжение шт.- | Выходное напряжение постоянного тока при нагрузке 1 Мб | ВЧ входное напряжение шт.- | Выходное напряжение постоянного тока при нагрузке 1 Мб |
25мВ | 1мв | 800мв | 290мв |
50мВ | 5мв | 1,25 В | 410мв |
90мв | 11мв | 1,8 В | 590мв |
124мв | 20мВ | 2,8 В | 1,0 В |
195мв | 41мв | 3,9 В | 1,45 В |
360мв | 110мВ | 5,2 В | 2,15 В |
520мВ | 170мВ |
При использовании коротких проводов частотная характеристика будет плоской даже в диапазонах УКВ. Как можно видеть, на нижнем конце характеристики имеется ярко выраженная нелинейность
Как можно видеть, на нижнем конце характеристики имеется ярко выраженная нелинейность
Вышеупомянутые испытания были повторены ниже с германиевым диодом OA90:
Датчик детектора был построен с использованием этой схемы с диодом Шоттки HP 5082-
Частота МГц | Разгружен Q | Q с подключенным зондом (1 Мб) | Q с подключенным зондом (10 Мб) | Подстроечный конденсатор пФ | Емкость зонда пФ |
7,2 | 114 | 109 | 110 | 100 | 3.1 |
45 | 141 | 115 | 117 | 50 | 3,8 |
Как видно из результатов, пробник оказывает очень небольшое влияние на добротность настроенного контура на частоте 7,2 МГц, но несколько больше на частоте 45 МГц.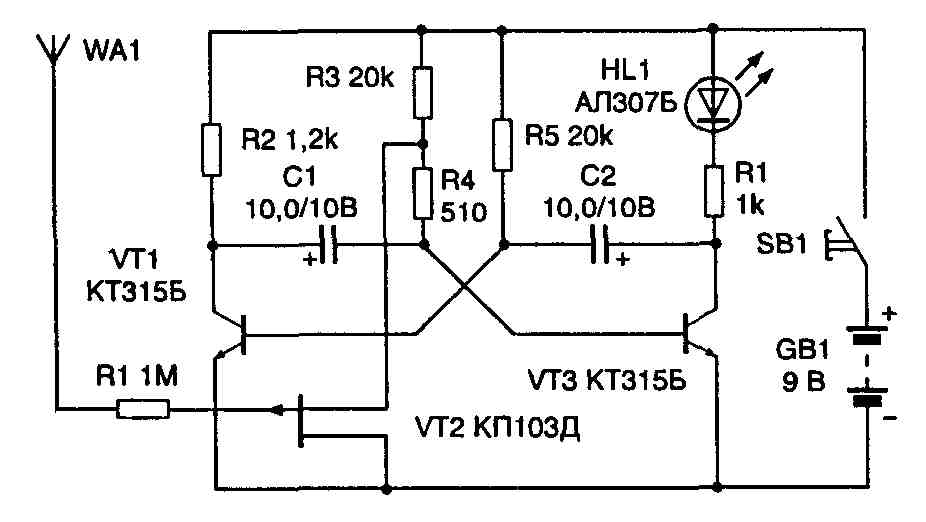 Альтернативой может быть активный зонд, использующий полупроводниковое или вентильное устройство —
Альтернативой может быть активный зонд, использующий полупроводниковое или вентильное устройство —
1. Простой пассивный РЧ-детектор
Полезный и очень простой РЧ-детектор можно собрать из нескольких недорогих компонентов и выброшенного пластикового футляра для шариковой ручки или подобного предмета. Германиевые диоды (ОА47, ОА90, 1N191 и т.д.) дадут наилучшую чувствительность. Индикатор может быть обычным тестовым измерителем, а выход постоянного тока будет положительным по отношению к земле.
Металлоискатель Simplex+ — Nokta Detectors
 jpg»>
jpg»>Характеристики
ПРОСТО НЕПРЕВЗОЙДЕННЫЙ
ПЕРВЫЙ ВОДОНЕПРОНИЦАЕМЫЙ ДЕТЕКТОР НА РЫНКЕ, ПРЕДЛАГАЮЩИЙ ЧРЕЗВЫЧАЙНУЮ ГЛУБИНУ И ВЫСОЧАЙШИЕ ФУНКЦИИ ПО НАЧАЛЬНОЙ ЦЕНЕ!
ДОСТАТОЧНО ПРОСТО ДЛЯ НАЧИНАЮЩИХ, НО ДОСТАТОЧНО ВПЕЧАТЛЯЕТ ДЛЯ ЭКСПЕРТОВ!
Вы новичок в поиске металла и вам просто нужен простой в использовании детектор?
Вы не можете позволить себе детектор высокого класса, но вам просто нужна исключительная глубина и базовые функции устройства высокого класса?
Нужен водонепроницаемый детектор по доступной цене?
Если вы ответили «да» на один из вышеперечисленных вопросов, SIMPLEX+ — единственный выбор, который охватывает все это. Мы с гордостью представляем наш первый металлоискатель начального уровня SIMPLEX+, который делает качественную металлоискатель доступной для всех пользователей.
SIMPLEX+ — детектор включения и выключения с автоматической балансировкой грунта! Он может похвастаться предустановленными режимами поиска, включая пляжный режим, в очень простом в использовании едином дизайне меню.
Независимо от того, ищете ли вы монеты, артефакты или драгоценности на суше или под водой, SIMPLEX+ — это самый экономичный, но прочный детектор, отличающийся современным и легким дизайном.
Simplex+ : 329 долл. США
Simplex+ WHP (комплект беспроводных наушников) : 439 долл. США
- IP68
Полностью погружается на глубину до 3 метров (10 футов) и защищен от полного проникновения пыли. - Iron Volume
Отключает или регулирует громкость звука низкого уровня железа. - Notch Discrimination
Различает целевые идентификаторы нежелательных металлов. - Режимы поиска
Поле / Парк 1 / Парк 2 / Пляж / Все металлы - Встроенный беспроводной модуль
, совместимый с беспроводными наушниками Nokta Green Edition 2,4 ГГц. - Вибрация
SIMPLEX+ будет вибрировать при обнаружении цели! Идеально подходит для пользователей с нарушениями слуха, а также для обнаружения под водой. - Сдвиг частоты
Легко избавиться от электромагнитных помех, изменяя частоту небольшими шагами. - Невероятное освещение для ночного и подводного использования Модель
SIMPLEX+ имеет все необходимое: подсветку ЖК-дисплея, подсветку клавиатуры и светодиодный фонарик. - Выдвижная штанга
Рукоятка убирается до 63 см (25 дюймов). Идеально подходит для транспортировки, хранения и дайвинга! - Легкий (1,3 кг / 2,9 фунта)
Хорошо сбалансированный — Наслаждайтесь поиском в течение долгих часов без усталости. - Встроенная батарея Lipo
Легко заряжайте ее с помощью зарядного устройства USB или внешнего аккумулятора. - Онлайн-обновления встроенного ПО
Будьте в курсе обновлений встроенного ПО (через USB на ПК) и максимально эффективно используйте свой металлоискатель.


Комплектация
1 — Системный блок
2 — Водонепроницаемая поисковая катушка DD 28 см / 11 дюймов (SP28) и крышка
3 — USB-кабель для зарядки и передачи данных
4 — Адаптер для наушников 6,3 мм (1/4 дюйма) — только SIMPLEX+
5 — Колпачок Simplex — SIMPLEX+ WHP Only
6–2,4 ГГц Беспроводные наушники Green Edition — SIMPLEX+ WHP Only
7 — Руководство пользователя
Поисковые катушки
Водонепроницаемая поисковая катушка DD 22 см / 8,5 дюйма (SP22)
Водонепроницаемая поисковая катушка DD 24×13 см / 9,5»x5» (SP24)
Водонепроницаемая поисковая катушка DD 28 см / 11 дюймов (SP28)
Водонепроницаемая поисковая катушка DD 35×31,5 см / 13,5»x12,5» (SP35)
Принадлежности
Крышка поисковой катушки SP22
Крышка поисковой катушки SP24
Крышка поисковой катушки SP28
Крышка поисковой катушки SP35
Подлокотник
Удлиненный средний вал (алюминий)
Средний вал
Нижний вал
Нижний вал (углеродное волокно)
Ремень подлокотника
Монтажное оборудование поисковой катушки
Защитная пленка для экрана из наностекла
USB-кабель для зарядки и передачи данных
Беспроводной модуль EZ Wander
Беспроводные наушники 2,4 ГГц (зеленая версия)
Беспроводные наушники — сменные амбушюры
Водонепроницаемые наушники
Наушники с водонепроницаемым разъемом
Адаптер для наушников (6,3 мм 1/4 дюйма)
Колпачок Simplex
Загрузки
Брошюры
| Simplex + Металлоискатель Брошюра (EN) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (ES) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (DE) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (FR) | Посмотреть | Скачать |
| Симплекс + 9Брошюра металлоискателя 1235 (DA) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (IT) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (NL) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (FI) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (PL) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (RO) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (RU) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (SK) | Вид | Скачать |
| Simplex + Металлоискатель Брошюра (GR) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (BG) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (LT) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (SQ) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (JA) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (KO) | Посмотреть | Скачать |
| Simplex + Металлоискатель Брошюра (HE) | Посмотреть | Скачать |
| Симплекс + 9Брошюра по металлодетектору 1235 (TR) | Посмотреть | Скачать |
Руководства пользователя
| Simplex + Руководство пользователя металлоискателя (EN) | Просмотр | Скачать |
| Simplex + Металлоискатель Руководство пользователя (ES) | Посмотреть | Скачать |
| Simplex + Metal Detector User Manual (DE) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (DA) | Просмотр | Скачать |
| Simplex + Металлоискатель Руководство пользователя (FR) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (ИТ) | Просмотр | Скачать |
| Симплекс + Руководство пользователя металлодетектора (FI) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (NL) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (НЕТ) | Просмотр | Скачать |
| Simplex + Металлоискатель Руководство пользователя (PT) | View | Скачать |
| Simplex + Металлоискатель Руководство пользователя (RU) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (SK) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (GR) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (KO) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (KZ) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (RO) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (LT) | Посмотреть | Скачать |
| Симплекс + Руководство пользователя металлодетектора (LV) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (SQ) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (AR) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (BG) | View | Скачать |
| Simplex + Металлоискатель Руководство пользователя (PL) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (TH) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (VI) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (ZH) | Посмотреть | Скачать |
| Simplex + Металлоискатель Руководство пользователя (TR) | Посмотреть | Скачать |
Краткое руководство
| Simplex + Краткое руководство по металлодетектору (EN) | Просмотр | Скачать |
| Simplex + Краткое руководство по металлоискателю (ES) | Просмотр | Скачать |
| Simplex + Краткое руководство по металлодетектору (DE) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлодетектору (IT) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлодетектору (FR) | Посмотреть | Скачать |
| Simplex + Металлоискатель Краткое руководство (FI) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (NL) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (NO) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлодетектору (PT) | Просмотр | Загрузка |
| Симплекс + Краткое руководство по металлодетектору (RU) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (SK) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (TH) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлоискателю (GR) | Вид | Скачать |
| Simplex + Краткое руководство по металлодетектору (KO) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (KZ) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (RO) | Просмотр | Загрузка |
| Simplex + Металлоискатель Краткое руководство (AR) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлоискателю (BG) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (DA) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлодетектору (LT) | Просмотр | Загрузка |
| Симплекс + Краткое руководство по металлодетектору (LV) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлоискателю (PL) | Посмотреть | Скачать |
| Simplex + Краткое руководство по металлодетектору (SQ) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлоискателю (VI) | Просмотр | Скачать |
| Simplex + Краткое руководство по металлодетектору (ZH) | Просмотр | Загрузка |
| Simplex + Краткое руководство по металлодетектору (TR) | Просмотр | Загрузка |
Беспроводные наушники 2,4 ГГц
| Беспроводные наушники 2,4 ГГц Green Edition Руководство пользователя (EN) | ||
| Руководство пользователя беспроводных наушников Blue Edition 2,4 ГГц (на английском языке) |
Обновление ПО
Важно!
Операционные системы: Windows XP (с пакетом обновления 3), Vista, Windows 7, 8 или 10.
* Если у вас возникли проблемы с открытием установочного файла, отключите все антивирусные программы на вашем ПК.
Последнее обновление включает в себя все предыдущие обновления.
ВАЖНО!
SIMPLEX+ НЕ МОЖЕТ ОБРАТИТЬСЯ НА ВЕРСИИ 2.77 ИЛИ ЛЮБЫЕ ПРЕДЫДУЩИЕ ВЕРСИИ ПРОШИВКИ.
Обновление программного обеспечения (2020.06.02): Системное программное обеспечение v2.78
Скачать: Системное программное обеспечение v2.78
Обновления:
Если вы удовлетворены увеличенными идентификационными глубинами версии 2.76 или 2.77 , ВАМ НЕ НУЖНО УСТАНАВЛИВАТЬ ЭТО ОБНОВЛЕНИЕ!
Стабильность и глубина ID возвращены к тем же уровням, что и в версии 2.68. Это НЕ повлияет на общую глубину и чувствительность устройства.
Видеоруководство по обновлению программного обеспечения
Технические характеристики
| Принцип действия | VLF |
| Рабочая частота | 12 кГц |
| Режимы поиска | 5 (Поле/Парк 1/Парк 2/Пляж/Все металлы) |
| Звуковые сигналы | 3 |
| Режущий фильтр | Да |
| Точное определение | Да |
| Вибрация | Да |
| Сдвиг частоты | Да |
| Настройка чувствительности | 6 уровней |
| Идентификатор цели | 00-99 |
| Поисковая катушка | Водонепроницаемая поисковая катушка DD — 28 см / 11 дюймов (SP28) |
| Дисплей | Графический ЖК-дисплей |
| Подсветка | Да |
| Подсветка клавиатуры | Да |
| Светодиодный фонарик | Да |
| Масса | 1,3 кг (2,9 фунта), включая поисковую катушку |
| Длина | 63 см — 132 см (25″ — 52″) регулируемая |
| Батарея | Литий-полимерная батарея 2300 мАч |
| Гарантия | 2 года |
Рукоятка убирается до 63 см (25 дюймов). Идеально подходит для удобной транспортировки, хранения и погружений! любые обязательства или ответственность
Идеально подходит для удобной транспортировки, хранения и погружений! любые обязательства или ответственность
Простой детектор — документация pyFAI 0.22.0a8
Простой детектор — документация pyFAI 0.22.0a8Как и большинство других пакетов для обработки дифракции, pyFAI позволяет определять 2D-детекторы с постоянным размером пикселя и перекодированные в S.I.. Типичный размер пикселя составляет 50e-6 мкм (50 микрон) и будет использоваться в качестве примера в числовое приложение.
Пиксели детектора индексируются от начала координат , расположенного в нижний левый угол если смотреть с образца. Центр пикселя расположен в половинном целочисленном индексе:
- Пиксель 0 переходит от позиции 0 м к 50e-6m и центрируется на 25e-6 м.
- пиксель 1 переходит от позиции 50e-6 м к 100e-6 м и центрируется на 75e-6 м
Примечание :
В большинстве случаев вам нужно будет передать необязательный аргумент origin=»lower» в
Функция matplotlib imshow при отображении изображения, чтобы избежать путаницы.
Подход простого детектора достиг своих пределов с несколькими типами детекторов, такими как многомодульные и конические оптоволоконные детекторы (большинство ПЗС). Детекторы пикселей с большой площадью часто состоят из меньших модулей (например, Pilatus). от Dectris, Maxipix от ESRF, …).
По конструкции такие извещатели имеют зазоры между модулями наряду с пиксели разного размера в одном модуле, следовательно, они требуют специальных маски данных. Детекторы с оптической связью также нуждаются в корректировке. для малых пространственных смещений, часто называемых геометрическими искажениями. Вот почему детекторам нужны более сложные определения, чем просто определение пикселя. размер. Чтобы избежать сложных и подверженных ошибкам наборов параметров, были введены два инструмента: либо классы детектора определяют программно детектор, либо Nexus сохраняет настройку детектора.
Классы детекторов
Они используются для определения семейств детекторов. Чтобы учесть особенности каждого детектора, pyFAI
содержит около 58 определений классов детекторов (и 168 с псевдонимами)
которые содержат маску (недопустимые пиксели,
промежутки, …) и метод вычисления позиций пикселей в декартовом
координаты. Доступные детекторы можно распечатать, используя:
Чтобы учесть особенности каждого детектора, pyFAI
содержит около 58 определений классов детекторов (и 168 с псевдонимами)
которые содержат маску (недопустимые пиксели,
промежутки, …) и метод вычисления позиций пикселей в декартовом
координаты. Доступные детекторы можно распечатать, используя:
>>> import pyFAI >>> print(pyFAI.detectors.ALL_DETECTORS)
Для ПЗС-детекторов с оптической связью геометрические искажения часто описывается двумерным кубическим сплайном, который можно импортировать в экземпляр детектора и использоваться для вычисления фактического положения пикселя в пространстве.
Детекторы Nexus
Любой объект детектора в pyFAI можно сохранить в файл HDF5 после NeXus
конвенции (http://nexusformat.org).
Объекты детектора впоследствии могут быть восстановлены с диска, что делает
сложные определения детектора менее подвержены ошибкам.
Пиксели площадного детектора сохраняются как набор данных 4D: т.е.
массив вершин, указывающих на каждый угол каждого пикселя, генерирующий
массив формы: ( Ny , Nx , Nc , 3) где Nx и Ny — размеры
детектор, Nc — это количество углов каждого пикселя, обычно 4, и последний
запись содержит координаты самой вершины (z,y,x). Этот тип определений, опираясь на большие файлы описаний,
может работать с некоторыми из самых сложных макетов детекторов:
Этот тип определений, опираясь на большие файлы описаний,
может работать с некоторыми из самых сложных макетов детекторов:
- шестиугольных пикселей (т.е. детекторы Pixirad, все еще в разработке)
- изогнутые/изогнутые пластины для визуализации (например, Rigaku, детектор Орхуса) Детекторы
- пикселей с тайловым модульным (т.е. детекторы Xpad от ImXpad) Полуцилиндрические пиксельные детекторы
- (например, Pilatus12M от Dectris или CirPad от Soleil).
Экземпляр детектора можно сохранить как HDF5 либо программно, либо в командной строке.
из детекторов импорта pyFAI
frelon = детекторы.FReLoN("halfccd.spline")
печать (фрелон)
frelon.save("halfccd.h5")
Использование скрипта Detector2nexus для преобразования сложного определения детектора (несколько модулей, возможно, в 3D) в одно определение детектора NeXus вместе с маской:
детектор2nexus -s halfccd.spline -o halfccd.h5
Определение детектора в pyFAI очень универсально.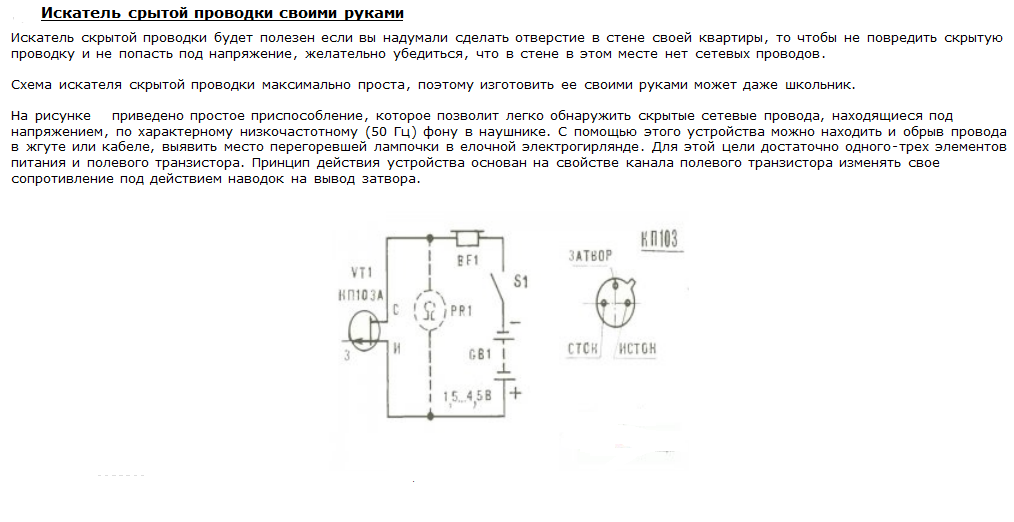 К счастью, большинство детекторов уже описаны, что делает их использование прозрачным.
для большинства пользователей.
Есть пара руководств по определению детектора, которые помогут
вы понимаете лежащий в основе механизм:
К счастью, большинство детекторов уже описаны, что делает их использование прозрачным.
для большинства пользователей.
Есть пара руководств по определению детектора, которые помогут
вы понимаете лежащий в основе механизм:
- Искажение , в котором объясняется, как исправить изображения для геометрического искажения
- Калибровка ПЗС , в которой объясняется, как калибровать такие детекторы для геометрических искажение.
Читать документы В: мастер
- Версии
- мастер
- Загрузки
- При прочтении документов
- Дом проекта
- Строит
Бесплатный хостинг документов предоставляется Read the Docs.
FCOS: простой и надежный детектор объектов без привязки
. 2022 Апрель; 44 (4): 1922-1933.
doi: 10.1109/TPAMI.2020.3032166. Epub 2022 4 марта.
Чжи Тянь, Чуньхуа Шэнь, Хао Чен, Тонг Хе
- PMID: 33074804
- DOI: 10.1109/ТПАМИ.2020.3032166
Чжи Тянь и др. IEEE Trans Pattern Anal Mach Intell. 2022 апрель
. 2022 Апрель; 44 (4): 1922-1933.
doi: 10.1109/TPAMI.2020.3032166.
Epub 2022 4 марта.
Авторы
Чжи Тянь, Чуньхуа Шен, Хао Чен, Тонг Хе
- PMID: 33074804
- DOI: 10.1109/ТПАМИ.2020.3032166
Абстрактный
В компьютерном зрении обнаружение объектов является одной из наиболее важных задач, которая лежит в основе нескольких задач распознавания на уровне экземпляра и многих последующих приложений. В последнее время одноэтапные методы привлекли больше внимания по сравнению с двухэтапными из-за их более простой конструкции и конкурентоспособных характеристик. Здесь мы предлагаем полностью сверточный одноэтапный детектор объектов (FCOS) для решения задачи обнаружения объектов в режиме попиксельного прогнозирования, аналогичного другим задачам плотного прогнозирования, таким как семантическая сегментация. Почти все современные детекторы объектов, такие как RetinaNet, SSD, YOLOv3 и Faster R-CNN, полагаются на предварительно определенные поля привязки. Напротив, предлагаемый нами детектор FCOS не содержит ни якорной коробки, ни предложений. Устраняя предопределенный набор полей привязки, FCOS полностью избегает сложных вычислений, связанных с блоками привязки, таких как вычисление показателей пересечения по объединению (IoU) во время обучения. Что еще более важно, мы также избегаем всех гиперпараметров, связанных с блоками привязки, которые часто чувствительны к окончательной производительности обнаружения. С единственным немаксимальным подавлением постобработки (NMS) мы демонстрируем гораздо более простую и гибкую структуру обнаружения, обеспечивающую повышенную точность обнаружения. Мы надеемся, что предлагаемая структура FCOS может служить простой и надежной альтернативой для многих других задач уровня экземпляра. Код доступен по адресу: git.io/AdelaiDet.
Почти все современные детекторы объектов, такие как RetinaNet, SSD, YOLOv3 и Faster R-CNN, полагаются на предварительно определенные поля привязки. Напротив, предлагаемый нами детектор FCOS не содержит ни якорной коробки, ни предложений. Устраняя предопределенный набор полей привязки, FCOS полностью избегает сложных вычислений, связанных с блоками привязки, таких как вычисление показателей пересечения по объединению (IoU) во время обучения. Что еще более важно, мы также избегаем всех гиперпараметров, связанных с блоками привязки, которые часто чувствительны к окончательной производительности обнаружения. С единственным немаксимальным подавлением постобработки (NMS) мы демонстрируем гораздо более простую и гибкую структуру обнаружения, обеспечивающую повышенную точность обнаружения. Мы надеемся, что предлагаемая структура FCOS может служить простой и надежной альтернативой для многих других задач уровня экземпляра. Код доступен по адресу: git.io/AdelaiDet.
Похожие статьи
SOLO: простая структура для сегментации экземпляров.
Ван С, Чжан Р, Шен С, Конг Т, Ли Л. Ван Х и др. IEEE Trans Pattern Anal Mach Intell. 2021, 13 сентября; стр. doi: 10.1109/ТПАМИ.2021.3111116. Онлайн перед печатью. IEEE Trans Pattern Anal Mach Intell. 2021. PMID: 34516372
Одноэтапное трехмерное обнаружение транспортных средств без привязки с помощью датчиков LiDAR.
Ли Х., Чжао С., Чжао В., Чжан Л., Шен Дж. Ли Х и др. Датчики (Базель). 2021 9 апреля; 21 (8): 2651. дои: 10.3390/s21082651. Датчики (Базель). 2021. PMID: 332 Бесплатная статья ЧВК.
SAFNet: сеть без привязки с пирамидой расширенных функций для обнаружения объектов.
Джин Зи, Лю Б, Чу Кью, Ю Н. Джин Зи и др. Процесс преобразования изображений IEEE.
2020 7 октября; ПП. дои: 10.1109/TIP.2020.3028196. Онлайн перед печатью.
Процесс преобразования изображений IEEE. 2020.
PMID: 33026987PolarMask++: улучшенное полярное представление для сегментации единичных экземпляров и не только.
Се Э., Ван В., Дин М., Чжан Р., Луо П. Се Э. и др. IEEE Trans Pattern Anal Mach Intell. 2021 14 мая; пп. doi: 10.1109/TPAMI.2021.3080324. Онлайн перед печатью. IEEE Trans Pattern Anal Mach Intell. 2021. PMID: 33989151
Улучшенный FCOS для обнаружения рака молочной железы.
Ван И, Линь С, Чжан С, Е К, Чжоу Х, Чжан Р, Гэ С, Сунь Д, Юань К. Ван Ю и др. Curr Med Imaging. 2022;18(12):1291-1301. дои: 10.2174/15734056186662204200. Curr Med Imaging. 2022. PMID: 35450530

 2020 7 октября; ПП. дои: 10.1109/TIP.2020.3028196. Онлайн перед печатью.
Процесс преобразования изображений IEEE. 2020.
PMID: 33026987
2020 7 октября; ПП. дои: 10.1109/TIP.2020.3028196. Онлайн перед печатью.
Процесс преобразования изображений IEEE. 2020.
PMID: 33026987Посмотреть все похожие статьи
Цитируется
Обнаружение эндотрахеальной трубки и киля на портативных рентгенограммах грудной клетки в положении лежа с использованием одноступенчатого детектора с вниманием от грубого к тонкому.
Мао Л.К., Хуан М.Х., Лай Ч., Сунь Ю.Н., Чен С.И. Мао Л.К. и др. Диагностика (Базель). 2022 7 августа; 12 (8): 1913. doi: 10.3390/диагностика12081913. Диагностика (Базель). 2022. PMID: 36010263 Бесплатная статья ЧВК.
DetectFormer: Преобразователь с поддержкой категорий для обнаружения объектов дорожного движения.
Лян Т., Бао Х., Пань В., Фан Х., Ли Х. Лян Т. и др. Датчики (Базель). 2022 26 июня; 22 (13): 4833. дои: 10.3390/s22134833. Датчики (Базель). 2022. PMID: 35808332 Бесплатная статья ЧВК.
MSFT-YOLO: Улучшенный YOLOv5 на основе трансформатора для обнаружения дефектов поверхности стали.
Го З., Ван С., Ян Г., Хуан З., Ли Г. Го Зи и др. Датчики (Базель).
2022 2 мая; 22(9)):3467. дои: 10.3390/s22093467.
Датчики (Базель). 2022.
PMID: 355
Бесплатная статья ЧВК.Автоматическое выявление вторичного дефекта межпредсердной перегородки у детей на основе цветных допплеровских эхокардиографических изображений с использованием сверточных нейронных сетей.
Хун В., Шэн Ц., Донг Б., Ву Л., Чен Л., Чжао Л., Лю Ю., Чжу Дж., Лю Ю., Се Ю., Ю.И., Ван Х., Юань Дж., Гэ Т., Чжао Л., Лю Х, Чжан Ю. Хонг В. и др. Front Cardiovasc Med. 2022 6 апр; 9:834285. doi: 10.3389/fcvm.2022.834285. Электронная коллекция 2022. Front Cardiovasc Med. 2022. PMID: 35463790 Бесплатная статья ЧВК.
Сети динамического преобразования цвета для обнаружения колосьев пшеницы.
Лю С., Ван К.

 2022 2 мая; 22(9)):3467. дои: 10.3390/s22093467.
Датчики (Базель). 2022.
PMID: 355
2022 2 мая; 22(9)):3467. дои: 10.3390/s22093467.
Датчики (Базель). 2022.
PMID: 355